







文章: http://arxiv.org/abs/1506.01497
源码:https://github.com/ShaoqingRen/faster_rcnn
目录:
- Region Proposal Networks
- Translation-Invariant Anchors
- A Loss Function for Learning Region Proposals
- Optimization
- Sharing Convolutional Features for Region Proposal and Object Detection
- Implementation Details
- Experiments
- Conclusion
首先,回顾下Fast R-CNN,与传统CNN不同的是,Fast R-CNN将图片送入网络时同时将multiple regions of interest (RoIs) 也送入网络,每一个RoI被pooled到一个固定大小的feature map,然后通过全连接将其映射到一个特征向量。每个RoI最终得到两个输出向量softmax probabilities 和 per-class bounding-box regression offsets。
Faster R-CNN 可以看做是对 Fast R-CNN 的进一步加速,最主要解决的如何快速获得 proposal,一般的做法都是利用显著性目标检测(如Selective search)过一遍待检测图,得到proposal。基于区域的深度卷积网络虽然使用了 GPU 进行加速,但是the region proposal methods 确却都是在 CPU上实现的,这就大大地拖慢了整个系统的速度。然后作者提出,卷积后的特征图同样也是可以用来生成 region proposals 的。通过增加两个卷积层来实现 Region Proposal Networks (RPNs) , 一个用来将每个特征图 的位置编码成一个向量,另一个则是对每一个位置输出一个 objectness score 和 regressed bounds for k region proposals。
RPNs 是一种 fully-convolutional network (FCN),为了与 Fast R-CNN 相结合,作者给出了一种简单的训练方法:固定 proposal, 为生成 proposal 和 目标检测 这两个task 交替微调网络 。
Region Proposal Networks
RPNs 从任意尺寸的图片中得到一系列的带有 objectness score 的 object proposals。具体流程是:使用一个小的网络在最后卷积得到的特征图上进行滑动扫描,这个滑动的网络每次与特征图上n*n 的窗口全连接,然后映射到一个低维向量,例如256D或512D, 最后将这个低维向量送入到两个全连接层,即box回归层(box-regression layer (reg))和box分类层(box-regression layer (reg))。
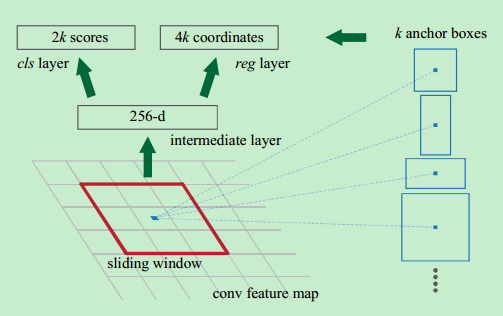
Translation-Invariant Anchors
- 原始图片经过CNN,得到最后的卷积特征。
- 利用3×3的矩形进行扫描,得到256维的向量(相当于再添加了一个卷积层,卷积核为3×3,输出特征数为256) 。
- 3×3的特征层映射到最初图片,是一块比较大的固定区域,在此固定区域上进行长宽变形,比如分别3个缩放级别,则一共有9个不同的矩形区域,称做anchor box。9就是上图中的k值。
- 对上图中的k个anchor box进行是否是物体判断预测,和矩形框位置与大小微调
- 选出物体框后,再利用同Fast RCNN同样的方式,对物体类别进行判断
这里作者说的平移不变性,其实就是以窗口中心进行多个尺度、宽高比的采样。如上图右边,文中使用了3 scales and 3 aspect ratios (1:1,1:2,2:1), 就产生了 k = 9 anchors at each sliding position.
A Loss Function for Learning Region Proposals
作者将 anchors 分为两类:与 ground-truth box 有较高的 IoU 或 与任意一个 ground-truth box 的 IoU 大于0.7 的 anchor 都标为 positive label; 与 所有 ground-truth box 的IoU 都小于0.3的 anchor 都标为 negative label。其余非正非负的都被丢掉。
对于每一个 anchor box i, 其 loss function 定义为:
L(pi,ti)=Lcls(pi,p∗i)+λp∗iLreg(ti,t∗i)
其中,
pi
是预测其是一个 object 的 probability ,当其label 为 positive 时,
p∗i
为1,否则为0。
ti={tx,ty,tw,th}
是预测的 bounding box,
t∗i
是与这个 anchor 相对应的 ground-truth box 。 classification loss
Lcls
是一个二分类(是或者不是object)的 softmax loss 。regression loss
Lreg(ti,t∗i)=R(ti−t∗i)
,
R
是 Fast R-CNN 中定义的 robust loss function (smooth-L1) ,
p∗iLreg
表示只针对 positive anchors (
p∗i
= 1). 这里还有一个平衡因子
λ
, 文中设为10,表示更倾向于box location。
Optimization
使用 back-propagation and stochastic gradient descent (SGD) 对这个RPN进行训练,每张图片随机采样了256个 anchors , 这里作者认为如果使用所有的anchors来训练的话,this will bias towards negative samples as they are dominate。所以这里作者将采样的正负positive and negative anchors have a ratio of 1:1.
新增的两层使用高斯来初始化,其余使用 ImageNet 的 model 初始化。详见论文。
Sharing Convolutional Features for Region Proposal and Object Detection**
通过交替优化来学习共享的特征,主要有4步:
- 1. 使用前面的方法训练一个RPN。用 ImageNet 的 model 初始化,然后针对 region proposal task 进行微调。
- 2. 利用第一步得到的 proposals 使用 Fast R-CNN 来训练另一一个单独的 detection network, 到这里两个网络还是分开的,没有 share conv layers 。
- 3. 利用第二部训练好的 detection network 来初始化 RPN , 然后训练,这里训练的时候固定 conv layers ,只微调 RPN 那一部分的网络层。
- 4. 再固定 conv layers ,只微调 Fast R-CNN 的 fc 层。
Implementation Details
每个 anchor , 使用 3 scales with box areas of 1282 , 2562 , and 5122 pixels, and 3 aspect ratios of 1:1, 1:2, and 2:1. 忽略了所有的 cross-boundary anchors 。在 proposal regions 上根据 cls scores 进行了 nonmaximum suppression (NMS) 。其余详见论文。















 1861
1861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









