





 本文介绍了如何使用Python的pandas库处理Excel文件,包括读取多张工作表,进行数据探索,计算统计信息,选择列的子集,应用公式,创建数据透视表,以及将结果导回Excel。pandas提供了强大而灵活的功能,如数据清洗、自动化处理,相比Excel更适合进行批量和复杂的数据分析操作。
本文介绍了如何使用Python的pandas库处理Excel文件,包括读取多张工作表,进行数据探索,计算统计信息,选择列的子集,应用公式,创建数据透视表,以及将结果导回Excel。pandas提供了强大而灵活的功能,如数据清洗、自动化处理,相比Excel更适合进行批量和复杂的数据分析操作。
熊猫压缩怎么使用
Excel is one of the most popular and widely-used data tools; it’s hard to find an organization that doesn’t work with it in some way. From analysts, to sales VPs, to CEOs, various professionals use Excel for both quick stats and serious data crunching.
Excel是最流行和广泛使用的数据工具之一。 很难找到一个不以某种方式与之合作的组织。 从分析师到销售副总裁,再到首席执行官,各种专业人员都使用Excel进行快速统计和严重的数据处理。
With Excel being so pervasive, data professionals must be familiar with it. You’ll also want a tool that can easily read and write Excel files — pandas is perfect for this.
随着Excel的普及,数据专业人员必须熟悉它。 您还将需要一个可以轻松读取和写入Excel文件的工具-熊猫非常适合此操作。
Pandas has excellent methods for reading all kinds of data from Excel files. You can also export your results from pandas back to Excel, if that’s preferred by your intended audience. Pandas is great for other routine data analysis tasks, such as:
熊猫具有从Excel文件读取各种数据的出色方法。 您也可以将结果从熊猫导出回Excel,如果您的目标受众更喜欢的话。 熊猫非常适合执行其他常规数据分析任务,例如:
- quick Exploratory Data Analysis (EDA)
- drawing attractive plots
- feeding data into machine learning tools like scikit-learn
- building machine learning models on your data
- taking cleaned and processed data to any number of data tools
- 快速探索性数据分析(EDA)
- 绘制有吸引力的地块
- 将数据馈送到scikit-learn等机器学习工具
- 在数据上建立机器学习模型
- 将清理和处理过的数据带入任意数量的数据工具
Pandas is better at automating data processing tasks than Excel, including processing Excel files.
Pandas在自动化数据处理任务方面比Excel更好,包括处理Excel文件。

In this tutorial, we are going to show you how to work with Excel files in pandas. We will cover the following concepts.
在本教程中,我们将向您展示如何在熊猫中使用Excel文件。 我们将介绍以下概念。
- setting up your computer with the necessary software
- reading in data from Excel files into pandas
- data exploration in pandas
- visualizing data in pandas using the matplotlib visualization library
- manipulating and reshaping data in pandas
- moving data from pandas into Excel
- 使用必要的软件设置计算机
- 将Excel文件中的数据读入熊猫
- 熊猫中的数据探索
- 使用matplotlib可视化库可视化熊猫中的数据
- 处理和重塑熊猫中的数据
- 将数据从熊猫移动到Excel
Note that this tutorial does not provide a deep dive into pandas. To explore pandas more, check out our course.
请注意,本教程并未深入探讨熊猫。 要进一步探索熊猫,请查看我们的课程 。
系统先决条件 (System prerequisites)
We will use Python 3 and Jupyter Notebook to demonstrate the code in this tutorial.In addition to Python and Jupyter Notebook, you will need the following Python modules:
在本教程中,我们将使用Python 3和Jupyter Notebook演示代码。除了Python和Jupyter Notebook外,您还需要以下Python模块:
- matplotlib – data visualization
- NumPy – numerical data functionality
- OpenPyXL – read/write Excel 2010 xlsx/xlsm files
- pandas – data import, clean-up, exploration, and analysis
- xlrd – read Excel data
- xlwt – write to Excel
- XlsxWriter – write to Excel (xlsx) files
- matplotlib –数据可视化
- NumPy –数值数据功能
- OpenPyXL –读/写Excel 2010 xlsx / xlsm文件
- 大熊猫 –数据导入,清理,探索和分析
- xlrd –读取Excel数据
- xlwt –写入Excel
- XlsxWriter –写入Excel(xlsx)文件
There are multiple ways to get set up with all the modules. We cover three of the most common scenarios below.
设置所有模块有多种方法。 我们在下面介绍三种最常见的方案。
-
If you have Python installed via Anaconda package manager, you can install the required modules using the command
conda install. For example, to install pandas, you would execute the command –conda install pandas. -
If you already have a regular, non-Anaconda Python installed on the computer, you can install the required modules using
pip. Open your command line program and execute commandpip install <module name>to install a module. You should replace<module name>with the actual name of the module you are trying to install. For example, to install pandas, you would execute command –pip install pandas. -
If you don’t have Python already installed, you should get it through the Anaconda package manager. Anaconda provides installers for Windows, Mac, and Linux Computers. If you choose the full installer, you will get all the modules you need, along with Python and pandas within a single package. This is the easiest and fastest way to get started.
如果您是通过Anaconda软件包管理器安装的Python,则可以使用
conda install命令conda install所需的模块。 例如,要安装pandas,您将执行命令–conda install pandas。如果您已经在计算机上安装了常规的非Anaconda Python,则可以使用
pip安装所需的模块。 打开命令行程序并执行命令pip install <module name>来安装模块。 您应将<module name>替换为您要安装的模块的实际名称。 例如,要安装pandas,您将执行命令–pip install pandas。如果尚未安装Python,则应通过Anaconda软件包管理器获取它。 Anaconda提供了适用于Windows,Mac和Linux计算机的安装程序。 如果选择完整的安装程序,则将在一个软件包中获得所需的所有模块以及Python和pandas。 这是最简单,最快的入门方法。
数据集 (The data set)
In this tutorial, we will use a multi-sheet Excel file we created from Kaggle’s IMDB Scores data. You can download the file here.
在本教程中,我们将使用从Kaggle的IMDB分数数据创建的多页Excel文件。 您可以在此处下载文件。
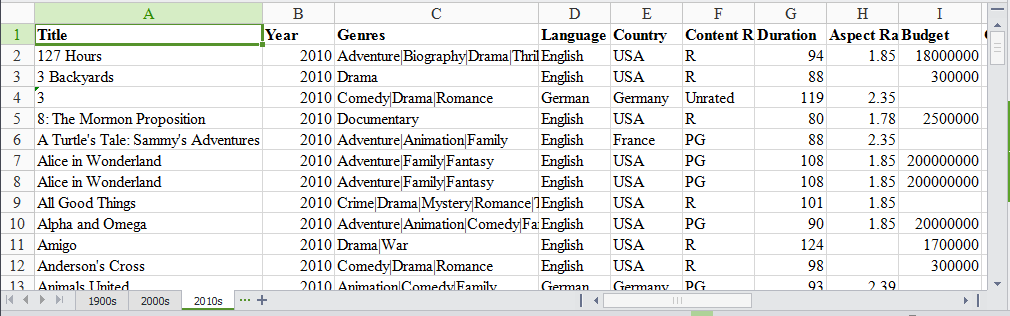
Our Excel file has three sheets: ‘1900s,’ ‘2000s,’ and ‘2010s.’ Each sheet has data for movies from those years.
我们的Excel文件分为三页:“ 1900年代”,“ 2000年代”和“ 2010年代”。 每张纸都包含这些年份的电影数据。
We will use this data set to find the ratings distribution for the movies, visualize movies with highest ratings and net earnings and calculate statistical information about the movies. We will be analyzing and exploring this data using pandas, thus demonstrating pandas capabilities to work with Excel data.
我们将使用此数据集来查找电影的收视率分布,可视化具有最高收视率和净收入的电影,并计算有关电影的统计信息。 我们将使用pandas分析和探索此数据,从而展示pandas处理Excel数据的功能。
从Excel文件中读取数据 (Read data from the Excel file)
We need to first import the data from the Excel file into pandas. To do that, we start by importing the pandas module.
我们需要首先将数据从Excel文件导入到熊猫。 为此,我们首先导入pandas模块。
import pandas as pdimport pandas as pd
We then use the pandas’ read_excel method to read in data from the Excel file. The easiest way to call this method is to pass the file name. If no sheet name is specified then it will read the first sheet in the index (as shown below).
然后,我们使用熊猫的read_excel方法从Excel文件中读取数据。 调用此方法的最简单方法是传递文件名。 如果未指定工作表名称,则它将读取索引中的第一张工作表(如下所示)。
Here, the read_excel method read the data from the Excel file into a pandas DataFrame object. Pandas defaults to storing data in DataFrames. We then stored this DataFrame into a variable called movies.
在这里, read_excel方法将数据从Excel文件读取到pandas DataFrame对象中。 熊猫默认将数据存储在DataFrames中。 然后,我们存储在该数据帧到一个变量称为movies 。
Pandas has a built-in DataFrame.head() method that we can use to easily display the first few rows of our DataFrame. If no argument is passed, it will display first five rows. If a number is passed, it will display the equal number of rows from the top.
