





带有Python的AI – NLTK软件包 (AI with Python – NLTK Package)
In this chapter, we will learn how to get started with the Natural Language Toolkit Package.
在本章中,我们将学习如何开始使用“自然语言工具包”。
先决条件 (Prerequisite)
If we want to build applications with Natural Language processing then the change in context makes it most difficult. The context factor influences how the machine understands a particular sentence. Hence, we need to develop Natural language applications by using machine learning approaches so that machine can also understand the way a human can understand the context.
如果我们要使用自然语言处理来构建应用程序,那么上下文的更改将使其变得最困难。 上下文因素影响机器如何理解特定句子。 因此,我们需要通过使用机器学习方法来开发自然语言应用程序,以便机器也可以理解人类可以理解上下文的方式。
To build such applications we will use the Python package called NLTK (Natural Language Toolkit Package).
为了构建这样的应用程序,我们将使用称为NLTK(自然语言工具包)的Python包。
导入NLTK (Importing NLTK)
We need to install NLTK before using it. It can be installed with the help of the following command −
我们需要在使用前安装NLTK。 可以在以下命令的帮助下进行安装-
pip install nltk
To build a conda package for NLTK, use the following command −
要为NLTK构建conda软件包,请使用以下命令-
conda install -c anaconda nltk
Now after installing the NLTK package, we need to import it through the python command prompt. We can import it by writing the following command on the Python command prompt −
现在,在安装NLTK软件包之后,我们需要通过python命令提示符将其导入。 我们可以通过在Python命令提示符下编写以下命令来导入它-
>>> import nltk
下载NLTK的数据 (Downloading NLTK’s Data)
Now after importing NLTK, we need to download the required data. It can be done with the help of the following command on the Python command prompt −
现在,在导入NLTK之后,我们需要下载所需的数据。 可以在Python命令提示符下的以下命令的帮助下完成-
>>> nltk.download()
安装其他必需的软件包 (Installing Other Necessary Packages)
For building natural language processing applications by using NLTK, we need to install the necessary packages. The packages are as follows −
为了使用NLTK构建自然语言处理应用程序,我们需要安装必要的软件包。 软件包如下-
Gensim (gensim)
It is a robust semantic modeling library that is useful for many applications. We can install it by executing the following command −
它是一个健壮的语义建模库,对许多应用程序很有用。 我们可以通过执行以下命令来安装它-
pip install gensim
模式 (pattern)
It is used to make gensim package work properly. We can install it by executing the following command
它用于使gensim程序包正常工作。 我们可以通过执行以下命令来安装它
pip install pattern
标记化,词干和词法化的概念 (Concept of Tokenization, Stemming, and Lemmatization)
In this section, we will understand what is tokenization, stemming, and lemmatization.
在本节中,我们将了解什么是标记化,词干和词形化。
代币化 (Tokenization)
It may be defined as the process of breaking the given text i.e. the character sequence into smaller units called tokens. The tokens may be the words, numbers or punctuation marks. It is also called word segmentation. Following is a simple example of tokenization −
它可以定义为将给定文本(即字符序列)分解为称为令牌的较小单元的过程。 令牌可以是单词,数字或标点符号。 也称为分词。 以下是令牌化的简单示例-
Input − Mango, banana, pineapple and apple all are fruits.
输入 -芒果,香蕉,菠萝和苹果都是水果。

Output −
输出 -
The process of breaking the given text can be done with the help of locating the word boundaries. The ending of a word and the beginning of a new word are called word boundaries. The writing system and the typographical structure of the words influence the boundaries.
