







 这篇博客总结了自然语言处理中的词形态分析,包括断词和词形还原。介绍了中文分词工具jieba和英文词形还原的重要性,探讨了正则表达式和有限状态自动机在处理词形分析中的应用,并指出深度学习与基于规则方法的互补关系。还提到了词形还原在最小编辑距离纠错中的应用局限性。
这篇博客总结了自然语言处理中的词形态分析,包括断词和词形还原。介绍了中文分词工具jieba和英文词形还原的重要性,探讨了正则表达式和有限状态自动机在处理词形分析中的应用,并指出深度学习与基于规则方法的互补关系。还提到了词形还原在最小编辑距离纠错中的应用局限性。
开始把这个学期的自然语言知识做一个归纳,记录在这个博客里。
Lexical Morphological Analysis
这个部分是关于词形态分析的内容。作为自然语言处理中首先要接触到的内容。
词形态分析包括两个部分:
1:断词 断词在汉语里面很重要,就是中文分词,我们有一个著名的jieba工具在可以很好地完成任务,我们在本学期也做了中文分词地大作业。大家基本用的都是基于统计的n元语法模型,也有的同学是用分类的思想,把词分为BESM四种类别的思想,具体的模型有SVM,神经网络。在英语里因为词之间都是用空格间隔,所以用断词用的不多。
2:词形还原: 汉语里,几乎没有词形还原,这里主要是针对英语讲的。
比如:
dogs->dog + 复数
women -> woman + 复数变化
我们之所以要做词形还原,是为了降低词的数量规模
接下来我们来谈谈我们怎么实现词形还原的任务。我们可不可以把所有词所有的表示方法都记录下来,然后遇到这个词就返回对应的还原内容,这样可不可以呢? 因为语言里面,词太多了,如果我们这么做不仅会处理时间长,而且存储容量也非常大。这样简单粗暴的方式是不可取的。
我们主要使用两种方法一种是正则表达式,另一种是有限状态自动机。
有限状态自动机的表示形式
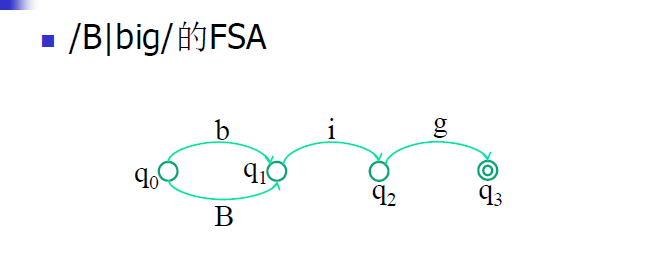
正则语言表达形式,大家如果以前编程的时候,多少都接触过,这里就不多说了。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