Pandas具有内置的DataFrame.head()方法,可用于轻松显示DataFrame的前几行。 如果未传递任何参数,它将显示前五行。 如果传递了一个数字,它将从顶部开始显示相同数量的行。
movies.head()movies.head()
| Title | 标题 | Year | 年 | Genres | 体裁 | Language | 语言 | Country | 国家 | Content Rating | 内容分级 | Duration | 持续时间 | Aspect Ratio | 长宽比 | Budget | 预算 | Gross Earnings | 总收入 | … | … | Facebook Likes – Actor 1 | Facebook喜欢–演员1 | Facebook Likes – Actor 2 | Facebook喜欢–演员2 | Facebook Likes – Actor 3 | Facebook喜欢–演员3 | Facebook Likes – cast Total | Facebook点赞–总计 | Facebook likes – Movie | Facebook喜欢–电影 | Facenumber in posters | 海报中的面Kong编号 | User Votes | 用户投票 | Reviews by Users | 用户评论 | Reviews by Crtiics | Crtiics的评论 | IMDB Score | IMDB分数 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Intolerance: Love’s Struggle Throughout the Ages | 不宽容:千古以来的爱情挣扎 | 1916 | 1916年 | Drama|History|War | 戏剧|历史|战争 | NaN | N | USA | 美国 | Not Rated | 没有评分 | 123 | 123 | 1.33 | 1.33 | 385907.0 | 385907.0 | NaN | N | … | … | 436 | 436 | 22 | 22 | 9.0 | 9.0 | 481 | 481 | 691 | 691 | 1 | 1个 | 10718 | 10718 | 88 | 88 | 69.0 | 69.0 | 8.0 | 8.0 |
| 1 | 1个 | Over the Hill to the Poorhouse | 越过山到贫民窟 | 1920 | 1920年 | Crime|Drama | 犯罪|戏剧 | NaN | N | USA | 美国 | NaN | N | 110 | 110 | 1.33 | 1.33 | 100000.0 | 100000.0 | 3000000.0 | 3000000.0 | … | … | 2 | 2 | 2 | 2 | 0.0 | 0.0 | 4 | 4 | 0 | 0 | 1 | 1个 | 5 | 5 | 1 | 1个 | 1.0 | 1.0 | 4.8 | 4.8 |
| 2 | 2 | The Big Parade | 大游行 | 1925 | 1925年 | Drama|Romance|War | 戏剧|浪漫|战争 | NaN | N | USA | 美国 | Not Rated | 没有评分 | 151 | 151 | 1.33 | 1.33 | 245000.0 | 245000.0 | NaN | N | … | … | 81 | 81 | 12 | 12 | 6.0 | 6.0 | 108 | 108 | 226 | 226 | 0 | 0 | 4849 | 4849 | 45 | 45 | 48.0 | 48.0 | 8.3 | 8.3 |
| 3 | 3 | Metropolis | 都会 | 1927 | 1927年 | Drama|Sci-Fi | 戏剧|科幻 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 145 | 145 | 1.33 | 1.33 | 6000000.0 | 6000000.0 | 26435.0 | 26435.0 | … | … | 136 | 136 | 23 | 23 | 18.0 | 18.0 | 203 | 203 | 12000 | 12000 | 1 | 1个 | 111841 | 111841 | 413 | 413 | 260.0 | 260.0 | 8.3 | 8.3 |
| 4 | 4 | Pandora’s Box | 潘多拉魔盒 | 1929 | 1929年 | Crime|Drama|Romance | 犯罪|戏剧|浪漫 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 110 | 110 | 1.33 | 1.33 | NaN | N | 9950.0 | 9950.0 | … | … | 426 | 426 | 20 | 20 | 3.0 | 3.0 | 455 | 455 | 926 | 926 | 1 | 1个 | 7431 | 7431 | 84 | 84 | 71.0 | 71.0 | 8.0 | 8.0 |
5 rows × 25 columns
5行×25列
Excel files quite often have multiple sheets and the ability to read a specific sheet or all of them is very important. To make this easy, the pandas read_excel method takes an argument called sheetname that tells pandas which sheet to read in the data from. For this, you can either use the sheet name or the sheet number. Sheet numbers start with zero. If the sheetname argument is not given, it defaults to zero and pandas will import the first sheet.
Excel文件通常具有多个工作表,并且读取特定工作表或全部工作表的能力非常重要。 为了使其变得容易,pandas read_excel方法采用了一个名为sheetname的参数,该参数告诉pandas从数据中读取哪张纸。 为此,您可以使用工作表名称或工作表编号。 工作表编号从零开始。 如果未提供sheetname参数,则默认为零,熊猫将导入第一张图纸。
By default, pandas will automatically assign a numeric index or row label starting with zero. You may want to leave the default index as such if your data doesn’t have a column with unique values that can serve as a better index. In case there is a column that you feel would serve as a better index, you can override the default behavior by setting index_col property to a column. It takes a numeric value for setting a single column as index or a list of numeric values for creating a multi-index.
默认情况下,pandas将自动分配一个从零开始的数字索引或行标签。 如果您的数据没有包含唯一值的列,可以用作更好的索引,则可能需要保留默认索引。 如果您认为有一个列可以用作更好的索引,则可以通过将index_col属性设置为列来覆盖默认行为。 它使用一个数值来将单个列设置为索引,或者使用数值列表来创建一个多索引。
In the below code, we are choosing the first column, ‘Title’, as index (index=0) by passing zero to the index_col argument.
在下面的代码中,我们通过将零传递给index_col参数来选择第一列“标题”作为索引(index = 0)。
| Year | 年 | Genres | 体裁 | Language | 语言 | Country | 国家 | Content Rating | 内容分级 | Duration | 持续时间 | Aspect Ratio | 长宽比 | Budget | 预算 | Gross Earnings | 总收入 | Director | 导向器 | … | … | Facebook Likes – Actor 1 | Facebook喜欢–演员1 | Facebook Likes – Actor 2 | Facebook喜欢–演员2 | Facebook Likes – Actor 3 | Facebook喜欢–演员3 | Facebook Likes – cast Total | Facebook点赞–总计 | Facebook likes – Movie | Facebook喜欢–电影 | Facenumber in posters | 海报中的面Kong编号 | User Votes | 用户投票 | Reviews by Users | 用户评论 | Reviews by Crtiics | Crtiics的评论 | IMDB Score | IMDB分数 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Title | 标题 | ||||||||||||||||||||||||||||||||||||||||||
| Intolerance: Love’s Struggle Throughout the Ages | 不宽容:千古以来的爱情挣扎 | 1916 | 1916年 | Drama|History|War | 戏剧|历史|战争 | NaN | N | USA | 美国 | Not Rated | 没有评分 | 123 | 123 | 1.33 | 1.33 | 385907.0 | 385907.0 | NaN | N | D.W. Griffith | DW格里菲斯 | … | … | 436 | 436 | 22 | 22 | 9.0 | 9.0 | 481 | 481 | 691 | 691 | 1 | 1个 | 10718 | 10718 | 88 | 88 | 69.0 | 69.0 | 8.0 | 8.0 |
| Over the Hill to the Poorhouse | 越过山到贫民窟 | 1920 | 1920年 | Crime|Drama | 犯罪|戏剧 | NaN | N | USA | 美国 | NaN | N | 110 | 110 | 1.33 | 1.33 | 100000.0 | 100000.0 | 3000000.0 | 3000000.0 | Harry F. Millarde | 哈里·米勒德 | … | … | 2 | 2 | 2 | 2 | 0.0 | 0.0 | 4 | 4 | 0 | 0 | 1 | 1个 | 5 | 5 | 1 | 1个 | 1.0 | 1.0 | 4.8 | 4.8 |
| The Big Parade | 大游行 | 1925 | 1925年 | Drama|Romance|War | 戏剧|浪漫|战争 | NaN | N | USA | 美国 | Not Rated | 没有评分 | 151 | 151 | 1.33 | 1.33 | 245000.0 | 245000.0 | NaN | N | King Vidor | 维多尔国王 | … | … | 81 | 81 | 12 | 12 | 6.0 | 6.0 | 108 | 108 | 226 | 226 | 0 | 0 | 4849 | 4849 | 45 | 45 | 48.0 | 48.0 | 8.3 | 8.3 |
| Metropolis | 都会 | 1927 | 1927年 | Drama|Sci-Fi | 戏剧|科幻 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 145 | 145 | 1.33 | 1.33 | 6000000.0 | 6000000.0 | 26435.0 | 26435.0 | Fritz Lang | 弗里茨·朗 | … | … | 136 | 136 | 23 | 23 | 18.0 | 18.0 | 203 | 203 | 12000 | 12000 | 1 | 1个 | 111841 | 111841 | 413 | 413 | 260.0 | 260.0 | 8.3 | 8.3 |
| Pandora’s Box | 潘多拉魔盒 | 1929 | 1929年 | Crime|Drama|Romance | 犯罪|戏剧|浪漫 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 110 | 110 | 1.33 | 1.33 | NaN | N | 9950.0 | 9950.0 | Georg Wilhelm Pabst | 乔治·威廉·帕布斯特 | … | … | 426 | 426 | 20 | 20 | 3.0 | 3.0 | 455 | 455 | 926 | 926 | 1 | 1个 | 7431 | 7431 | 84 | 84 | 71.0 | 71.0 | 8.0 | 8.0 |
5 rows × 24 columns
5行×24列
As you noticed above, our Excel data file has three sheets. We already read the first sheet in a DataFrame above. Now, using the same syntax, we will read in rest of the two sheets too.
