







 本文介绍了一个使用Python3编写的简单爬虫Demo,用于抓取Bing搜索引擎的每日高清桌面壁纸。通过请求Bing接口,解析网页源码获取图片URL,然后下载并保存到本地。
本文介绍了一个使用Python3编写的简单爬虫Demo,用于抓取Bing搜索引擎的每日高清桌面壁纸。通过请求Bing接口,解析网页源码获取图片URL,然后下载并保存到本地。
引言
看到 bing 的高清大图,觉得质量都很高,都挺好看的,升到 window 10 以后,每次开机的画面都不一样,也觉得很有特点,我们来做一个简单的抓图 Demo 版脚本。
版权所有:_ OE _, 转载请注明出处:http://blog.csdn.net/csnd_ayo
简介
操作系统: window 10
编程环境:Python 3.6.1
编程IDE:PyCharm
bing 接口
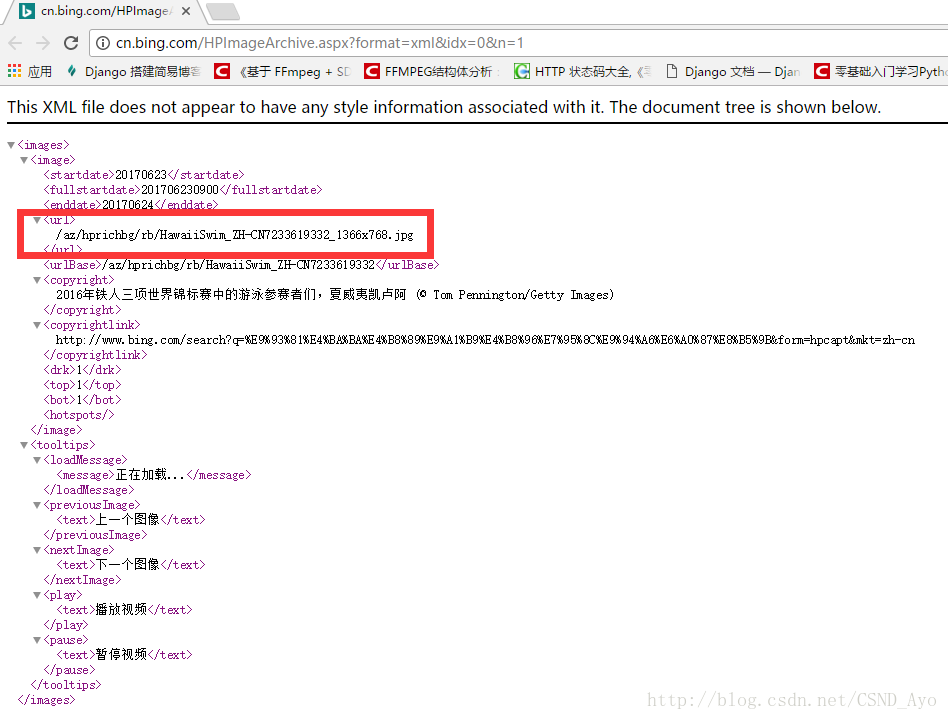
首先来介绍一下,我通过请求 bing 搜索引擎的时候,截取到的一个 http 请求接口。
/*
* @param : format 返回的格式, js(json),xml
* @param : idx 图片下标
* @param : n 图片数量
* /
原请求:http://cn.bing.com/HPImageArchive.aspx?format=js&idx=0&n=1&nc=0&pid=hp&video=1
分析后:http://cn.bing.com/HPImageArchive.aspx?format=xml&idx=0&n=1
/*
* 可以通过截取xml的url部分与bing官网进行拼接,已达到获取高清图片的目的。
* 例如:http://www.bing.com/az/hprichbg/rb/Dipper_ZH-CN11205462091_1366x768.jpg
* 后缀的分辨率可以改成常用的显示屏分辨率,已达到修改照片分辨率的目的。
* 例如:http://www.bing.com/az/hprichbg/rb/Dipper_ZH-CN11205462091_1920*1080.jpg
*/ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