可以通过定位单词边界来完成破坏给定文本的过程。 单词的结尾和新单词的开头称为单词边界。 单词的书写系统和印刷结构会影响边界。
In the Python NLTK module, we have different packages related to tokenization which we can use to divide the text into tokens as per our requirements. Some of the packages are as follows −
在Python NLTK模块中,我们有与令牌化相关的不同软件包,可根据需要将其用于将文本分为令牌。 一些软件包如下-
sent_tokenize包 (sent_tokenize package)
As the name suggest, this package will divide the input text into sentences. We can import this package with the help of the following Python code −
顾名思义,此程序包会将输入文本分为句子。 我们可以在以下Python代码的帮助下导入此软件包-
from nltk.tokenize import sent_tokenize
word_tokenize软件包 (word_tokenize package)
This package divides the input text into words. We can import this package with the help of the following Python code −
该软件包将输入文本分为单词。 我们可以在以下Python代码的帮助下导入此软件包-
from nltk.tokenize import word_tokenize
WordPunctTokenizer程序包 (WordPunctTokenizer package)
This package divides the input text into words as well as the punctuation marks. We can import this package with the help of the following Python code −
该程序包将输入文本分为单词和标点符号。 我们可以在以下Python代码的帮助下导入此软件包-
from nltk.tokenize import WordPuncttokenizer
抽干 (Stemming)
While working with words, we come across a lot of variations due to grammatical reasons. The concept of variations here means that we have to deal with different forms of the same words like democracy, democratic, and democratization. It is very necessary for machines to understand that these different words have the same base form. In this way, it would be useful to extract the base forms of the words while we are analyzing the text.
在处理单词时,由于语法原因,我们会遇到很多变化。 这里的变体概念意味着我们必须应对相同形式的不同形式,例如民主,民主和民主化 。 对于机器而言,非常有必要理解这些不同的词具有相同的基本形式。 这样,在分析文本时提取单词的基本形式将很有用。
We can achieve this by stemming. In this way, we can say that stemming is the heuristic process of extracting the base forms of the words by chopping off the ends of words.
我们可以通过阻止来实现这一目标。 这样,我们可以说词干是通过切掉单词的结尾来提取单词的基本形式的启发式过程。
In the Python NLTK module, we have different packages related to stemming. These packages can be used to get the base forms of word. These packages use algorithms. Some of the packages are as follows −
在Python NLTK模块中,我们具有与词干相关的不同软件包。 这些软件包可用于获取单词的基本形式。 这些软件包使用算法。 一些软件包如下-
PorterStemmer包装 (PorterStemmer package)
This Python package uses the Porter’s algorithm to extract the base form. We can import this package with the help of the following Python code −
该Python软件包使用Porter的算法提取基本表单。 我们可以在以下Python代码的帮助下导入此软件包-
from nltk.stem.porter import PorterStemmer
For example, if we will give the word ‘writing’ as the input to this stemmer them we will get the word ‘write’ after stemming.
例如,如果我们将“文字”一词作为此词干的输入,他们在词干后将得到“文字”一词。
LancasterStemmer软件包 (LancasterStemmer package)
This Python package will use the Lancaster’s algorithm to extract the base form. We can import this package with the help of the following Python code −
该Python软件包将使用Lancaster的算法提取基本表单。 我们可以在以下Python代码的帮助下导入此软件包-
from nltk.stem.lancaster import LancasterStemmer
For example, if we will give the word ‘writing’ as the input to this stemmer them we will get the word ‘write’ after stemming.
例如,如果我们将“文字”一词作为此词干的输入,他们在词干后将得到“文字”一词。
SnowballStemmer包装 (SnowballStemmer package)
This Python package will use the snowball’s algorithm to extract the base form. We can import this package with the help of the following Python code −
该Python软件包将使用雪球算法提取基本表单。 我们可以在以下Python代码的帮助下导入此软件包-
from nltk.stem.snowball import SnowballStemmer
For example, if we will give the word ‘writing’ as the input to this stemmer them we will get the word ‘write’ after stemming.
例如,如果我们将“文字”一词作为此词干的输入,他们在词干后将得到“文字”一词。
All of these algorithms have different level of strictness. If we compare these three stemmers then the Porter stemmers is the least strict and Lancaster is the strictest. Snowball stemmer is good to use in terms of speed as well as strictness.
所有这些算法都具有不同的严格程度。 如果我们比较这三个词干,那么Porter词干是最不严格的,而Lancaster是最严格的。 Snowball stemmer在速度和严格性方面都很好用。
合法化 (Lemmatization)
We can also extract the base form of words by lemmatization. It basically does this task with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only. This kind of base form of any word is called lemma.