如上所述,我们的Excel数据文件分为三页。 我们已经阅读了上面的DataFrame中的第一张表。 现在,使用相同的语法,我们还将阅读其余两页。
movies_sheet2 = pd.read_excel(excel_file, sheetname=1, index_col=0) movies_sheet2.head()movies_sheet2 = pd.read_excel(excel_file, sheetname=1, index_col=0) movies_sheet2.head()
| Year | 年 | Genres | 体裁 | Language | 语言 | Country | 国家 | Content Rating | 内容分级 | Duration | 持续时间 | Aspect Ratio | 长宽比 | Budget | 预算 | Gross Earnings | 总收入 | Director | 导向器 | … | … | Facebook Likes – Actor 1 | Facebook喜欢–演员1 | Facebook Likes – Actor 2 | Facebook喜欢–演员2 | Facebook Likes – Actor 3 | Facebook喜欢–演员3 | Facebook Likes – cast Total | Facebook点赞–总计 | Facebook likes – Movie | Facebook喜欢–电影 | Facenumber in posters | 海报中的面Kong编号 | User Votes | 用户投票 | Reviews by Users | 用户评论 | Reviews by Crtiics | Crtiics的评论 | IMDB Score | IMDB分数 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Title | 标题 | ||||||||||||||||||||||||||||||||||||||||||
| 102 Dalmatians | 102只斑点狗 | 2000 | 2000 | Adventure|Comedy|Family | 冒险|喜剧|家庭 | English | 英语 | USA | 美国 | G | G | 100.0 | 100.0 | 1.85 | 1.85 | 85000000.0 | 85000000.0 | 66941559.0 | 66941559.0 | Kevin Lima | 凯文·利马 | … | … | 2000.0 | 2000.0 | 795.0 | 795.0 | 439.0 | 439.0 | 4182 | 4182 | 372 | 372 | 1 | 1个 | 26413 | 26413 | 77.0 | 77.0 | 84.0 | 84.0 | 4.8 | 4.8 |
| 28 Days | 28天 | 2000 | 2000 | Comedy|Drama | 喜剧|戏剧 | English | 英语 | USA | 美国 | PG-13 | PG-13 | 103.0 | 103.0 | 1.37 | 1.37 | 43000000.0 | 43000000.0 | 37035515.0 | 37035515.0 | Betty Thomas | 贝蒂·托马斯(Betty Thomas) | … | … | 12000.0 | 12000.0 | 10000.0 | 10000.0 | 664.0 | 664.0 | 23864 | 23864 | 0 | 0 | 1 | 1个 | 34597 | 34597 | 194.0 | 194.0 | 116.0 | 116.0 | 6.0 | 6.0 |
| 3 Strikes | 3次罢工 | 2000 | 2000 | Comedy | 喜剧 | English | 英语 | USA | 美国 | R | [R | 82.0 | 82.0 | 1.85 | 1.85 | 6000000.0 | 6000000.0 | 9821335.0 | 9821335.0 | DJ Pooh | 小熊维尼 | … | … | 939.0 | 939.0 | 706.0 | 706.0 | 585.0 | 585.0 | 3354 | 3354 | 118 | 118 | 1 | 1个 | 1415 | 1415 | 10.0 | 10.0 | 22.0 | 22.0 | 4.0 | 4.0 |
| Aberdeen | 香港仔 | 2000 | 2000 | Drama | 戏剧 | English | 英语 | UK | 英国 | NaN | N | 106.0 | 106.0 | 1.85 | 1.85 | 6500000.0 | 6500000.0 | 64148.0 | 64148.0 | Hans Petter Moland | 汉斯·佩特·莫兰德 | … | … | 844.0 | 844.0 | 2.0 | 2.0 | 0.0 | 0.0 | 846 | 846 | 260 | 260 | 0 | 0 | 2601 | 2601 | 35.0 | 35.0 | 28.0 | 28.0 | 7.3 | 7.3 |
| All the Pretty Horses | 所有漂亮的马 | 2000 | 2000 | Drama|Romance|Western | 戏剧|浪漫|西方 | English | 英语 | USA | 美国 | PG-13 | PG-13 | 220.0 | 220.0 | 2.35 | 2.35 | 57000000.0 | 57000000.0 | 15527125.0 | 15527125.0 | Billy Bob Thornton | 比利·鲍勃·桑顿 | … | … | 13000.0 | 13000.0 | 861.0 | 861.0 | 820.0 | 820.0 | 15006 | 15006 | 652 | 652 | 2 | 2 | 11388 | 11388 | 183.0 | 183.0 | 85.0 | 85.0 | 5.8 | 5.8 |
5 rows × 24 columns
5行×24列
| Year | 年 | Genres | 体裁 | Language | 语言 | Country | 国家 | Content Rating | 内容分级 | Duration | 持续时间 | Aspect Ratio | 长宽比 | Budget | 预算 | Gross Earnings | 总收入 | Director | 导向器 | … | … | Facebook Likes – Actor 1 | Facebook喜欢–演员1 | Facebook Likes – Actor 2 | Facebook喜欢–演员2 | Facebook Likes – Actor 3 | Facebook喜欢–演员3 | Facebook Likes – cast Total | Facebook点赞–总计 | Facebook likes – Movie | Facebook喜欢–电影 | Facenumber in posters | 海报中的面Kong编号 | User Votes | 用户投票 | Reviews by Users | 用户评论 | Reviews by Crtiics | Crtiics的评论 | IMDB Score | IMDB分数 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Title | 标题 | ||||||||||||||||||||||||||||||||||||||||||
| 127 Hours | 127小时 | 2010.0 | 2010.0 | Adventure|Biography|Drama|Thriller | 冒险|传记|戏剧|惊悚 | English | 英语 | USA | 美国 | R | [R | 94.0 | 94.0 | 1.85 | 1.85 | 18000000.0 | 18000000.0 | 18329466.0 | 18329466.0 | Danny Boyle | 丹尼·博伊尔 | … | … | 11000.0 | 11000.0 | 642.0 | 642.0 | 223.0 | 223.0 | 11984 | 11984 | 63000 | 63000 | 0.0 | 0.0 | 279179 | 279179 | 440.0 | 440.0 | 450.0 | 450.0 | 7.6 | 7.6 |
| 3 Backyards | 3个后院 | 2010.0 | 2010.0 | Drama | 戏剧 | English | 英语 | USA | 美国 | R | [R | 88.0 | 88.0 | NaN | N | 300000.0 | 300000.0 | NaN | N | Eric Mendelsohn | 埃里克·门德尔松 | … | … | 795.0 | 795.0 | 659.0 | 659.0 | 301.0 | 301.0 | 1884 | 1884年 | 92 | 92 | 0.0 | 0.0 | 554 | 554 | 23.0 | 23.0 | 20.0 | 20.0 | 5.2 | 5.2 |
| 3 | 3 | 2010.0 | 2010.0 | Comedy|Drama|Romance | 喜剧|戏剧|浪漫 | German | 德语 | Germany | 德国 | Unrated | 未分级 | 119.0 | 119.0 | 2.35 | 2.35 | NaN | N | 59774.0 | 59774.0 | Tom Tykwer | 汤姆·Tyk维尔 | … | … | 24.0 | 24.0 | 20.0 | 20.0 | 9.0 | 9.0 | 69 | 69 | 2000 | 2000 | 0.0 | 0.0 | 4212 | 4212 | 18.0 | 18.0 | 76.0 | 76.0 | 6.8 | 6.8 |
| 8: The Mormon Proposition | 8:摩门教徒命题 | 2010.0 | 2010.0 | Documentary | 记录 | English | 英语 | USA | 美国 | R | [R | 80.0 | 80.0 | 1.78 | 1.78 | 2500000.0 | 2500000.0 | 99851.0 | 99851.0 | Reed Cowan | 里德·考恩(Reed Cowan) | … | … | 191.0 | 191.0 | 12.0 | 12.0 | 5.0 | 5.0 | 210 | 210 | 0 | 0 | 0.0 | 0.0 | 1138 | 1138 | 30.0 | 30.0 | 28.0 | 28.0 | 7.1 | 7.1 |
| A Turtle’s Tale: Sammy’s Adventures | 乌龟的故事:萨米历险记 | 2010.0 | 2010.0 | Adventure|Animation|Family | 冒险|动画|家庭 | English | 英语 | France | 法国 | PG | PG | 88.0 | 88.0 | 2.35 | 2.35 | NaN | N | NaN | N | Ben Stassen | 本·斯塔森 | … | … | 783.0 | 783.0 | 749.0 | 749.0 | 602.0 | 602.0 | 3874 | 3874 | 0 | 0 | 2.0 | 2.0 | 5385 | 5385 | 22.0 | 22.0 | 56.0 | 56.0 | 6.1 | 6.1 |
5 rows × 24 columns
5行×24列
Since all the three sheets have similar data but for different recordsmovies, we will create a single DataFrame from all the three DataFrames we created above. We will use the pandas concat method for this and pass in the names of the three DataFrames we just created and assign the results to a new DataFrame object, movies. By keeping the DataFrame name same as before, we are over-writing the previously created DataFrame.
由于所有三个工作表都具有相似的数据,但记录运动不同,因此,我们将从上面创建的所有三个数据帧中创建一个数据帧。 我们将使用大熊猫concat方法,这和传递我们刚刚创建的三个DataFrames的名称和结果分配到一个新的数据帧的对象, movies 。 通过保持DataFrame名称与以前相同,我们将覆盖先前创建的DataFrame。
movies = pd.concat([movies_sheet1, movies_sheet2, movies_sheet3])movies = pd.concat([movies_sheet1, movies_sheet2, movies_sheet3])
We can check if this concatenation by checking the number of rows in the combined DataFrame by calling the method shape on it that will give us the number of rows and columns.
