







 文章介绍了观远BI的产品特点,包括前后端数据交互结构,性能对比,查询优化策略,如简化交叉行逻辑、拆分SQL和中间结果缓存。此外,提到了SmartETL在数据清洗和轻应用中的价值,以及导出和预警功能的现状。
文章介绍了观远BI的产品特点,包括前后端数据交互结构,性能对比,查询优化策略,如简化交叉行逻辑、拆分SQL和中间结果缓存。此外,提到了SmartETL在数据清洗和轻应用中的价值,以及导出和预警功能的现状。
1.背景
最近开始参与公司BI产品的开发,因为是数据产品,所以产品的优化可以参考其他大厂怎么实现的,取其精华。因此,有幸参与到其中的BI产品调研中。
我们主要调研了以下几个厂商的BI产品(当然,主要是针对后端视角):
- 观远调研
- BDP调研
- DataWind 调研(字节)
- QuickBI 调研(阿里)
- 帆软 BI 调研
- sugar BI(百度)
我主要负责观远BI的调研,下面主要介绍观远BI的一些调研。
2. 前后端数据交互的数据结构
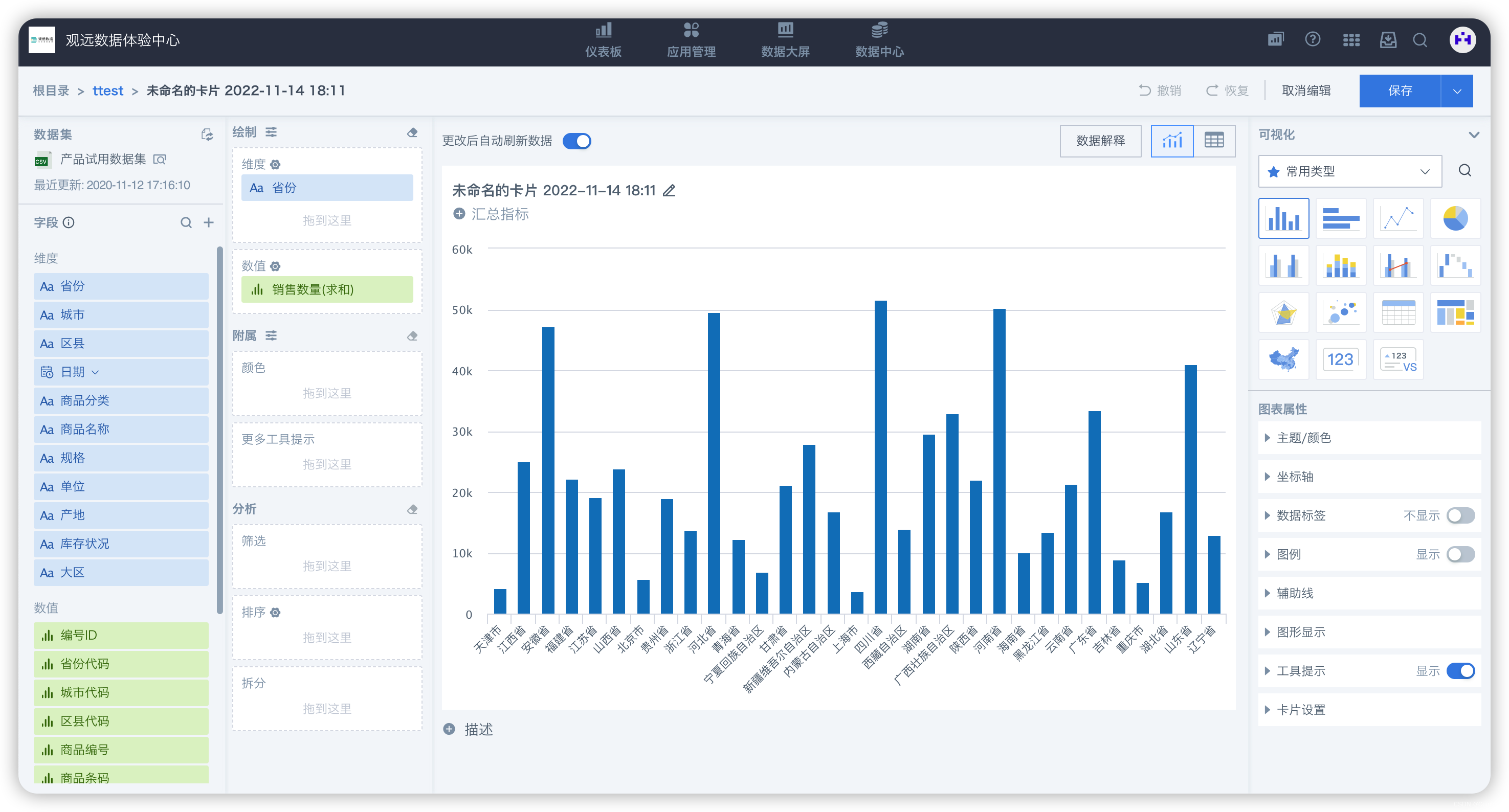
请求格式:
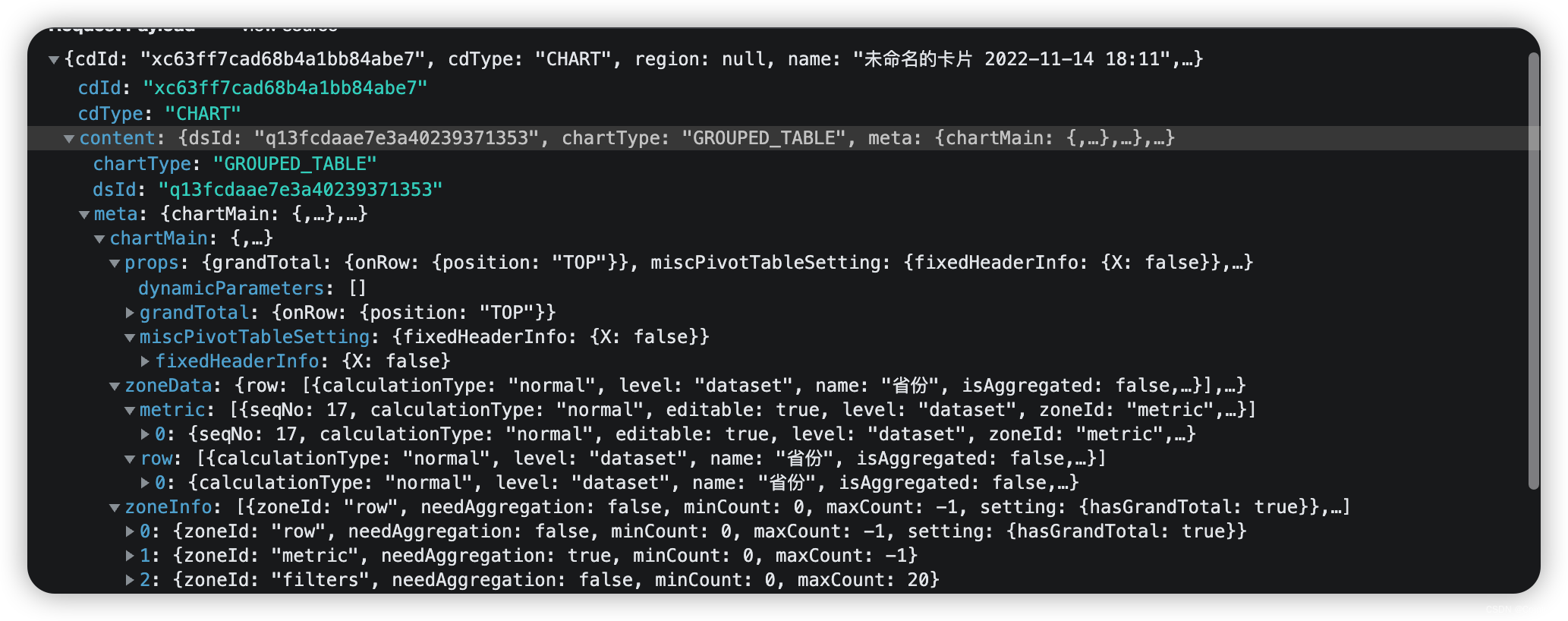
响应格式:

- 观远的维度列、对比列、数值列的返回值是分离的
前端:可能更利于前端的数据加工和展示,如维度列和对比列的自定义排序、维度列的单元格下钻;
后端:可能更利于分层、并行处理及缓存的分级; - 图形和表格混合展示方式,具备很好的多维度数据结果展示能力;
- 观远的不足:
