







 本文介绍了SAS软件中LAG函数的使用方法,包括如何计算观测值间的差异、如何利用RETAIN语句保存变量值,以及如何使用PROCMEANS创建汇总数据集等高级应用技巧。
本文介绍了SAS软件中LAG函数的使用方法,包括如何计算观测值间的差异、如何利用RETAIN语句保存变量值,以及如何使用PROCMEANS创建汇总数据集等高级应用技巧。
1.lag函数
LAG函数返回上次执行时的自变量值,而不是上一个观测值,下面例子能说明这个特点:
DATA LAGGARD;
INPUT X;
IF X GT 5 THEN LAG_X=LAG(X);
DATALINES;
7
9
1
8
;
PROC PRINT DATA=LAGGARD;
ID X;
TITLE "Demonstrating a Feature of the AGE Function";
run;
在观测值X为7时,if条件为真,执行LAG函数并且返回一个缺失值。在观测值x为9时,if真,返回上一次LAG函数运行时的X值7。在观测值x为1时,if为假,返回缺失值。在x为8时,if为真,返回LAG上一次运行值9。
2.计算 来访者在来访时心率和血压的差异(patients数据集在笔记(五)里有建立)
函数DIF(x)等于x-lag(x)
DATA DIFFERENCE;
SET PATIENTS;
BY ID;
DIFF_HR=DIF(HR);
DIFF_SBP=DIF(SBP);
DIFF_DBP=DIF(DBP);
IF NOT FIRST.ID THEN OUTPUT; *不输出每个患者第一次来访的观测值,因为没有差异可以计算;
RUN;3.计算每个被试第一次和最近一次来访的差异
如果要知道每个患者第一次来访和最近一次来访心率和血压之差,需要找到一种方法记住上一次观测的数值。sas语句中的RETAIN语句能告诉sas,在data步骤循环时,将某个值设定为保留变量,程序会保留这个数值,直到你改变它。
DATA FIRST_LAST;
SET PATIENTS;
BY ID;
RETAIN FIRST_HR FIRST_SBP FIRST_DBP;*retain语句,保存着三个变量;
IF FIRST.ID AND LAST.ID THEN DELETE; *将只来了一次的患者信息删除;
IF FIRST.ID THEN DO;
FIRST_HR=HR;
FIRST_SBP=SBP;
FIRST_DBP=DBP;
END;
IF LAST.ID THEN DO;
D_HR=HR-FIRST_HR;
D_SBP=SBP- FIRST_SBP;
D_DBP=DBP-FIRST_DBP;
OUTPUT;
END;
RUN;
加了output语句的print输出结果:

不加output的print输出结果:

还可以用这样的程序解决上面的问题:
DATA FIRST_LAST;
SET PATIENTS;
BY ID;
IF FIRST.ID AND LAST.ID THEN DELETE;*删除只有一次记录的患者信息;
IF FIRST.ID OR LAST.ID THEN DO;
D_HR=HR-LAG(HR);
D_SBP=SBP-LAG(SBP);
D_DBP=DBP-LAG(DBP);
END;
IF LAST.ID THEN OUTPUT;
RUN;4.用PROC MEANS和PROC SUMMARY创建汇总数据集
PROC MEANS和PROC SUMMARY(添加了NOPRINT选项的PROC MEANS过程,和PROC SUMMARY过程完全一致)不仅可以通过CLASS(或BY)变量进行不同分类的描述统计,还能够用描述统计的结果创建新的数据集。比如,某个研究收集了关于学生的原始数据,但是处于比较教师的目的,你想将班级平均数作为观测的单位。或者原始数据是按天为单位收集的,当需要得到每个季度的销售额。
下面收集了许多学生的数据,包括学生编号、性别、教师姓名、教师年龄、前后两次测验成绩:
DATA SCHOOL;
LENGTH GENDER $1 TEACHER $5;
INPUT SUBJECT
GENDER $
TEACHER $
T_AGE
PRETEST
POSTTEST;
GAIN=POSTTEST-PRETEST;
DATALINES;
1 M JONES 35 67 81
2 F JONES 35 98 86
3 M JONES 35 52 92
4 M BLACK 42 41 74
5 F BLACK 42 46 76
6 M SMITH 68 38 80
7 M SMITH 68 49 71
8 F SMITH 68 38 63
9 M HAYES 23 71 72
10 F HAYES 23 46 92
11 M HAYES 23 70 90
12 F WONG 47 49 64
13 M WONG 47 50 63
;
PROC MEANS DATA=SCHOOL N MEAN STD MAXDEC=2;
TITLE "Means Scores for Each Teacher";
CLASS TEACHER;
VAR PRETEST POSTTEST GAIN;
RUN;
结果输出如下:

PROC MEANS DATA=SCHOOL NOPRINT NWAY;*NOPRINT告诉程序不要输出这个过程的结果;
CLASS TEACHER;
VAR PRETEST POSTTEST GAIN;
OUTPUT OUT=TEACHSUM
MEAN=M_PRE M_POST M_GAIN;
RUN;
NOPRINT是告诉程序不要输出proc means这个过程,NWAY告诉程序在新的数据集中只呈现每个教师的结果,而不显示总体均值。