我们可以通过在组合的DataFrame中调用方法shape来检查组合的DataFrame中的行数,从而检查此串联,从而得出行数和列数。
(5042, 24)(5042, 24)
使用ExcelFile类读取多张工作表 (Using the ExcelFile class to read multiple sheets)
We can also use the ExcelFile class to work with multiple sheets from the same Excel file. We first wrap the Excel file using ExcelFile and then pass it to read_excel method.
我们还可以使用ExcelFile类来处理来自同一Excel文件的多个工作表。 我们首先使用ExcelFile包装Excel文件,然后将其传递给read_excel方法。
If you are reading an Excel file with a lot of sheets and are creating a lot of DataFrames, ExcelFile is more convenient and efficient in comparison to read_excel. With ExcelFile, you only need to pass the Excel file once, and then you can use it to get the DataFrames. When using read_excel, you pass the Excel file every time and hence the file is loaded again for every sheet. This can be a huge performance drag if the Excel file has many sheets with a large number of rows.
如果你正在读了很多张的Excel文件,并创建了很多DataFrames的, ExcelFile是更方便快捷相比, read_excel 。 使用ExcelFile,您只需传递一次Excel文件,然后就可以使用它来获取DataFrame。 使用read_excel ,每次都传递Excel文件,因此将为每张纸再次加载该文件。 如果Excel文件中包含许多行数很多的工作表,这可能会极大地拖累性能。
探索数据 (Exploring the data)
Now that we have read in the movies data set from our Excel file, we can start exploring it using pandas. A pandas DataFrame stores the data in a tabular format, just like the way Excel displays the data in a sheet. Pandas has a lot of built-in methods to explore the DataFrame we created from the Excel file we just read in.
现在,我们已经从Excel文件中读取了电影数据集,我们可以开始使用熊猫进行探索了。 大熊猫DataFrame以表格格式存储数据,就像Excel在表格中显示数据的方式一样。 Pandas有很多内置方法可以探索我们从刚刚读入的Excel文件创建的DataFrame。
We already introduced the method head in the previous section that displays few rows from the top from the DataFrame. Let’s look at few more methods that come in handy while exploring the data set.
我们已经介绍的方法head在上一节,其中显示从数据框顶部几行。 让我们看看在探索数据集时会派上用场的其他几种方法。
We can use the shape method to find out the number of rows and columns for the DataFrame.
我们可以使用shape方法找出DataFrame的行数和列数。
movies.shapemovies.shape
This tells us our Excel file has 5042 records and 25 columns or observations. This can be useful in reporting the number of records and columns and comparing that with the source data set.
这告诉我们我们的Excel文件具有5042条记录和25列或观察值。 这对于报告记录和列的数量并将其与源数据集进行比较很有用。
We can use the tail method to view the bottom rows. If no parameter is passed, only the bottom five rows are returned.
我们可以使用tail方法查看底部的行。 如果未传递任何参数,则仅返回底部的五行。
movies.tail()movies.tail()
| Title | 标题 | Year | 年 | Genres | 体裁 | Language | 语言 | Country | 国家 | Content Rating | 内容分级 | Duration | 持续时间 | Aspect Ratio | 长宽比 | Budget | 预算 | Gross Earnings | 总收入 | … | … | Facebook Likes – Actor 1 | Facebook喜欢–演员1 | Facebook Likes – Actor 2 | Facebook喜欢–演员2 | Facebook Likes – Actor 3 | Facebook喜欢–演员3 | Facebook Likes – cast Total | Facebook点赞–总计 | Facebook likes – Movie | Facebook喜欢–电影 | Facenumber in posters | 海报中的面Kong编号 | User Votes | 用户投票 | Reviews by Users | 用户评论 | Reviews by Crtiics | Crtiics的评论 | IMDB Score | IMDB分数 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1599 | 1599 | War & Peace | 战争与和平 | NaN | N | Drama|History|Romance|War | 戏剧|历史|浪漫|战争 | English | 英语 | UK | 英国 | TV-14 | TV-14 | NaN | N | 16.00 | 16.00 | NaN | N | NaN | N | … | … | 1000.0 | 1000.0 | 888.0 | 888.0 | 502.0 | 502.0 | 4528 | 4528 | 11000 | 11000 | 1.0 | 1.0 | 9277 | 9277 | 44.0 | 44.0 | 10.0 | 10.0 | 8.2 | 8.2 |
| 1600 | 1600 | Wings | 翅膀 | NaN | N | Comedy|Drama | 喜剧|戏剧 | English | 英语 | USA | 美国 | NaN | N | 30.0 | 30.0 | 1.33 | 1.33 | NaN | N | NaN | N | … | … | 685.0 | 685.0 | 511.0 | 511.0 | 424.0 | 424.0 | 1884 | 1884年 | 1000 | 1000 | 5.0 | 5.0 | 7646 | 7646 | 56.0 | 56.0 | 19.0 | 19.0 | 7.3 | 7.3 |
| 1601 | 1601 | Wolf Creek | 狼溪 | NaN | N | Drama|Horror|Thriller | 戏剧|恐怖|惊悚 | English | 英语 | Australia | 澳大利亚 | NaN | N | NaN | N | 2.00 | 2.00 | NaN | N | NaN | N | … | … | 511.0 | 511.0 | 457.0 | 457.0 | 206.0 | 206.0 | 1617 | 1617 | 954 | 954 | 0.0 | 0.0 | 726 | 726 | 6.0 | 6.0 | 2.0 | 2.0 | 7.1 | 7.1 |
| 1602 | 1602 | Wuthering Heights | 呼啸山庄 | NaN | N | Drama|Romance | 戏剧|浪漫 | English | 英语 | UK | 英国 | NaN | N | 142.0 | 142.0 | NaN | N | NaN | N | NaN | N | … | … | 27000.0 | 27000.0 | 698.0 | 698.0 | 427.0 | 427.0 | 29196 | 29196 | 0 | 0 | 2.0 | 2.0 | 6053 | 6053 | 33.0 | 33.0 | 9.0 | 9.0 | 7.7 | 7.7 |
| 1603 | 1603 | Yu-Gi-Oh! Duel Monsters | 宇基哦! 决斗怪物 | NaN | N | Action|Adventure|Animation|Family|Fantasy | 动作|冒险|动画|家庭|幻想 | Japanese | 日本 | Japan | 日本 | NaN | N | 24.0 | 24.0 | NaN | N | NaN | N | NaN | N | … | … | 0.0 | 0.0 | NaN | N | NaN | N | 0 | 0 | 124 | 124 | 0.0 | 0.0 | 12417 | 12417 | 51.0 | 51.0 | 6.0 | 6.0 | 7.0 | 7.0 |
5 rows × 25 columns
5行×25列
In Excel, you’re able to sort a sheet based on the values in one or more columns. In pandas, you can do the same thing with the sort_values method. For example, let’s sort our movies DataFrame based on the Gross Earnings column.
在Excel中,您可以根据一列或多列中的值对工作表进行排序。 在熊猫中,您可以使用sort_values方法执行相同的sort_values 。 例如,让我们根据“总收入”列对电影数据帧进行排序。
Since we have the data sorted by values in a column, we can do few interesting things with it. For example, we can display the top 10 movies by Gross Earnings.
由于我们将数据按列中的值排序,因此我们可以做一些有趣的事情。 例如,我们可以显示总收入前10名电影。
sorted_by_gross["Gross Earnings"].head(10)sorted_by_gross["Gross Earnings"].head(10)
We can also create a plot for the top 10 movies by Gross Earnings. Pandas makes it easy to visualize your data with plots and charts through matplotlib, a popular data visualization library. With a couple lines of code, you can start plotting. Moreover, matplotlib plots work well inside Jupyter Notebooks since you can displace the plots right under the code.
我们还可以为总收入前10部电影创建一个情节。 通过流行的数据可视化库matplotlib,Pandas使您可以轻松地使用绘图和图表可视化数据。 用几行代码,您就可以开始绘图。 此外,由于您可以在代码下直接放置图表,因此matplotlib图表在Jupyter Notebook中可以很好地工作。
First, we import the matplotlib module and set matplotlib to display the plots right in the Jupyter Notebook.
首先,我们导入matplotlib模块并设置matplotlib以在Jupyter Notebook中直接显示图。
import matplotlib.pyplot as plt %matplotlib inlineimport matplotlib.pyplot as plt %matplotlib inline
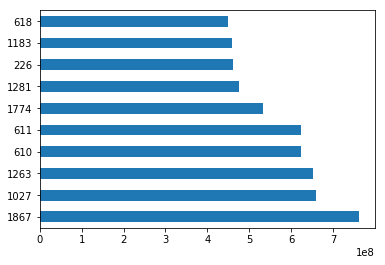
We will draw a bar plot where each bar will represent one of the top 10 movies. We can do this by calling the plot method and setting the argument kind to barh. This tells matplotlib to draw a horizontal bar plot.
我们将绘制一个条形图,其中每个条形将代表前十部电影之一。 我们可以通过调用plot方法并将参数kind设置为barh 。 这告诉matplotlib绘制水平条形图。
Let’s create a histogram of IMDB Scores to check the distribution of IMDB Scores across all movies. Histograms are a good way to visualize the distribution of a data set. We use the plot method on the IMDB Scores series from our movies DataFrame and pass it the argument kind="hist".
让我们创建一个IMDB分数的直方图,以检查IMDB分数在所有电影中的分布。 直方图是可视化数据集分布的好方法。 我们在电影DataFrame的IMDB Scores系列中使用plot方法,并将其传递给参数kind="hist" 。
movies['IMDB Score'].plot(kind="hist") plt.show()movies['IMDB Score'].plot(kind="hist") plt.show()
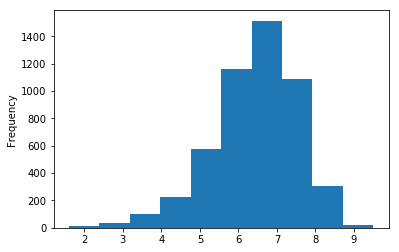
This data visualization suggests that most of the IMDB Scores fall between six and eight.