我们还可以通过词法提取词的基本形式。 它基本上是通过词汇的词汇和词法分析来完成此任务的,通常仅旨在消除屈折词尾。 任何单词的这种基本形式都称为引理。
The main difference between stemming and lemmatization is the use of vocabulary and morphological analysis of the words. Another difference is that stemming most commonly collapses derivationally related words whereas lemmatization commonly only collapses the different inflectional forms of a lemma. For example, if we provide the word saw as the input word then stemming might return the word ‘s’ but lemmatization would attempt to return the word either see or saw depending on whether the use of the token was a verb or a noun.
词干和词根化之间的主要区别是单词的词汇和词法分析。 另一个区别是,词干最通常会使与派生词相关的单词崩溃,而词根化通常只会使词缀的不同变形形式崩溃。 例如,如果我们将单词“ saw”作为输入单词,则词干提取可能会返回单词“ s”,但是词条修饰会尝试根据单词使用的是动词还是名词来返回“ see”或“ see”一词。
In the Python NLTK module, we have the following package related to lemmatization process which we can use to get the base forms of word −
在Python NLTK模块中,我们有以下与词形化过程相关的软件包,可用于获取单词的基本形式-
WordNetLemmatizer程序包 (WordNetLemmatizer package)
This Python package will extract the base form of the word depending upon whether it is used as a noun or as a verb. We can import this package with the help of the following Python code −
这个Python软件包将提取单词的基本形式,具体取决于它是用作名词还是用作动词。 我们可以在以下Python代码的帮助下导入此软件包-
from nltk.stem import WordNetLemmatizer
块:将数据分为块 (Chunking: Dividing Data into Chunks)
It is one of the important processes in natural language processing. The main job of chunking is to identify the parts of speech and short phrases like noun phrases. We have already studied the process of tokenization, the creation of tokens. Chunking basically is the labeling of those tokens. In other words, chunking will show us the structure of the sentence.
它是自然语言处理中的重要过程之一。 分块的主要工作是识别语音和名词短语之类的简短词组。 我们已经研究了令牌化的过程,即令牌的创建。 块基本上是这些令牌的标签。 换句话说,分块将向我们展示句子的结构。
In the following section, we will learn about the different types of Chunking.
在以下部分中,我们将学习不同类型的Chunking。
分块的类型 (Types of chunking)
There are two types of chunking. The types are as follows −
有两种类型的分块。 类型如下-
分块 (Chunking up)
In this process of chunking, the object, things, etc. move towards being more general and the language gets more abstract. There are more chances of agreement. In this process, we zoom out. For example, if we will chunk up the question that “for what purpose cars are”? We may get the answer “transport”.
在分块的过程中,对象,事物等朝着更加通用的方向发展,语言变得更加抽象。 达成协议的机会更多。 在此过程中,我们将缩小。 例如,如果我们将“汽车的用途是什么”这个问题堆砌起来? 我们可能会得到“运输”的答案。
分块 (Chunking down)
In this process of chunking, the object, things, etc. move towards being more specific and the language gets more penetrated. The deeper structure would be examined in chunking down. In this process, we zoom in. For example, if we chunk down the question “Tell specifically about a car”? We will get smaller pieces of information about the car.
在分块的过程中,对象,事物等朝着更加具体的方向发展,并且语言也得到了更深入的渗透。 更深层次的结构将在细分中进行检查。 在此过程中,我们进行了放大。例如,我们是否将“专门讲一辆汽车”的问题简化了? 我们将获得有关汽车的较小信息。
Example
例
In this example, we will do Noun-Phrase chunking, a category of chunking which will find the noun phrases chunks in the sentence, by using the NLTK module in Python −
在此示例中,我们将使用Python中的NLTK模块进行名词短语分块,这是一个分块的类别,可以在句子中找到名词短语的分块-
Follow these steps in python for implementing noun phrase chunking −
在python中按照以下步骤实施名词短语分块-
Step 1 − In this step, we need to define the grammar for chunking. It would consist of the rules which we need to follow.