如果要在教师年龄纳入新的数据集,可以在proc means过程中使用ID语句:
PROC MEANS DATA=SCHOOL NOPRINT NWAY;*NOPRINT告诉程序不要输出这个过程的结果;
CLASS TEACHER;
ID T_AGE;
VAR PRETEST POSTTEST GAIN;
OUTPUT OUT=TEACHSUM
MEAN=M_PRE M_POST M_GAIN;
RUN;5.解释分组后的_TYPE_含义
_TYPE_是表示二进制,运用一个sas数据集来说明:
DATA DEMOG;
LENGTH GENDER $ 1 REGION $ 5;
INPUT SUBJ GENDER $ REGION $ HEIGHT WEIGHT;
DATALINES;
01 M North 70 200
02 M North 72 220
03 M South 68 155
04 M South 74 210
05 F North 68 130
06 F North 63 110
07 F South 65 140
08 F South 64 108
09 F South . 220
10 F South 67 130
;
PROC MEANS DATA=DEMOG N MEAN STD MAXDEC=2;
TITLE "OUTPUT FROM PROC MEANS";
CLASS GENDER REGION;
VAR HEIGHT WEIGHT;
RUN;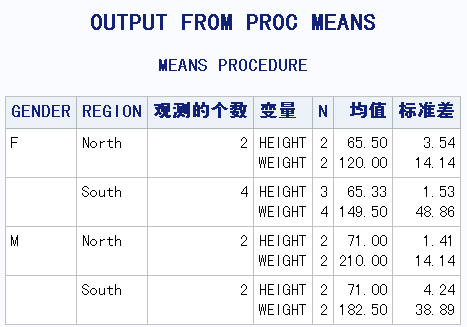
使用PROC MEANS过程创建输出数据集:
PROC MEANS DATA=DEMOG NOPRINT;
CLASS GENDER REGION;
VAR HEIGHT WEIGHT;
OUTPUT OUT=SUMMARY
MEAN=M_HEIGHT M_WEIGHT;
RUN;
PROC PRINT DATA=SUMMARY;
TITLE "Listing of Data Set SUMMARY";
RUN;

当_TYPE_为0时,表示的是所有未缺失值的总平均值;_TYPE_为1时,分别表示在每个REGION水平上HEIGHT 和weight的平均数;_TYPE_为2时,表示在每个GENDER水平下的平均值,_TYPE_为3时,分别表示每个GENDER和REGION水平结合上的平均数。
| 二进制数 | _TYPE_ | 解释 | |
| 0 | 0 | 0 | 总平均数 |
| 0 | 1 | 1 | 不同REGION的平均数 |
| 1 | 0 | 2 | 不同GENDER的平均数 |
| 1 | 1 | 3 | 单元格平均数 |
6.使用NWAY选项
如果在PROC MEANS语句中使用了NWAY选项,那就只有单元格平均数会被输出到新的数据集中,即_type_里的第3组;
如果想要知道用于计算统计量的数据中未缺失的观测值的数量,则需要在创建数据集时使用关键词“N=”;
最后,如果使用了NWAY就没有必要在输出的数据集中保留_type_,可以使用数据集选项DROP=舍弃这些变量。
PROC MEANS DATA=DEMOG NOPRINT NWAY;
CLASS GENDER REGION;
VAR HEIGHT WEIGHT;
OUTPUT OUT=SUMMARY(DROP=_TYPR_);
N=N_HEIGHT N_WEIGHT;
MEAN=M_HEIGHT M_WEIGHT;
RUN;
7.一道题目
已有BLOOD数据集,其中每个观测值包含ID/GROUP/TIME/WBC/RBC这5个变量:
DATA BLOOD;
LENGTH GROUP $ 1;
INPUT ID GROUP $ TIME WBC RBC @@;
DATALINES;
1 A 1 8000 4.5 1 A 2 8200 4.8 1 A 3 8400 5.2
1 A 4 8300 5.3 1 A 5 8400 5.5
2 A 1 7800 4.9 2 A 2 7900 5.0
3 B 1 8200 5.4 3 B 2 8300 5.4 3 B 3 8300 5.2
3 B 4 8200 4.9 3 B 5 8300 5.0
4 B 1 8600 5.5
5 A 1 7900 5.2 5 A 2 8000 5.2 5 A 3 8200 5.4
5 A 4 8400 5.5
;
分析:可使用带有CLASS语句的PROC MEANS过程。由于我们要在数据中包含ID、GROUP ,可以把它们都作为CLASS变量或者使用ID语句(ID GROUP)。同时_FREQ_变量由MEANS过程创建,改变量在删除原始数据中观测值小于或者等于2的被试有重要作用。
PROC MEANS DATA=BLOOD NOPRINT NWAY;
CLASS ID GROUP;
VAR WBC RBC;
OUTPUT OUT=NEW(WHERE=(_FREQ_ GT 2)
DROP= _TYPE_)
MEAN=M_WBC M_RBC;
RUN;

















 7544
7544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