该数据可视化表明,大多数IMDB分数介于6到8之间。
获取有关数据的统计信息 (Getting statistical information about the data)
Pandas has some very handy methods to look at the statistical data about our data set. For example, we can use the describe method to get a statistical summary of the data set.
熊猫有一些非常方便的方法来查看有关我们数据集的统计数据。 例如,我们可以使用describe方法获取数据集的统计摘要。
| Year | 年 | Duration | 持续时间 | Aspect Ratio | 长宽比 | Budget | 预算 | Gross Earnings | 总收入 | Facebook Likes – Director | Facebook点赞–导演 | Facebook Likes – Actor 1 | Facebook喜欢–演员1 | Facebook Likes – Actor 2 | Facebook喜欢–演员2 | Facebook Likes – Actor 3 | Facebook喜欢–演员3 | Facebook Likes – cast Total | Facebook点赞–总计 | Facebook likes – Movie | Facebook喜欢–电影 | Facenumber in posters | 海报中的面Kong编号 | User Votes | 用户投票 | Reviews by Users | 用户评论 | Reviews by Crtiics | Crtiics的评论 | IMDB Score | IMDB分数 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 计数 | 4935.000000 | 4935.000000 | 5028.000000 | 5028.000000 | 4714.000000 | 4714.000000 | 4.551000e+03 | 4.551000e + 03 | 4.159000e+03 | 4.159000e + 03 | 4938.000000 | 4938.000000 | 5035.000000 | 5035.000000 | 5029.000000 | 5029.000000 | 5020.000000 | 5020.000000 | 5042.000000 | 5042.000000 | 5042.000000 | 5042.000000 | 5029.000000 | 5029.000000 | 5.042000e+03 | 5.042000e + 03 | 5022.000000 | 5022.000000 | 4993.000000 | 4993.000000 | 5042.000000 | 5042.000000 |
| mean | 意思 | 2002.470517 | 2002.470517 | 107.201074 | 107.201074 | 2.220403 | 2.220403 | 3.975262e+07 | 3.975262e + 07 | 4.846841e+07 | 4.846841e + 07 | 686.621709 | 686.621709 | 6561.323932 | 6561.323932 | 1652.080533 | 1652.080533 | 645.009761 | 645.009761 | 9700.959143 | 9700.959143 | 7527.457160 | 7527.457160 | 1.371446 | 1.371446 | 8.368475e+04 | 8.368475e + 04 | 272.770808 | 272.770808 | 140.194272 | 140.194272 | 6.442007 | 6.442007 |
| std | 性病 | 12.474599 | 12.474599 | 25.197441 | 25.197441 | 1.385113 | 1.385113 | 2.061149e+08 | 2.061149e + 08 | 6.845299e+07 | 6.845299e + 07 | 2813.602405 | 2813.602405 | 15021.977635 | 15021.977635 | 4042.774685 | 4042.774685 | 1665.041728 | 1665.041728 | 18165.101925 | 18165.101925 | 19322.070537 | 19322.070537 | 2.013683 | 2.013683 | 1.384940e+05 | 1.384940e + 05 | 377.982886 | 377.982886 | 121.601675 | 121.601675 | 1.125189 | 1.125189 |
| min | 分 | 1916.000000 | 1916.000000 | 7.000000 | 700万 | 1.180000 | 1.180000 | 2.180000e+02 | 2.180000e + 02 | 1.620000e+02 | 1.620000e + 02 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 5.000000e+00 | 5.000000e + 00 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.600000 | 1.600000 |
| 25% | 25% | 1999.000000 | 1999.000000 | 93.000000 | 93.000000 | 1.850000 | 1.850000 | 6.000000e+06 | 6.000000e + 06 | 5.340988e+06 | 5.340988e + 06 | 7.000000 | 700万 | 614.500000 | 614.500000 | 281.000000 | 281.000000 | 133.000000 | 133.000000 | 1411.250000 | 1411.250000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 8.599250e+03 | 8.599250e + 03 | 65.000000 | 65.000000 | 50.000000 | 50.000000 | 5.800000 | 5.800000 |
| 50% | 50% | 2005.000000 | 2005.000000 | 103.000000 | 103.000000 | 2.350000 | 2.350000 | 2.000000e+07 | 2.000000e + 07 | 2.551750e+07 | 2.551750e + 07 | 49.000000 | 49.000000 | 988.000000 | 988.000000 | 595.000000 | 595.000000 | 371.500000 | 371.500000 | 3091.000000 | 3091.000000 | 166.000000 | 166.000000 | 1.000000 | 1.000000 | 3.437100e+04 | 3.437100e + 04 | 156.000000 | 156.000000 | 110.000000 | 110.000000 | 6.600000 | 6.600000 |
| 75% | 75% | 2011.000000 | 2011.000000 | 118.000000 | 118.000000 | 2.350000 | 2.350000 | 4.500000e+07 | 4.500000e + 07 | 6.230944e+07 | 6.230944e + 07 | 194.750000 | 194.750000 | 11000.000000 | 11000.000000 | 918.000000 | 918.000000 | 636.000000 | 636.000000 | 13758.750000 | 13758.750000 | 3000.000000 | 3000.000000 | 2.000000 | 2.000000 | 9.634700e+04 | 9.634700e + 04 | 326.000000 | 326.000000 | 195.000000 | 195.000000 | 7.200000 | 7.200000 |
| max | 最高 | 2016.000000 | 2016.000000 | 511.000000 | 511.000000 | 16.000000 | 16000000 | 1.221550e+10 | 1.221550e + 10 | 7.605058e+08 | 7.605058e + 08 | 23000.000000 | 23000.000000 | 640000.000000 | 640000.000000 | 137000.000000 | 137000.000000 | 23000.000000 | 23000.000000 | 656730.000000 | 656730.000000 | 349000.000000 | 349000.000000 | 43.000000 | 43.000000 | 1.689764e+06 | 1.689764e + 06 | 5060.000000 | 5060.000000 | 813.000000 | 813.000000 | 9.500000 | 9.500000 |
The describe method displays below information for each of the columns.
describe方法为每个列显示以下信息。
- the count or number of values
- mean
- standard deviation
- minimum, maximum
- 25%, 50%, and 75% quantile
- 值的数量或数量
- 意思
- 标准偏差
- 最小,最大
- 25%,50%和75%的分位数
Please note that this information will be calculated only for the numeric values.
请注意,此信息仅针对数字值进行计算。
We can also use the corresponding method to access this information one at a time. For example, to get the mean of a particular column, you can use the mean method on that column.
我们也可以使用相应的方法一次访问此信息。 例如,要获取特定列的mean ,可以在该列上使用mean方法。
movies["Gross Earnings"].mean()movies["Gross Earnings"].mean()
Just like mean, there are methods available for each of the statistical information we want to access. You can read about these methods in our free pandas cheat sheet.
就像平均值一样,对于我们要访问的每个统计信息,都有可用的方法。 您可以在我们的免费熊猫备忘单上阅读有关这些方法的信息。
读取没有标题的文件并跳过记录 (Reading files with no header and skipping records)
Earlier in this tutorial, we saw some ways to read a particular kind of Excel file that had headers and no rows that needed skipping. Sometimes, the Excel sheet doesn’t have any header row. For such instances, you can tell pandas not to consider the first row as header or columns names. And If the Excel sheet’s first few rows contain data that should not be read in, you can ask the read_excel method to skip a certain number of rows, starting from the top.
在本教程的前面,我们看到了一些方法来读取一种特殊的Excel文件,该文件具有标题并且没有需要跳过的行。 有时,Excel工作表没有任何标题行。 对于此类情况,您可以告诉熊猫不要将第一行视为标题或列名。 并且,如果Excel工作表的前几行包含不应读取的数据,则可以要求read_excel方法从顶部开始跳过一定数量的行。
For example, look at the top few rows of this Excel file.
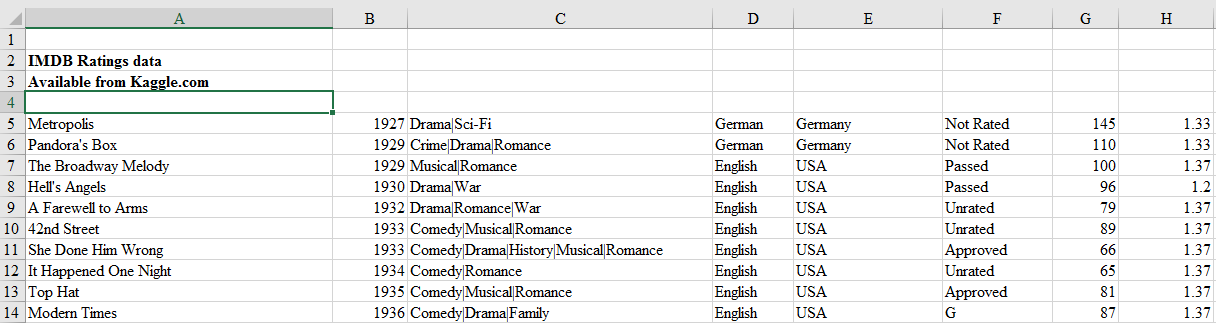
例如,查看此Excel文件的前几行。
This file obviously has no header and first four rows are not actual records and hence should not be read in. We can tell read_excel there is no header by setting argument header to None and we can skip first four rows by setting argument skiprows to four.
