






概要
本文将对懂车帝的所有品牌车辆车型数据进行爬取,包括:车型,价格,车辆配置等信息。
一、使用模块
import re
from typing import Dict, Optional
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
二、反爬技术
1.js压缩和混淆
对代码进行压缩(去除空格,换行符)和混淆(无意义变量)降低可读性,格式化使得无法定位到数据的真实位置。
2.动态网页
动态网站通过JavaScript异步加载数据,需要查找数据接口,并且请求参数通常被加密参数保护。
三、分析过程
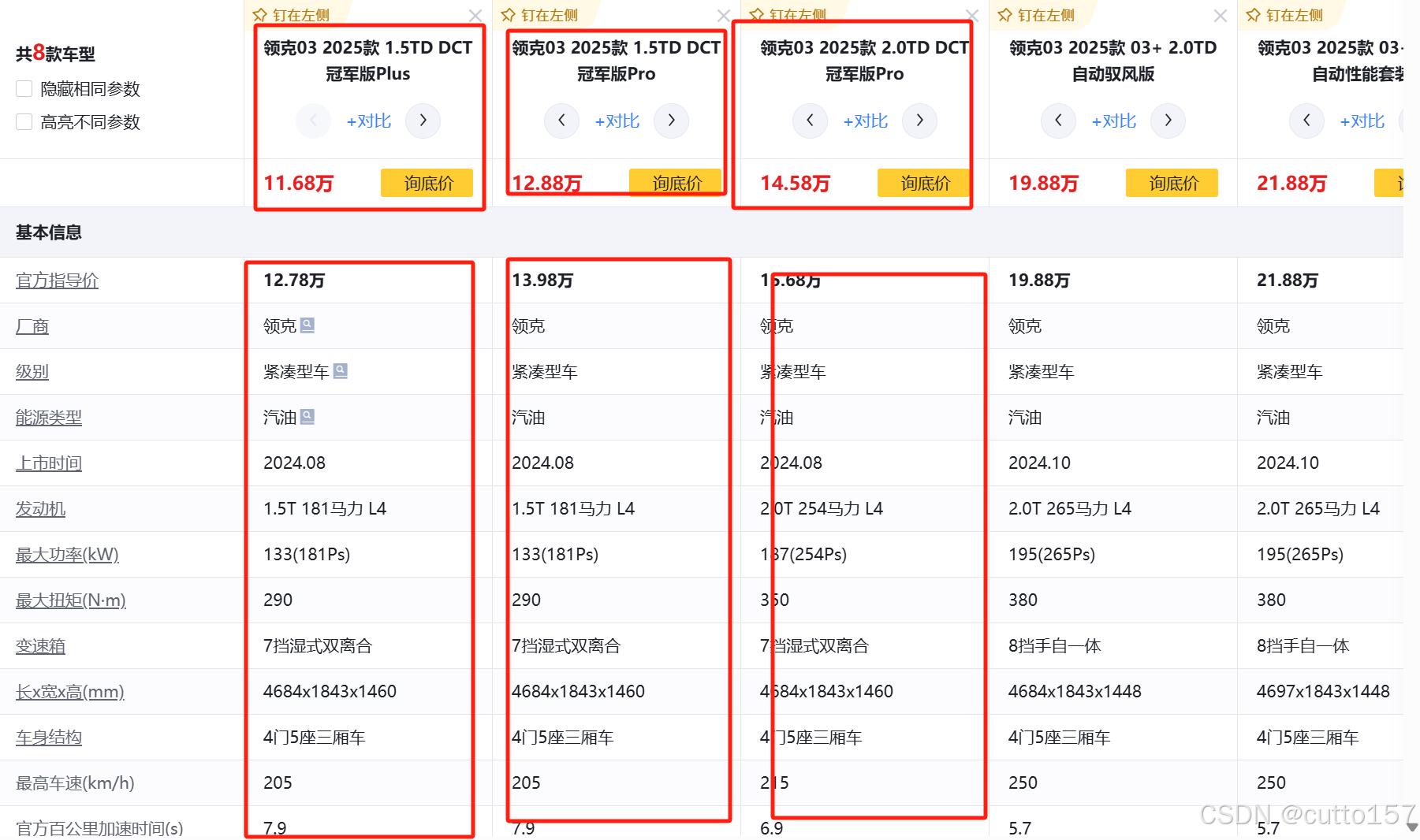
1.在选车页面,点击车型的参数,发现所有车型的数据,空白处右键,打开检查面板,选择网络选项卡,重新刷新网页,选取车名作为关键字进行搜索,发现数据嵌套在html,为静态网页。

观察请求的url,发现url中类似id的信息,以此作为思路,返回上一级查找。

2.返回上一级页面,通过昨天的内容,发现id确实是该车型的id,这样这个车型的信息就搞定了。但是后面发现,这样不利于信息的存储。于是我换了一个思路。先点开该车型的详细页面,再点击其中一个版本的参数详细。
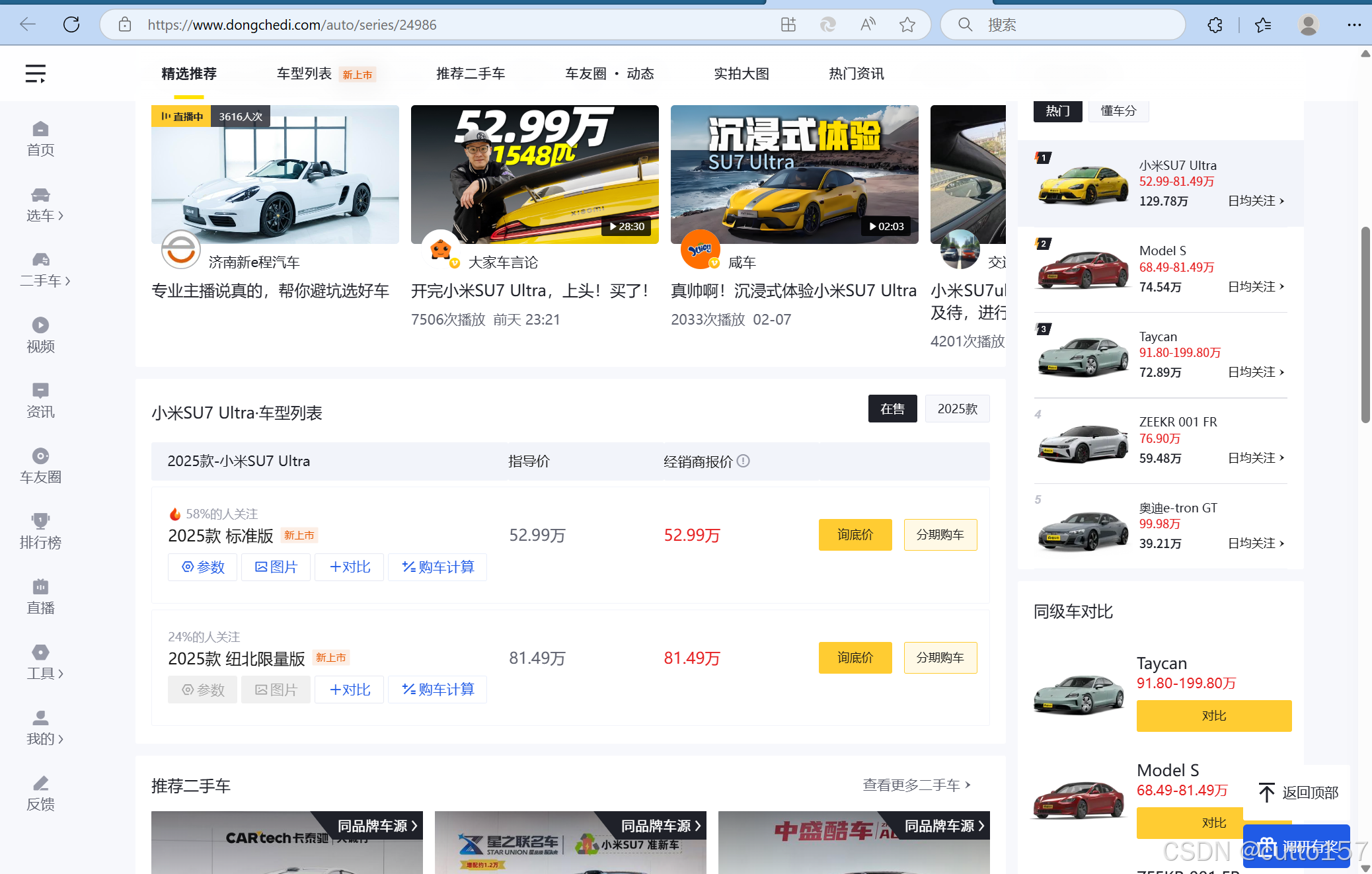
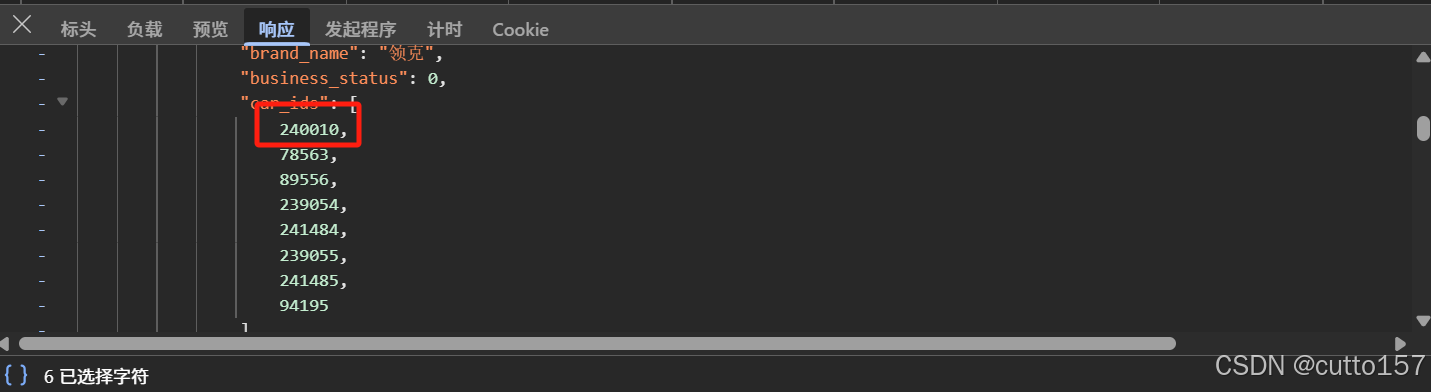
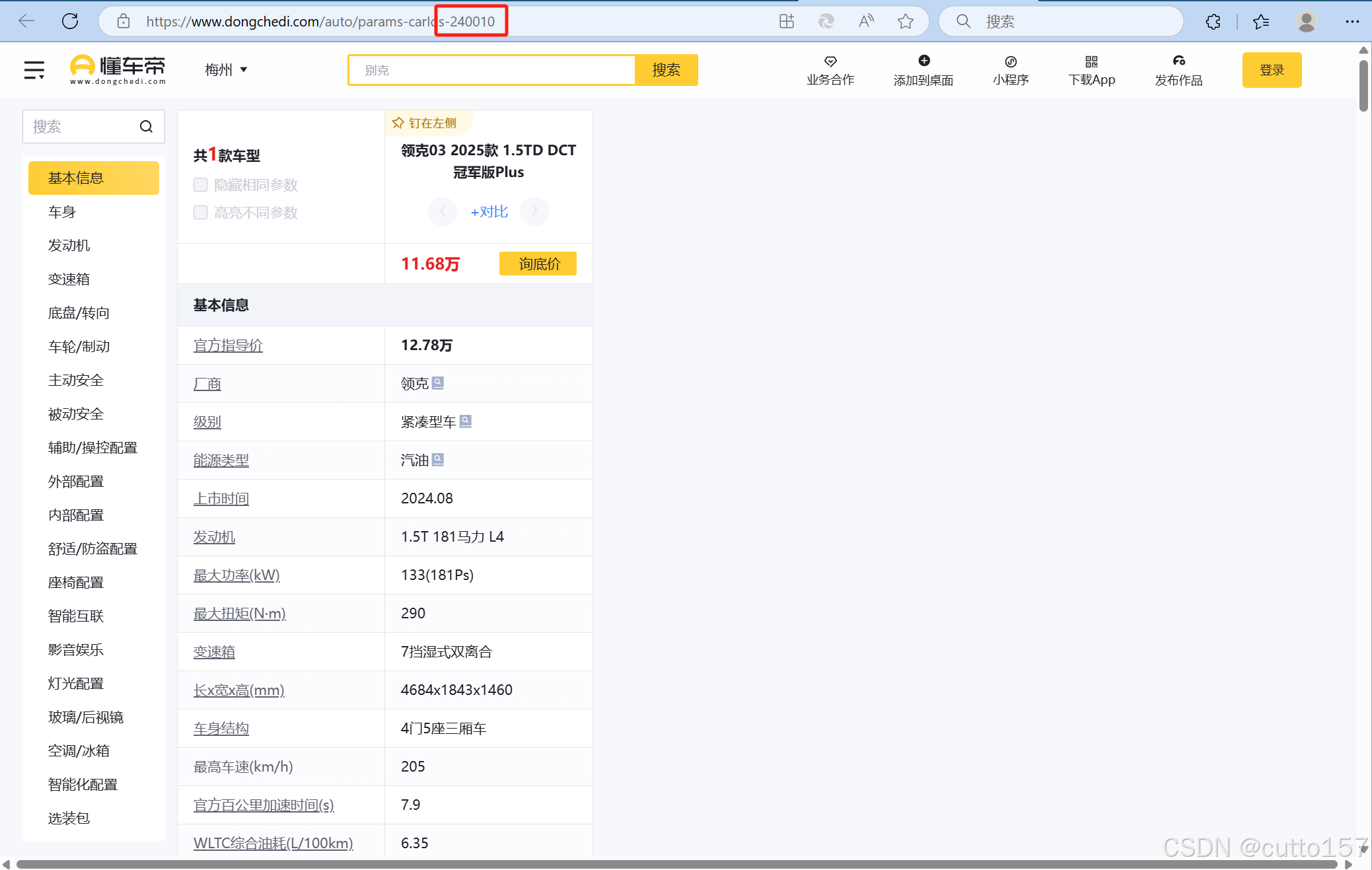
经过以上步骤,我们成功获得了特定车型的数据页面,其中URL后面的数字猜测同样表示该车型的ID。结合第一天的内容,发现数据中存在一个名为car_ids的信息,经过验证,确认其与当前URL的ID对应。接下来,按照步骤1的分析过程进行数据提取,通过品牌ID、车型ID、版本ID以及参数信息组成一条数据,这样在后面进行SQL查询时更加方便和高效。