- 在其高级算子的同环比和自定义同环比存在时,小计和总计没有返回数据,有意为之?
- 总计对应 我们BI 的数值小计,小计对应 HBI的分类小计和行总计,不支持我们BI 的分列小计和列总计;
- 聚合函数计算宇段的列总计的计算值的定义不明确,没有直接设置的路径;
3.查询性能对比
1)无交叉行的普通查询性能对比
- 10w 数据,一个维度,一个数值,0.65秒。
- 10w数据,三个维度,四个数值,0.80秒。
2)有交叉行的普通查询性能对比
- 10w数据,三个维度,两个对比,四个数值,1.2秒。
- 10w数据,三个维度,两个对比,四个数值,两个高级算子,日同比和周同比,3秒。
3)总结
无交叉行的场景下,观远的性能优势并不明显;但是有交叉行时,其性能相对明显,为此我们可以做如下优化:
- 交叉行的取值逻辑在现有的基础上可以进行简化,性能也会有明显的提升,目前是多执行了一次查询,两次查询有计算资源重复浪费的问题
- 拆分现有的大 sql 为独立子功能 sql,便于维护的同时,也可以并行处理,性能也能有一定的提升;
- 目前是对最终结果进行缓存处理,可以考虑对中间结果进行缓存;
4.上传和下载
基本相似,支持多种数据源
5.订阅与预警
- 订阅: 支持卡片订阅、合并订阅、页面订阅、数据集订阅
- 预警: 支持卡片预警、数据集预警
- 图表导出、保存:观远做的并不好,会存在图表错乱情况
调研了其他厂商的导出图片功能,比较好的是百度的Sugar。
猜测原理:前端依次导出多个子图表,最终组合成一个大的页面,好处是非常清晰,缺点是耗费客户端资源
6.Smart ETL
- 什么是smart ETL?
