







项目网址:http://koen.me/research/selectivesearch/
一句话概括,用了segmentation和grouping的方法来进行object proposal,然后用了一个SVM进行物体识别。
What is an object?

如何判别哪些region属于同一个物体?这个问题找不到一个统计的答案:
- 对于图b,我们可以根据颜色来分开两只猫,但是不能根据纹理来分开。
- 对于图c,我们可以根据纹理来找到变色龙,但是不能根据颜色来找到。
- 对于图d,我们将车轮归类成车的一部分,既不是因为颜色相近,也不是因为纹理相近,而是因为车轮附加在车的上面(个人理解是因为车“包裹”这车轮)
所以,我们需要用多种策略结合,才有可能找到图片中的所有物体。
另外,图a说明了物体之间可能具有的层级关系,或者说一种嵌套的关系——勺子在锅里面,锅在桌子上。
Multiscale

由于物体之间存在层级关系,所以Selective Search用到了Multiscale的思想。从上图看出,Select Search在不同尺度下能够找到不同的物体。
注意,这里说的不同尺度,不是指通过对原图片进行缩放,或者改变窗口大小的意思,而是,通过分割的方法将图片分成很多个region,并且用合并(grouping)的方法将region聚合成大的region,重复该过程直到整张图片变成一个最大的region。这个过程就能够生成multiscale的region了,而且,也符合了上面“物体之间可能具有层级关系”的假设。
Selective Search方法简介
- 使用Efficient GraphBased Image Segmentation中的方法来得到region
- 得到所有region之间两两的相似度
- 合并最像的两个region
- 重新计算新合并region与其他region的相似度
- 重复上述过程直到整张图片都聚合成一个大的region
- 使用一种随机的计分方式给每个region打分,按照分数进行ranking,取出top k的子集,就是selective search的结果
细节看下面两节。
策略多样化(Diversification Strategies)
论文作者给出了两个方面的多样化策略:颜色空间多样化,相似多样化。
颜色空间多样化
作者采用了8中不同的颜色方式,主要是为了考虑场景以及光照条件等。这个策略主要应用于【1】中图像分割算法中原始区域的生成。主要使用的颜色空间有:(1)RGB,(2)灰度I,(3)Lab,(4)rgI(归一化的rg通道加上灰度),(5)HSV,(6)rgb(归一化的RGB),(7)C(具体请看论文【2】以及【5】),(8)H(HSV的H通道)
相似度计算多样化
在区域合并的时候有说道计算区域之间的相似度,论文章介绍了四种相似度的计算方法。
(1)颜色相似度
使用L1-norm归一化获取图像每个颜色通道的25 bins的直方图,这样每个区域都可以得到一个75维的向量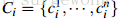
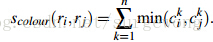
在区域合并过程中使用需要对新的区域进行计算其直方图,计算方法:
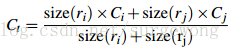
(2)纹理(texture)相似度
这里的纹理采用SIFT-Like特征。具体做法是对每个颜色通道的8个不同方向计算方差σ=1的高斯微分(GaussianDerivative),每个通道每个颜色获取10 bins的直方图(L1-norm归一化),这样就可以获取到一个240维的向量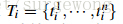

(3)大小(size)相似度
这里的大小是指区域中包含像素点的个数。使用大小的相似度计算,主要是为了尽量让小的区域先合并:
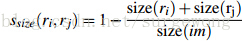
(4)吻合(fit)相似度
这里主要是为了衡量两个区域是否更加“吻合”,其指标是合并后的区域的BoundingBox(能够框住区域的最小矩形(没有旋转))越小,其吻合度越高。其计算方式:
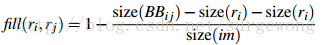
最后将上述相似度计算方式组合到一起,可以写成如下,其中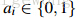
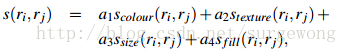
如何对region打分?
这里我不是太确定,但是按照作者描述以及个人理解,觉得确实就是随机地打分。
对于某种合并策略$j$,定义$r^{j}_{i}$为位置在$i$的region,其中i代表它在合并时候的所位于的层数(i=1表示在整个图片为一个region的那一层,往下则递增),那么定义其分数为$v^{j}_{i}=RND \times i$,其中$RND$为[0, 1]之间的一个随机值。
使用Selective Search进行Object Recogntion

大致流程如上图。用的是传统的“特征+SVM”方法:
- 特征用了HoG和BoW
- SVM用的是SVM with a histogram intersection kernel
- 训练时候:正样本:groundtruth,负样本,seletive search出来的region中overlap在20%-50%的。
- 迭代训练:一次训练结束后,选择分类时的false positive放入了负样本中,再次训练
评估(evalutation)
用数据和表格说明了文中的方法有效。
这部分写了很长,具体不表。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