步骤1-在此步骤中,我们需要定义用于分块的语法。 它由我们需要遵循的规则组成。
Step 2 − In this step, we need to create a chunk parser. It would parse the grammar and give the output.
步骤2-在这一步中,我们需要创建一个块解析器。 它将解析语法并给出输出。
Step 3 − In this last step, the output is produced in a tree format.
步骤3-在最后一步中,输出以树格式生成。
Let us import the necessary NLTK package as follows −
让我们导入必要的NLTK包,如下所示:
import nltk
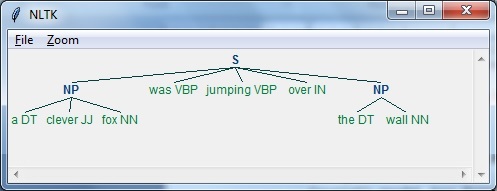
Now, we need to define the sentence. Here, DT means the determinant, VBP means the verb, JJ means the adjective, IN means the preposition and NN means the noun.
现在,我们需要定义句子。 在这里,DT是行列式,VBP是动词,JJ是形容词,IN是介词,NN是名词。
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"),
("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]
Now, we need to give the grammar. Here, we will give the grammar in the form of regular expression.
现在,我们需要给出语法。 在这里,我们将以正则表达式的形式给出语法。
grammar = "NP:{<DT>?<JJ>*<NN>}"
We need to define a parser which will parse the grammar.
我们需要定义一个解析器来解析语法。
parser_chunking = nltk.RegexpParser(grammar)
The parser parses the sentence as follows −
解析器解析句子如下-
parser_chunking.parse(sentence)
Next, we need to get the output. The output is generated in the simple variable called output_chunk.
接下来,我们需要获取输出。 输出在名为output_chunk的简单变量中生成。
Output_chunk = parser_chunking.parse(sentence)
Upon execution of the following code, we can draw our output in the form of a tree.
执行以下代码后,我们可以以树的形式绘制输出。
output.draw()
单词袋(BoW)模型 (Bag of Word (BoW) Model)
Bag of Word (BoW), a model in natural language processing, is basically used to extract the features from text so that the text can be used in modeling such that in machine learning algorithms.
单词袋(BoW)是自然语言处理中的模型,基本上用于从文本中提取特征,以便可以在建模中(例如在机器学习算法中)使用文本。
Now the question arises that why we need to extract the features from text. It is because the machine learning algorithms cannot work with raw data and they need numeric data so that they can extract meaningful information out of it. The conversion of text data into numeric data is called feature extraction or feature encoding.
现在出现的问题是,为什么我们需要从文本中提取特征。 这是因为机器学习算法无法处理原始数据,并且它们需要数字数据,以便可以从中提取有意义的信息。 文本数据到数字数据的转换称为特征提取或特征编码。
这个怎么运作 (How it works)
This is very simple approach for extracting the features from text. Suppose we have a text document and we want to convert it into numeric data or say want to extract the features out of it then first of all this model extracts a vocabulary from all the words in the document. Then by using a document term matrix, it will build a model. In this way, BoW represents the document as a bag of words only. Any information about the order or structure of words in the document is discarded.
这是从文本中提取特征的非常简单的方法。 假设我们有一个文本文档,我们想将其转换为数字数据,或者想从中提取特征,然后首先,该模型从文档中的所有单词中提取词汇。 然后,通过使用文档术语矩阵,它将建立一个模型。 这样,BoW仅将文档表示为单词包。 有关文档中单词顺序或结构的任何信息都将被丢弃。
文档术语矩阵的概念 (Concept of document term matrix)
The BoW algorithm builds a model by using the document term matrix. As the name suggests, the document term matrix is the matrix of various word counts that occur in the document. With the help of this matrix, the text document can be represented as a weighted combination of various words. By setting the threshold and choosing the words that are more meaningful, we can build a histogram of all the words in the documents that can be used as a feature vector. Following is an example to understand the concept of document term matrix −
BoW算法通过使用文档术语矩阵来构建模型。 顾名思义,文档术语矩阵是文档中出现的各种单词计数的矩阵。 借助此矩阵,可以将文本文档表示为各个单词的加权组合。 通过设置阈值并选择更有意义的词,我们可以构建文档中所有可用作特征向量的词的直方图。 以下是了解文档术语矩阵概念的示例-
Example
例
Suppose we have the following two sentences −
假设我们有以下两个句子-
Sentence 1 − We are using the Bag of Words model.