四、完整代码
import re
from typing import Dict, Optional
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
# MongoDB 配置
MONGO_URI = "mongodb://localhost:27017/"
DB_NAME = "car_database"
COLLECTION_NAME = "car_info"
# 初始化 MongoDB 客户端
client = MongoClient(MONGO_URI)
db = client[DB_NAME]
collection = db[COLLECTION_NAME]
URL = 'https://www.dongchedi.com/motor/pc/car/brand/select_series_v2'
PARAMS = {
'aid': 1839,
'app_name': 'auto_web_pc'
}
def fetch_car_data(page: int) -> Optional[Dict]:
"""获取汽车数据"""
data = {
'sort_new': 'hot_desc',
'city_name': '梅州',
'limit': 30,
'page': page
}
try:
response = requests.post(URL, params=PARAMS, data=data, timeout=10)
response.raise_for_status()
return response.json()
except requests.RequestException as e:
print(f"请求第{page}页失败: {e}")
return None
def extract_info(body_div):
body_info = {}
if body_div:
config_block_name = body_div.find('h3', class_='cell_title__1COfA').text.strip()
rows = body_div.find_all('div', class_='table_row__yVX1h')
for row in rows:
label = row.find('label', class_='cell_label__ZtXlw')
value = row.find('div', class_='cell_normal__37nRi')
if label and value:
body_info[label.text.strip()] = value.text.strip()
return {config_block_name: body_info}
def save_to_mongodb(car_data):
"""保存提取的数据到 MongoDB"""
try:
result = collection.insert_one(car_data)
print(f"数据已保存,ID: {result.inserted_id}")
except Exception as e:
print(f"保存到 MongoDB 失败: {e}")
def main():
car_data = fetch_car_data(1)
if not car_data:
return
for car in car_data['data']['series']:
car_info = {
'brand_id': car['id'],
"brand_name": car['brand_name'],
"outter_name": car['outter_name'],
"models": []
}
for car_id in car['car_ids']:
response = requests.get(f'https://www.dongchedi.com/auto/params-carIds-{car_id}')
if response.status_code != 200:
print(f"请求失败: {response.status_code}")
continue
soup = BeautifulSoup(response.text, 'html.parser')
car_name = soup.find('a', class_='cell_car__28WzZ').text.strip()
car_price = soup.find('span', class_='cell_price__1jlTy').text.strip()
# 提取配置信息
config_info = []
for item in soup.find_all('div', attrs={'name': re.compile(r'config-body-\d+')}):
config = extract_info(item)
if config:
config_info.append(config)
# 构建汽车模型数据
model_info = {
"car_id": car_id,
"car_name": car_name,
"car_price": car_price,
"configurations": config_info
}
car_info["models"].append(model_info)
# 保存每个品牌的汽车信息到 MongoDB
save_to_mongodb(car_info)
if __name__ == "__main__":
main()
小结
有任何问题,欢迎评论。

















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









