





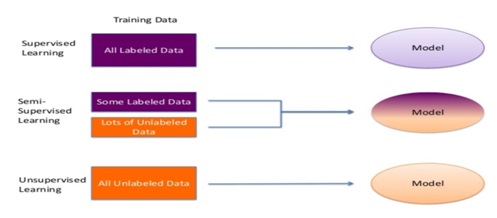
 本文介绍了机器学习的基本概念,以及监督学习、无监督学习、半监督学习和强化学习四大类型的详细解释,包括每种类型的特点和应用场景。通过学习,可以理解不同类型机器学习在解决问题时的不同方法和策略。
本文介绍了机器学习的基本概念,以及监督学习、无监督学习、半监督学习和强化学习四大类型的详细解释,包括每种类型的特点和应用场景。通过学习,可以理解不同类型机器学习在解决问题时的不同方法和策略。
机器学习基本算法及其改进后
机器学习 (Machine Learning)
Machine learning is some sort of statistical tools and algorithm that are used to learn from data. It is used to make machines capable of doing tasks like human intelligence.
机器学习是用于从数据中学习的某种统计工具和算法 。 它用于使机器能够执行诸如人类智能之类的任务。
Like a nascent human being, a machine learning model learns from data samples (predictor variable) as in training phase; and then, it finally concludes with predicting some answer (target).
就像新生的人类一样,机器学习模型在训练阶段从数据样本( 预测变量 )中学习; 然后,最后以预测答案( 目标 )作为结论。
But the nature of target variable may be a factor leading to broad classification of machine learning itself. Based on the nature of predictions we are going to make; our complete approach and method of solving the ML problem may vary from one to another.
但是目标变量的性质可能是导致机器学习本身进行广泛分类的一个因素。 基于预测的性质,我们将要进行; 我们解决机器学习问题的完整方法和方法可能各不相同。
Though this classification itself has some controversies. Few intellectuals classify it into 2 - subdivisions; few classify into 3 - subdivisions, and few into 4 - subdivisions.
尽管这种分类本身存在一些争议。 很少有知识分子将其分为2类。 几乎没有分类为3个细分,而很少有4个细分。
Here, I am putting it broadly into 2- subdivisions for convenience; but, I will explain each of these 4 - subclasses.
在这里,为方便起见,我将其大致分为2个细分; 但是,我将解释这4个子类中的每一个。
机器学习的主要类型 (Main types of machine learning)
Supervised Machine learning
有监督的机器学习
Unsupervised Machine Learning
无监督机器学习
Other Types
其他种类
Semi - supervised Machine Learning
半监督机器学习
Reinforcement Learning (Mostly considered as supervised learning - Source Wikipedia)
强化学习(通常被认为是监督学习-来源Wikipedia)
1)监督学习 (1) Supervised Learning)
→ The target variable/output is labeled. Viz. we are already aware of what we are going to Predict.
→目标变量/输出标记为 。 就是 我们已经知道我们要预测什么。
Points:
要点:
Uses data that is labeled
使用标有标签的数据
Who labels data? → Data expert (viz. oracle)
谁标记数据? →数据专家(viz.oracle)
It also has two types: Classification and Regression. (See diagram below)
它还有两种类型: 分类和回归 。 (参见下图)

2)无监督学习 (2) Unsupervised Learning)
→ The target variable/output is not labeled. Viz. we are not known about the classes we are going to predict.
→目标变量/输出未标记 。 就是 我们不知道我们要预测的课程。
→ For solving this, we do grouping of data; and then, name them according to our Convenience or some expert results. This group is called "cluster" and method is known as "clustering".
→为了解决这个问题,我们进行数据分组; 然后,根据我们的便利性或一些专家的结果为它们命名。 该组称为“集群” ,方法称为“集群” 。
POINTS
要点
Uses data that is unlabelled.
使用未标记的数据。
Who labels data? → User doing predictions or may be data experts (after clustering).
谁标记数据? →做预测的用户或可能是数据专家(聚类后)。
This could be better understood with the help of a classification tree graph. I am also mentioning few popular and notable algorithms falling under these categories. But, these are just a few. (Keep updated to learn about others in detail).
借助分类树图可以更好地理解这一点。 我还提到了属于这些类别的几种流行且值得注意的算法。 但是,这些只是少数。 (请保持更新以了解其他详细信息)。

Here, I am adding few more useful algorithms into this classification tree, and making it more general:
在这里,我将更多有用的算法添加到此分类树中,并使之更通用:

OTHERS
其他
3)半监督学习 (3) Semi-supervised Learning)
→ Machine learning problems fall into this category when, we have a very few labeled data; and most of the target variable are unlabelled. We take help of those few labeled targets to decide classes for those unlabelled targets.
→当我们只有很少的标记数据时,机器学习问题就属于此类。 并且大多数目标变量未标记。 我们利用少数几个标记目标的帮助来决定那些未标记目标的类别。
→ We first classify/predict with labelled target variables and consider unlabelled targets also. Let’s understand this through a diagram below:
→我们首先使用标记的目标变量进行分类/预测 ,并考虑未标记的目标。 让我们通过下面的图表来了解这一点:
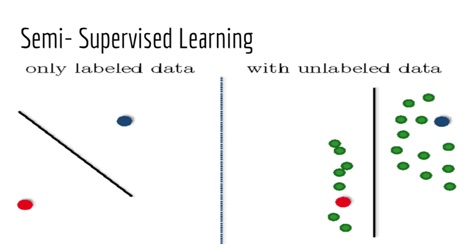
Let’s conclude them with a very illustrative diagram:
让我们用一个非常说明性的图表来结束它们:
4)强化学习 (4) Reinforcement Learning)
→ It is based on scores. Its main objective is to find which actions should be taken in order to maximize rewards under a given setting. Each time we assign scores to each move in a winning game (say chess → computer v/s human) based on the result and the current state on the board. Each time we assign a grade to an action in order to minimize a punishment and/or maximize rewards.
→它基于分数 。 它的主要目的是发现在给定的环境下应采取哪些措施才能使报酬最大化 。 每次我们根据结果和棋盘上的当前状态为获胜游戏 (例如国际象棋→电脑对人类)中的每个动作分配分数时。 每次我们为动作分配一个等级,以最小化惩罚和/或最大化奖励 。

Conclusion
结论
Finally, I would conclude that ML problems are really fun while solving. Our approach towards solving a particular AI problem changes slightly depending on the type of problem. So, at first we need to recognize which kind of problem we are going to tackle. Then we should map out our approach. Obtain scores for different models; and then compile the optimized solution. This is path to solve any ML/AI problem. It makes your task look easy and fun. So, just figure out some Problems and find out by yourselves about their type. Feel free to ask your queries in comment section. Meet you in the next article. HAPPY LEARNING!
最后,我得出的结论是,求解时ML问题确实很有趣。 我们解决特定AI问题的方法根据问题的类型而略有不同。 因此,首先我们需要认识到我们要解决的问题。 然后,我们应该制定方法。 获得不同模式的分数; 然后编译优化的解决方案 。 这是解决任何ML / AI问题的途径。 它使您的任务看起来轻松有趣。 因此,只需找出一些问题并自己找出它们的类型。 随时在评论部分询问您的问题。 在下一篇文章中与您会面。 快乐的学习!
翻译自: https://www.includehelp.com/ml-ai/machine-learning-and-its-types.aspx
机器学习基本算法及其改进后















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