该文件显然没有标题,并且前四行不是实际记录,因此不应读取。通过将参数header设置为None可以告诉read_excel没有标题,我们可以通过将参数skiprows设置为4来跳过前四行。
movies_skip_rows = pd.read_excel("movies-no-header-skip-rows.xls", header=None, skiprows=4) movies_skip_rows.head(5)movies_skip_rows = pd.read_excel("movies-no-header-skip-rows.xls", header=None, skiprows=4) movies_skip_rows.head(5)
| 0 | 0 | 1 | 1个 | 2 | 2 | 3 | 3 | 4 | 4 | 5 | 5 | 6 | 6 | 7 | 7 | 8 | 8 | 9 | 9 | … | … | 15 | 15 | 16 | 16 | 17 | 17 | 18 | 18 | 19 | 19 | 20 | 20 | 21 | 21 | 22 | 22 | 23 | 23 | 24 | 24 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Metropolis | 都会 | 1927 | 1927年 | Drama|Sci-Fi | 戏剧|科幻 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 145 | 145 | 1.33 | 1.33 | 6000000.0 | 6000000.0 | 26435.0 | 26435.0 | … | … | 136 | 136 | 23 | 23 | 18.0 | 18.0 | 203 | 203 | 12000 | 12000 | 1 | 1个 | 111841 | 111841 | 413 | 413 | 260.0 | 260.0 | 8.3 | 8.3 |
| 1 | 1个 | Pandora’s Box | 潘多拉魔盒 | 1929 | 1929年 | Crime|Drama|Romance | 犯罪|戏剧|浪漫 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 110 | 110 | 1.33 | 1.33 | NaN | N | 9950.0 | 9950.0 | … | … | 426 | 426 | 20 | 20 | 3.0 | 3.0 | 455 | 455 | 926 | 926 | 1 | 1个 | 7431 | 7431 | 84 | 84 | 71.0 | 71.0 | 8.0 | 8.0 |
| 2 | 2 | The Broadway Melody | 百老汇旋律 | 1929 | 1929年 | Musical|Romance | 音乐|浪漫 | English | 英语 | USA | 美国 | Passed | 已通过 | 100 | 100 | 1.37 | 1.37 | 379000.0 | 379000.0 | 2808000.0 | 2808000.0 | … | … | 77 | 77 | 28 | 28 | 4.0 | 4.0 | 109 | 109 | 167 | 167 | 8 | 8 | 4546 | 4546 | 71 | 71 | 36.0 | 36.0 | 6.3 | 6.3 |
| 3 | 3 | Hell’s Angels | 地狱天使 | 1930 | 1930年 | Drama|War | 戏剧|战争 | English | 英语 | USA | 美国 | Passed | 已通过 | 96 | 96 | 1.20 | 1.20 | 3950000.0 | 3950000.0 | NaN | N | … | … | 431 | 431 | 12 | 12 | 4.0 | 4.0 | 457 | 457 | 279 | 279 | 1 | 1个 | 3753 | 3753 | 53 | 53 | 35.0 | 35.0 | 7.8 | 7.8 |
| 4 | 4 | A Farewell to Arms | 告别武器 | 1932 | 1932年 | Drama|Romance|War | 戏剧|浪漫|战争 | English | 英语 | USA | 美国 | Unrated | 未分级 | 79 | 79 | 1.37 | 1.37 | 800000.0 | 800000.0 | NaN | N | … | … | 998 | 998 | 164 | 164 | 99.0 | 99.0 | 1284 | 1284 | 213 | 213 | 1 | 1个 | 3519 | 3519 | 46 | 46 | 42.0 | 42.0 | 6.6 | 6.6 |
5 rows × 25 columns
5行×25列
We skipped four rows from the sheet and used none of the rows as the header. Also, notice that one can combine different options in a single read statement. To skip rows at the bottom of the sheet, you can use option skip_footer, which works just like skiprows, the only difference being the rows are counted from the bottom upwards.
我们从工作表中跳过了四行,没有任何行用作标题。 另外,请注意,可以在一个read语句中组合不同的选项。 要跳过工作表底部的行,可以使用选项skip_footer ,该选项的工作方式与skiprows ,唯一的区别是行是从底部向上计数的。
The column names in the previous DataFrame are numeric and were allotted as default by the pandas. We can rename the column names to descriptive ones by calling the method columns on the DataFrame and passing the column names as a list.
前一个DataFrame中的列名称是数字,并且由熊猫默认分配。 通过在DataFrame上调用方法columns并将列名称作为列表传递,我们可以将列名称重命名为描述性名称。
| Title | 标题 | Year | 年 | Genres | 体裁 | Language | 语言 | Country | 国家 | Content Rating | 内容分级 | Duration | 持续时间 | Aspect Ratio | 长宽比 | Budget | 预算 | Gross Earnings | 总收入 | … | … | Facebook Likes – Actor 1 | Facebook喜欢–演员1 | Facebook Likes – Actor 2 | Facebook喜欢–演员2 | Facebook Likes – Actor 3 | Facebook喜欢–演员3 | Facebook Likes – cast Total | Facebook点赞–总计 | Facebook likes – Movie | Facebook喜欢–电影 | Facenumber in posters | 海报中的面Kong编号 | User Votes | 用户投票 | Reviews by Users | 用户评论 | Reviews by Crtiics | Crtiics的评论 | IMDB Score | IMDB分数 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Metropolis | 都会 | 1927 | 1927年 | Drama|Sci-Fi | 戏剧|科幻 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 145 | 145 | 1.33 | 1.33 | 6000000.0 | 6000000.0 | 26435.0 | 26435.0 | … | … | 136 | 136 | 23 | 23 | 18.0 | 18.0 | 203 | 203 | 12000 | 12000 | 1 | 1个 | 111841 | 111841 | 413 | 413 | 260.0 | 260.0 | 8.3 | 8.3 |
| 1 | 1个 | Pandora’s Box | 潘多拉魔盒 | 1929 | 1929年 | Crime|Drama|Romance | 犯罪|戏剧|浪漫 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 110 | 110 | 1.33 | 1.33 | NaN | N | 9950.0 | 9950.0 | … | … | 426 | 426 | 20 | 20 | 3.0 | 3.0 | 455 | 455 | 926 | 926 | 1 | 1个 | 7431 | 7431 | 84 | 84 | 71.0 | 71.0 | 8.0 | 8.0 |
| 2 | 2 | The Broadway Melody | 百老汇旋律 | 1929 | 1929年 | Musical|Romance | 音乐|浪漫 | English | 英语 | USA | 美国 | Passed | 已通过 | 100 | 100 | 1.37 | 1.37 | 379000.0 | 379000.0 | 2808000.0 | 2808000.0 | … | … | 77 | 77 | 28 | 28 | 4.0 | 4.0 | 109 | 109 | 167 | 167 | 8 | 8 | 4546 | 4546 | 71 | 71 | 36.0 | 36.0 | 6.3 | 6.3 |
| 3 | 3 | Hell’s Angels | 地狱天使 | 1930 | 1930年 | Drama|War | 戏剧|战争 | English | 英语 | USA | 美国 | Passed | 已通过 | 96 | 96 | 1.20 | 1.20 | 3950000.0 | 3950000.0 | NaN | N | … | … | 431 | 431 | 12 | 12 | 4.0 | 4.0 | 457 | 457 | 279 | 279 | 1 | 1个 | 3753 | 3753 | 53 | 53 | 35.0 | 35.0 | 7.8 | 7.8 |
| 4 | 4 | A Farewell to Arms | 告别武器 | 1932 | 1932年 | Drama|Romance|War | 戏剧|浪漫|战争 | English | 英语 | USA | 美国 | Unrated | 未分级 | 79 | 79 | 1.37 | 1.37 | 800000.0 | 800000.0 | NaN | N | … | … | 998 | 998 | 164 | 164 | 99.0 | 99.0 | 1284 | 1284 | 213 | 213 | 1 | 1个 | 3519 | 3519 | 46 | 46 | 42.0 | 42.0 | 6.6 | 6.6 |
5 rows × 25 columns
5行×25列
Now that we have seen how to read a subset of rows from the Excel file, we can learn how to read a subset of columns.
现在,我们已经了解了如何从Excel文件中读取行的子集,我们可以学习如何读取列的子集。
读取列的子集 (Reading a subset of columns)
Although read_excel defaults to reading and importing all columns, you can choose to import only certain columns. By passing parse_cols=6, we are telling the read_excel method to read only the first columns till index six or first seven columns (the first column being indexed zero).
尽管read_excel默认为读取和导入所有列,但是您可以选择仅导入某些列。 通过传递parse_cols = 6,我们告诉read_excel方法仅读取第一列,直到索引六或前七个列(第一列的索引为零)。
movies_subset_columns = pd.read_excel(excel_file, parse_cols=6) movies_subset_columns.head()movies_subset_columns = pd.read_excel(excel_file, parse_cols=6) movies_subset_columns.head()
| Title | 标题 | Year | 年 | Genres | 体裁 | Language | 语言 | Country | 国家 | Content Rating | 内容分级 | Duration | 持续时间 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Intolerance: Love’s Struggle Throughout the Ages | 不宽容:千古以来的爱情挣扎 | 1916 | 1916年 | Drama|History|War | 戏剧|历史|战争 | NaN | N | USA | 美国 | Not Rated | 没有评分 | 123 | 123 |
| 1 | 1个 | Over the Hill to the Poorhouse | 越过山到贫民窟 | 1920 | 1920年 | Crime|Drama | 犯罪|戏剧 | NaN | N | USA | 美国 | NaN | N | 110 | 110 |
| 2 | 2 | The Big Parade | 大游行 | 1925 | 1925年 | Drama|Romance|War | 戏剧|浪漫|战争 | NaN | N | USA | 美国 | Not Rated | 没有评分 | 151 | 151 |
| 3 | 3 | Metropolis | 都会 | 1927 | 1927年 | Drama|Sci-Fi | 戏剧|科幻 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 145 | 145 |
| 4 | 4 | Pandora’s Box | 潘多拉魔盒 | 1929 | 1929年 | Crime|Drama|Romance | 犯罪|戏剧|浪漫 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 110 | 110 |
Alternatively, you can pass in a list of numbers, which will let you import columns at particular indexes.