句子1-我们使用的是单词袋模型。
Sentence 2 − Bag of Words model is used for extracting the features.
句子2-单词袋模型用于提取特征。
Now, by considering these two sentences, we have the following 13 distinct words −
现在,通过考虑这两个句子,我们得到以下13个不同的词-
- we 我们
- are 是
- using 使用
- the 的
- bag 袋
- of 的
- words 话
- model 模型
- is 是
- used 用过的
- for 对于
- extracting 提取
- features 特征
Now, we need to build a histogram for each sentence by using the word count in each sentence −
现在,我们需要通过使用每个句子中的字数为每个句子建立直方图-
Sentence 1 − [1,1,1,1,1,1,1,1,0,0,0,0,0]
句子1- [1,1,1,1,1,1,1,1,0,0,0,0,0]
Sentence 2 − [0,0,0,1,1,1,1,1,1,1,1,1,1]
句子2- [0,0,0,1,1,1,1,1,1,1,1,1,1,1]
In this way, we have the feature vectors that have been extracted. Each feature vector is 13-dimensional because we have 13 distinct words.
这样,我们就可以提取特征向量。 每个特征向量都是13维的,因为我们有13个不同的词。
统计概念 (Concept of the Statistics)
The concept of the statistics is called TermFrequency-Inverse Document Frequency (tf-idf). Every word is important in the document. The statistics help us nderstand the importance of every word.
统计的概念称为TermFrequency-逆文档频率(tf-idf)。 每个单词在文档中都很重要。 统计数据有助于我们理解每个单词的重要性。
词频(tf) (Term Frequency(tf))
It is the measure of how frequently each word appears in a document. It can be obtained by dividing the count of each word by the total number of words in a given document.
它衡量每个单词在文档中出现的频率。 可以通过将每个单词的计数除以给定文档中单词的总数来获得。
反文档频率(idf) (Inverse Document Frequency(idf))
It is the measure of how unique a word is to this document in the given set of documents. For calculating idf and formulating a distinctive feature vector, we need to reduce the weights of commonly occurring words like the and weigh up the rare words.
它是衡量单词在给定文档集中对该文档的唯一性的量度。 为了计算idf并制定独特的特征向量,我们需要减少常见单词(如the)的权重并权衡稀有单词。
在NLTK中构建单词袋模型 (Building a Bag of Words Model in NLTK)
In this section, we will define a collection of strings by using CountVectorizer to create vectors from these sentences.
在本节中,我们将使用CountVectorizer从这些句子创建向量来定义字符串集合。
Let us import the necessary package −
让我们导入必要的包-
from sklearn.feature_extraction.text import CountVectorizer
Now define the set of sentences.
现在定义句子集。
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is
used for extracting the features.']
vectorizer_count = CountVectorizer()
features_text = vectorizer.fit_transform(Sentences).todense()
print(vectorizer.vocabulary_)
The above program generates the output as shown below. It shows that we have 13 distinct words in the above two sentences −
上面的程序生成如下所示的输出。 它表明我们在以上两个句子中有13个不同的词-
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7,
'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}
These are the feature vectors (text to numeric form) which can be used for machine learning.
这些是可以用于机器学习的特征向量(文本到数字形式)。
解决问题 (Solving Problems)
In this section, we will solve a few related problems.
在本节中,我们将解决一些相关问题。
类别预测 (Category Prediction)
In a set of documents, not only the words but the category of the words is also important; in which category of text a particular word falls. For example, we want to predict whether a given sentence belongs to the category email, news, sports, computer, etc. In the following example, we are going to use tf-idf to formulate a feature vector to find the category of documents. We will use the data from 20 newsgroup dataset of sklearn.