智能ETL作用在数据接入与可视化分析的中间处理过程,通过拖拉拽方式操作,整理与融合数据.
实际上是将传统的数仓人员通过编写代码的ETL过程,转换到通过拖拉拽的方式开放给用户。
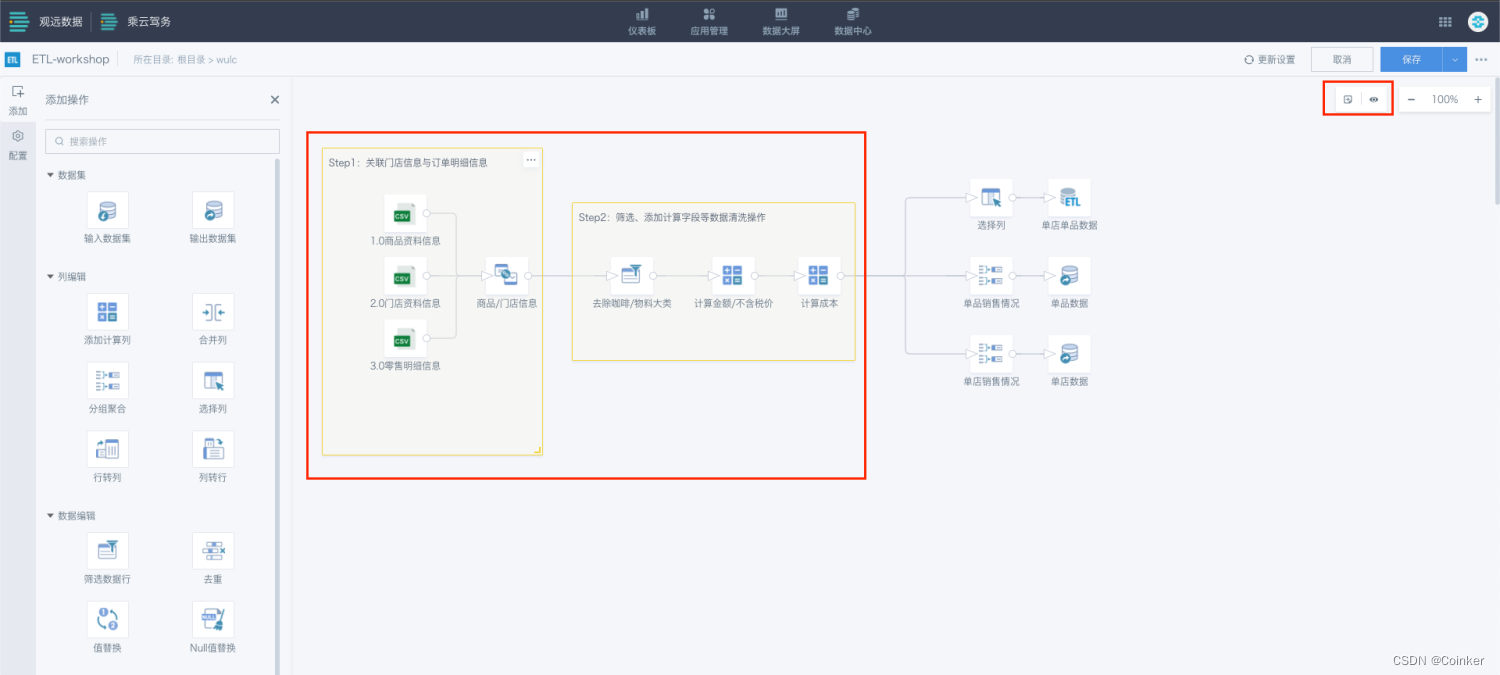
-
价值亮点:数据流任意节点均可输出,实时保存,实时预览,有助于快速定位数据问题;应对零售数据质量基础差的数据清洗神器,也为未来算法应用的数据清洗奠定基础;允许一个输出的数据集可以作为下一个数据处理流的输入数据源,分层建模呈模块化、规则明确,可搭建企业轻型数仓。
-
场景案例:适合各类验证、校对等数据处理工作。无需数据分析技术基础,普通业务人员通过拖拉拽的方式就能高效完成数据准备工作。
7.轻应用与数据门户
无大差别
8.其他
- 支持国际化
- 支持图表格式刷
- 支持表格、图表混合展示
- 支持分析结果的存储,能将大小化小表,大数据量下优化明显。类似我们的物化。
- 数据集和图表场景无缝衔接
- 能实现行列权限控制

















 1959
1959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