或者,您可以传入一个数字列表,这将使您可以导入特定索引处的列。
在列上应用公式 (Applying formulas on the columns)
One of the much-used features of Excel is to apply formulas to create new columns from existing column values. In our Excel file, we have Gross Earnings and Budget columns. We can get Net earnings by subtracting Budget from Gross earnings. We could then apply this formula in the Excel file to all the rows. We can do this in pandas also as shown below.
Excel的常用功能之一是应用公式从现有列值创建新列。 在我们的Excel文件中,我们有“总收入”和“预算”列。 我们可以通过从总收入中减去预算来获得净收入。 然后,我们可以将此公式在Excel文件中应用于所有行。 我们也可以在熊猫中做到这一点,如下所示。
Above, we used pandas to create a new column called Net Earnings, and populated it with the difference of Gross Earnings and Budget. It’s worth noting the difference here in how formulas are treated in Excel versus pandas. In Excel, a formula lives in the cell and updates when the data changes – with Python, the calculations happen and the values are stored – if Gross Earnings for one movie was manually changed, Net Earnings won’t be updated.
上面,我们用熊猫创建了一个名为“净收入”的新列,并在其中填充了“总收入”和“预算”的差额。 值得注意的是,Excel和熊猫在公式处理方式上的区别。 在Excel中,公式存在于单元格中,并在数据更改时更新-使用Python,会进行计算并存储值-如果手动更改了一部电影的总收入,则净收入不会更新。
Let’s use the sot_values method to sort the data by the new column we created and visualize the top 10 movies by Net Earnings.
让我们使用sot_values方法按我们创建的新列对数据进行排序,并按“净收入”显示前十部电影。
sorted_movies = movies[['Net Earnings']].sort_values(['Net Earnings'], ascending=[False]) sorted_movies.head(10)['Net Earnings'].plot.barh() plt.show()sorted_movies = movies[['Net Earnings']].sort_values(['Net Earnings'], ascending=[False]) sorted_movies.head(10)['Net Earnings'].plot.barh() plt.show()
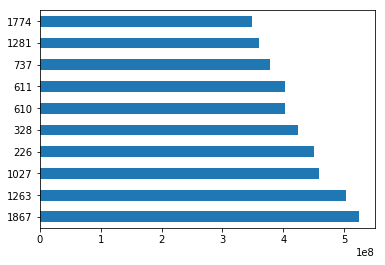
熊猫数据透视表 (Pivot Table in pandas)
Advanced Excel users also often use pivot tables. A pivot table summarizes the data of another table by grouping the data on an index and applying operations such as sorting, summing, or averaging. You can use this feature in pandas too.
高级Excel用户还经常使用数据透视表。 数据透视表通过将数据分组到索引上并应用诸如排序,求和或求平均之类的操作来汇总另一个表的数据。 您也可以在熊猫中使用此功能。
We need to first identify the column or columns that will serve as the index, and the column(s) on which the summarizing formula will be applied. Let’s start small, by choosing Year as the index column and Gross Earnings as the summarization column and creating a separate DataFrame from this data.
我们首先需要确定将用作索引的一个或多个列,以及将应用汇总公式的列。 让我们从小处开始,选择“年”作为索引列,选择“总收入”作为汇总列,然后从该数据创建一个单独的DataFrame。
| Year | 年 | Gross Earnings | 总收入 | ||
|---|---|---|---|---|---|
| 0 | 0 | 1916.0 | 1916.0 | NaN | N |
| 1 | 1个 | 1920.0 | 1920.0 | 3000000.0 | 3000000.0 |
| 2 | 2 | 1925.0 | 1925.0 | NaN | N |
| 3 | 3 | 1927.0 | 1927.0 | 26435.0 | 26435.0 |
| 4 | 4 | 1929.0 | 1929.0 | 9950.0 | 9950.0 |
We now call pivot_table on this subset of data. The method pivot_table takes a parameter index. As mentioned, we want to use Year as the index.
现在,我们将此数据子集称为“ pivot_table ”。 pivot_table方法采用参数index 。 如前所述,我们要使用Year作为索引。
earnings_by_year = movies_subset.pivot_table(index=['Year']) earnings_by_year.head()earnings_by_year = movies_subset.pivot_table(index=['Year']) earnings_by_year.head()
| Gross Earnings | 总收入 | ||
|---|---|---|---|
| Year | 年 | ||
| 1916.0 | 1916.0 | NaN | N |
| 1920.0 | 1920.0 | 3000000.0 | 3000000.0 |
| 1925.0 | 1925.0 | NaN | N |
| 1927.0 | 1927.0 | 26435.0 | 26435.0 |
| 1929.0 | 1929.0 | 1408975.0 | 1408975.0 |
This gave us a pivot table with grouping on Year and summarization on the sum of Gross Earnings. Notice, we didn’t need to specify Gross Earnings column explicitly as pandas automatically identified it the values on which summarization should be applied.
这为我们提供了一个枢纽分析表,其中按年份分组并汇总了总收入。 注意,我们不需要明确指定“总收入”列,因为熊猫会自动将其识别为应应用汇总的值。
We can use this pivot table to create some data visualizations. We can call the plot method on the DataFrame to create a line plot and call the show method to display the plot in the notebook.
我们可以使用此数据透视表创建一些数据可视化。 我们可以在DataFrame上调用plot方法创建线图,并调用show方法在笔记本中显示该图。
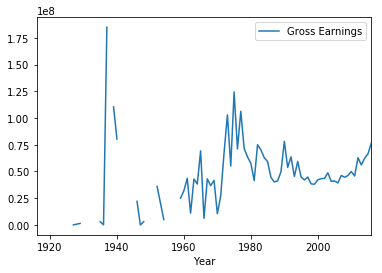
We saw how to pivot with a single column as the index. Things will get more interesting if we can use multiple columns. Let’s create another DataFrame subset but this time we will choose the columns, Country, Language and Gross Earnings.
我们看到了如何以单个列作为索引进行数据透视。 如果我们可以使用多列,事情将会变得更加有趣。 让我们创建另一个DataFrame子集,但是这次我们将选择“国家/地区”,“语言”和“总收入”列。
movies_subset = movies[['Country', 'Language', 'Gross Earnings']] movies_subset.head()movies_subset = movies[['Country', 'Language', 'Gross Earnings']] movies_subset.head()
| Country | 国家 | Language | 语言 | Gross Earnings | 总收入 | ||
|---|---|---|---|---|---|---|---|
| 0 | 0 | USA | 美国 | NaN | N | NaN | N |
| 1 | 1个 | USA | 美国 | NaN | N | 3000000.0 | 3000000.0 |
| 2 | 2 | USA | 美国 | NaN | N | NaN | N |
| 3 | 3 | Germany | 德国 | German | 德语 | 26435.0 | 26435.0 |
| 4 | 4 | Germany | 德国 | German | 德语 | 9950.0 | 9950.0 |
We will use columns Country and Language as the index for the pivot table. We will use Gross Earnings as summarization table, however, we do not need to specify this explicitly as we saw earlier.
我们将使用“国家”和“语言”列作为数据透视表的索引。 我们将使用毛收入作为汇总表,但是,我们不需要像前面看到的那样明确地指定它。
| Gross Earnings | 总收入 | ||||
|---|---|---|---|---|---|
| Country | 国家 | Language | 语言 | ||
| Afghanistan | 阿富汗 | Dari | 达里 | 1.127331e+06 | 1.127331e + 06 |
| Argentina | 阿根廷 | Spanish | 西班牙文 | 7.230936e+06 | 7.230936e + 06 |
| Aruba | 阿鲁巴岛 | English | 英语 | 1.007614e+07 | 1.007614e + 07 |
| Australia | 澳大利亚 | Aboriginal | 土著 | 6.165429e+06 | 6.165429e + 06 |
| Dzongkha | 宗卡 | 5.052950e+05 | 5.052950e + 05 |
Let’s visualize this pivot table with a bar plot. Since there are still few hundred records in this pivot table, we will plot just a few of them.