在一组文档中,不仅单词,而且单词的类别也很重要。 特定单词属于哪种文本类别。 例如,我们要预测给定的句子是否属于电子邮件,新闻,体育,计算机等类别。在以下示例中,我们将使用tf-idf公式化特征向量以查找文档的类别。 我们将使用来自sklearn的20个新闻组数据集的数据。
We need to import the necessary packages −
我们需要导入必要的软件包-
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
Define the category map. We are using five different categories named Religion, Autos, Sports, Electronics and Space.
定义类别图。 我们使用五个不同的类别,分别是宗教,汽车,体育,电子和太空。
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos',
'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}
Create the training set −
创建训练集-
training_data = fetch_20newsgroups(subset = 'train',
categories = category_map.keys(), shuffle = True, random_state = 5)
Build a count vectorizer and extract the term counts −
构建一个计数向量器并提取计数项-
vectorizer_count = CountVectorizer()
train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)
The tf-idf transformer is created as follows −
TF-IDF变压器创建如下-
tfidf = TfidfTransformer()
train_tfidf = tfidf.fit_transform(train_tc)
Now, define the test data −
现在,定义测试数据-
input_data = [
'Discovery was a space shuttle',
'Hindu, Christian, Sikh all are religions',
'We must have to drive safely',
'Puck is a disk made of rubber',
'Television, Microwave, Refrigrated all uses electricity'
]
The above data will help us train a Multinomial Naive Bayes classifier −
以上数据将帮助我们训练多项式朴素贝叶斯分类器-
classifier = MultinomialNB().fit(train_tfidf, training_data.target)
Transform the input data using the count vectorizer −
使用计数矢量化器转换输入数据-
input_tc = vectorizer_count.transform(input_data)
Now, we will transform the vectorized data using the tfidf transformer −
现在,我们将使用tfidf转换器转换矢量化数据-
input_tfidf = tfidf.transform(input_tc)
We will predict the output categories −
我们将预测输出类别-
predictions = classifier.predict(input_tfidf)
The output is generated as follows −
输出生成如下-
for sent, category in zip(input_data, predictions):
print('\nInput Data:', sent, '\n Category:', \
category_map[training_data.target_names[category]])
The category predictor generates the following output −
类别预测变量生成以下输出-
Dimensions of training data: (2755, 39297)
Input Data: Discovery was a space shuttle
Category: Space
Input Data: Hindu, Christian, Sikh all are religions
Category: Religion
Input Data: We must have to drive safely
Category: Autos
Input Data: Puck is a disk made of rubber
Category: Hockey
Input Data: Television, Microwave, Refrigrated all uses electricity
Category: Electronics
性别搜寻器 (Gender Finder)
In this problem statement, a classifier would be trained to find the gender (male or female) by providing the names. We need to use a heuristic to construct a feature vector and train the classifier. We will be using the labeled data from the scikit-learn package. Following is the Python code to build a gender finder −
在此问题陈述中,将训练分类器通过提供姓名来查找性别(男性或女性)。 我们需要使用启发式方法来构建特征向量并训练分类器。 我们将使用scikit-learn包中的标签数据。 以下是构建性别查找器的Python代码-
Let us import the necessary packages −
让我们导入必要的包-
import random
from nltk import NaiveBayesClassifier
from nltk.classify import accuracy as nltk_accuracy
from nltk.corpus import names
Now we need to extract the last N letters from the input word. These letters will act as features −
现在我们需要从输入单词中提取最后N个字母。 这些字母将充当特征-
def extract_features(word, N = 2):
last_n_letters = word[-N:]
return {'feature': last_n_letters.lower()}
if __name__=='__main__':
Create the training data using labeled names (male as well as female) available in NLTK −
使用NLTK中可用的带标签的名称(男性和女性)创建训练数据-
male_list = [(name, 'male') for name in names.words('male.txt')]
female_list = [(name, 'female') for name in names.words('female.txt')]
data = (male_list + female_list)
random.seed(5)
random.shuffle(data)
Now, test data will be created as follows −
现在,测试数据将如下创建:
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']
Define the number of samples used for train and test with the following code
使用以下代码定义用于训练和测试的样本数量
train_sample = int(0.8 * len(data))
Now, we need to iterate through different lengths so that the accuracy can be compared −
现在,我们需要迭代不同的长度,以便可以比较精度-
for i in range(1, 6):
print('\nNumber of end letters:', i)
features = [(extract_features(n, i), gender) for (n, gender) in data]
train_data, test_data = features[:train_sample],
features[train_sample:]
classifier = NaiveBayesClassifier.train(train_data)
The accuracy of the classifier can be computed as follows −
分类器的准确性可以计算如下-
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2)
print('Accuracy = ' + str(accuracy_classifier) + '%')
Now, we can predict the output −
现在,我们可以预测输出-
for name in namesInput:
print(name, '==>', classifier.classify(extract_features(name, i)))
The above program will generate the following output −
上面的程序将生成以下输出-
Number of end letters: 1
Accuracy = 74.7%
Rajesh -> female
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 2
Accuracy = 78.79%
Rajesh -> male
Gaurav -> male
Swati -> female
Shubha -> female
Number of end letters: 3
Accuracy = 77.22%
Rajesh -> male
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 4
Accuracy = 69.98%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
Number of end letters: 5
Accuracy = 64.63%
Rajesh -> female
Gaurav -> female
Swati -> female
Shubha -> female
In the above output, we can see that accuracy in maximum number of end letters are two and it is decreasing as the number of end letters are increasing.
在上面的输出中,我们可以看到最大结尾字母数的精度为2,并且随着结尾字母数的增加而降低。
主题建模:识别文本数据中的模式 (Topic Modeling: Identifying Patterns in Text Data)
We know that generally documents are grouped into topics. Sometimes we need to identify the patterns in a text that correspond to a particular topic. The technique of doing this is called topic modeling. In other words, we can say that topic modeling is a technique to uncover abstract themes or hidden structure in the given set of documents.
我们知道,一般来说文件都是按主题分组的。 有时我们需要识别文本中与特定主题相对应的模式。 执行此操作的技术称为主题建模。 换句话说,可以说主题建模是一种在给定的文档集中发现抽象主题或隐藏结构的技术。
We can use the topic modeling technique in the following scenarios −
我们可以在以下情况下使用主题建模技术-
文字分类 (Text Classification)
With the help of topic modeling, classification can be improved because it groups similar words together rather than using each word separately as a feature.
借助主题建模,可以改进分类,因为分类将相似的单词组合在一起,而不是将每个单词分别用作功能。
推荐系统 (Recommender Systems)
With the help of topic modeling, we can build the recommender systems by using similarity measures.
借助主题建模,我们可以使用相似性度量来构建推荐系统。
主题建模算法 (Algorithms for Topic Modeling)
Topic modeling can be implemented by using algorithms. The algorithms are as follows −
主题建模可以通过使用算法来实现。 算法如下-
潜在狄利克雷分配(LDA) (Latent Dirichlet Allocation(LDA))
This algorithm is the most popular for topic modeling. It uses the probabilistic graphical models for implementing topic modeling. We need to import gensim package in Python for using LDA slgorithm.
该算法在主题建模中最受欢迎。 它使用概率图形模型来实现主题建模。 我们需要在Python中导入gensim包以使用LDA slgorithm。
潜在语义分析(LDA)或潜在语义索引(LSI) (Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI))
This algorithm is based upon Linear Algebra. Basically it uses the concept of SVD (Singular Value Decomposition) on the document term matrix.
该算法基于线性代数。 基本上,它在文档术语矩阵上使用SVD(奇异值分解)的概念。
非负矩阵分解(NMF) (Non-Negative Matrix Factorization (NMF))
It is also based upon Linear Algebra.
它也基于线性代数。
All of the above mentioned algorithms for topic modeling would have the number of topics as a parameter, Document-Word Matrix as an input and WTM (Word Topic Matrix) & TDM (Topic Document Matrix) as output.
上面提到的所有用于主题建模的算法都将主题数作为参数,将文档-单词矩阵作为输入,并将WTM(单词主题矩阵)和TDM(主题文档矩阵)作为输出。















 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