让我们用条形图可视化此数据透视表。 由于此数据透视表中仍然有几百条记录,因此我们将只绘制其中的几条。
earnings_by_co_lang.head(20).plot(kind='bar', figsize=(20,8)) plt.show()earnings_by_co_lang.head(20).plot(kind='bar', figsize=(20,8)) plt.show()
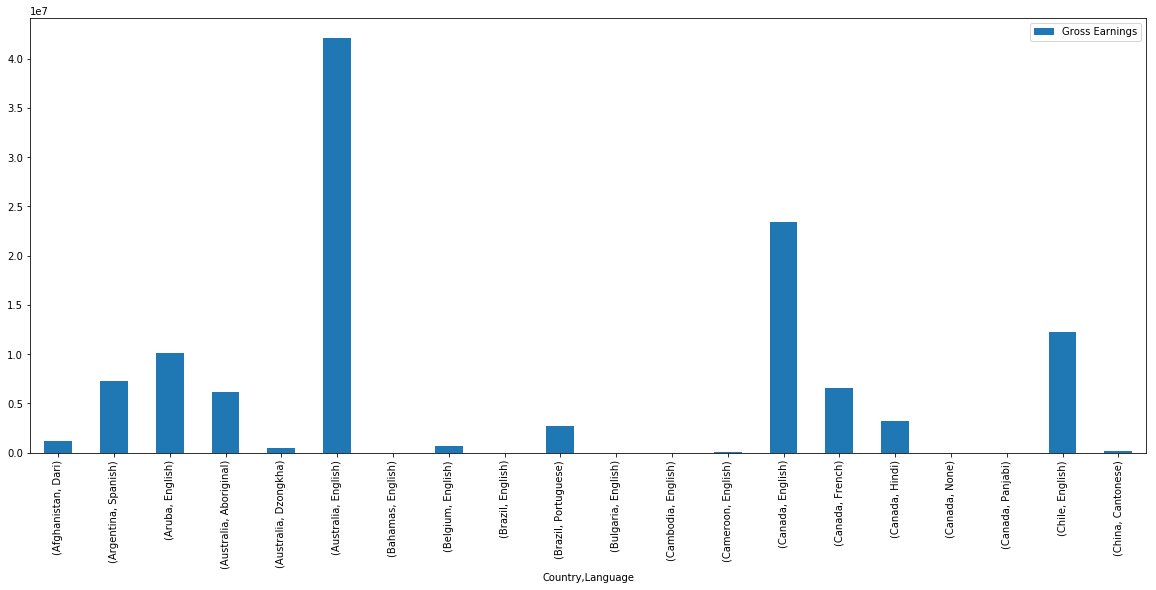
将结果导出到Excel (Exporting the results to Excel)
If you’re going to be working with colleagues who use Excel, saving Excel files out of pandas is important. You can export or write a pandas DataFrame to an Excel file using pandas to_excel method. Pandas uses the xlwt Python module internally for writing to Excel files. The to_excel method is called on the DataFrame we want to export.We also need to pass a filename to which this DataFrame will be written.
如果您要与使用Excel的同事一起工作,则将Excel文件保存在熊猫之外非常重要。 您可以使用pandas to_excel方法将pandas to_excel导出或写入Excel文件。 熊猫内部使用xlwt Python模块写入Excel文件。 在要to_excel上调用to_excel方法,我们还需要传递一个文件名,该DataFrame将被写入该文件名。
By default, the index is also saved to the output file. However, sometimes the index doesn’t provide any useful information. For example, the movies DataFrame has a numeric auto-increment index, that was not part of the original Excel data.
默认情况下,索引也保存到输出文件中。 但是,有时索引不提供任何有用的信息。 例如, movies DataFrame具有数字自动增量索引,该索引不属于原始Excel数据。
movies.head()movies.head()
| Title | 标题 | Year | 年 | Genres | 体裁 | Language | 语言 | Country | 国家 | Content Rating | 内容分级 | Duration | 持续时间 | Aspect Ratio | 长宽比 | Budget | 预算 | Gross Earnings | 总收入 | … | … | Facebook Likes – Actor 2 | Facebook喜欢–演员2 | Facebook Likes – Actor 3 | Facebook喜欢–演员3 | Facebook Likes – cast Total | Facebook点赞–总计 | Facebook likes – Movie | Facebook喜欢–电影 | Facenumber in posters | 海报中的面Kong编号 | User Votes | 用户投票 | Reviews by Users | 用户评论 | Reviews by Crtiics | Crtiics的评论 | IMDB Score | IMDB分数 | Net Earnings | 净收益 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Intolerance: Love’s Struggle Throughout the Ages | 不宽容:千古以来的爱情挣扎 | 1916.0 | 1916.0 | Drama|History|War | 戏剧|历史|战争 | NaN | N | USA | 美国 | Not Rated | 没有评分 | 123.0 | 123.0 | 1.33 | 1.33 | 385907.0 | 385907.0 | NaN | N | … | … | 22.0 | 22.0 | 9.0 | 9.0 | 481 | 481 | 691 | 691 | 1.0 | 1.0 | 10718 | 10718 | 88.0 | 88.0 | 69.0 | 69.0 | 8.0 | 8.0 | NaN | N |
| 1 | 1个 | Over the Hill to the Poorhouse | 越过山到贫民窟 | 1920.0 | 1920.0 | Crime|Drama | 犯罪|戏剧 | NaN | N | USA | 美国 | NaN | N | 110.0 | 110.0 | 1.33 | 1.33 | 100000.0 | 100000.0 | 3000000.0 | 3000000.0 | … | … | 2.0 | 2.0 | 0.0 | 0.0 | 4 | 4 | 0 | 0 | 1.0 | 1.0 | 5 | 5 | 1.0 | 1.0 | 1.0 | 1.0 | 4.8 | 4.8 | 2900000.0 | 2900000.0 |
| 2 | 2 | The Big Parade | 大游行 | 1925.0 | 1925.0 | Drama|Romance|War | 戏剧|浪漫|战争 | NaN | N | USA | 美国 | Not Rated | 没有评分 | 151.0 | 151.0 | 1.33 | 1.33 | 245000.0 | 245000.0 | NaN | N | … | … | 12.0 | 12.0 | 6.0 | 6.0 | 108 | 108 | 226 | 226 | 0.0 | 0.0 | 4849 | 4849 | 45.0 | 45.0 | 48.0 | 48.0 | 8.3 | 8.3 | NaN | N |
| 3 | 3 | Metropolis | 都会 | 1927.0 | 1927.0 | Drama|Sci-Fi | 戏剧|科幻 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 145.0 | 145.0 | 1.33 | 1.33 | 6000000.0 | 6000000.0 | 26435.0 | 26435.0 | … | … | 23.0 | 23.0 | 18.0 | 18.0 | 203 | 203 | 12000 | 12000 | 1.0 | 1.0 | 111841 | 111841 | 413.0 | 413.0 | 260.0 | 260.0 | 8.3 | 8.3 | -5973565.0 | -5973565.0 |
| 4 | 4 | Pandora’s Box | 潘多拉魔盒 | 1929.0 | 1929.0 | Crime|Drama|Romance | 犯罪|戏剧|浪漫 | German | 德语 | Germany | 德国 | Not Rated | 没有评分 | 110.0 | 110.0 | 1.33 | 1.33 | NaN | N | 9950.0 | 9950.0 | … | … | 20.0 | 20.0 | 3.0 | 3.0 | 455 | 455 | 926 | 926 | 1.0 | 1.0 | 7431 | 7431 | 84.0 | 84.0 | 71.0 | 71.0 | 8.0 | 8.0 | NaN | N |
5 rows × 26 columns
5行×26列
You can choose to skip the index by passing along index-False.
您可以通过传递index-False来选择跳过索引。
We need to be able to make our output files look nice before we can send it out to our co-workers. We can use pandas ExcelWriter class along with the XlsxWriter Python module to apply the formatting.
我们需要能够使输出文件看起来更好,然后才能将其发送给我们的同事。 我们可以将熊猫ExcelWriter类与XlsxWriter Python模块一起使用以应用格式。
We can do use these advanced output options by creating a ExcelWriter object and use this object to write to the EXcel file.
我们可以通过创建ExcelWriter对象并使用此对象写入EXcel文件来使用这些高级输出选项。
writer = pd.ExcelWriter('output.xlsx', engine='xlsxwriter') movies.to_excel(writer, index=False, sheet_name='report') workbook = writer.book worksheet = writer.sheets['report']writer = pd.ExcelWriter('output.xlsx', engine='xlsxwriter') movies.to_excel(writer, index=False, sheet_name='report') workbook = writer.book worksheet = writer.sheets['report']
We can apply customizations by calling add_format on the workbook we are writing to. Here we are setting header format as bold.
我们可以通过在要写入的工作簿上调用add_format来应用定制。 在这里,我们将标题格式设置为粗体。
Finally, we save the output file by calling the method save on the writer object.
最后,我们通过调用writer对象上的save方法来save输出文件。
writer.save()writer.save()
As an example, we saved the data with column headers set as bold. And the saved file looks like the image below.
例如,我们保存的数据的列标题设置为粗体。 保存的文件如下图所示。
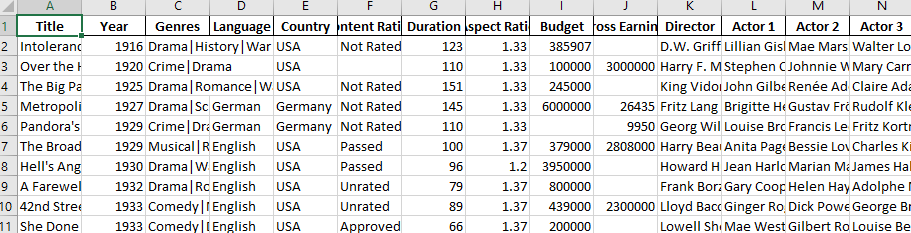
Like this, one can use XlsxWriter to apply various formatting to the output Excel file.
这样,可以使用XlsxWriter将各种格式应用于输出Excel文件。
结论 (Conclusion)
翻译自: https://www.pybloggers.com/2017/12/using-excel-with-pandas/
熊猫压缩怎么使用















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









