






点击下方卡片,关注“自动驾驶之心”公众号
Foundation Models for Time Series
论文标题:Foundation Models for Time Series: A Survey
论文链接:https://arxiv.org/abs/2504.04011
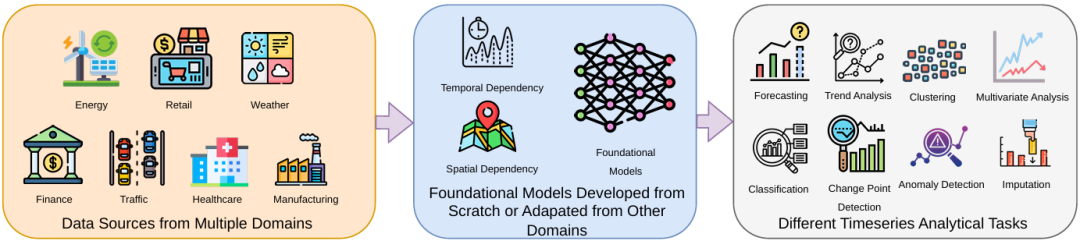
关键创新点:
1. 模型架构创新
Transformer-based时间序列建模
引入自注意力机制(Self-Attention)替代传统RNN/LSTM,解决长序列依赖问题,支持并行计算,降低时间复杂度(如Informer[50])。稀疏注意力机制
通过稀疏化自注意力(如LogSparse Attention[71]、ProbSparse Attention[50])将计算复杂度从O(n²)降至O(n),突破长序列内存瓶颈。混合架构设计
结合CNN与Transformer优势(如Time-Mixer[113]),利用卷积提取局部特征,Transformer捕获全局依赖,提升多尺度建模能力。
2. 预训练与表示学习
自监督预训练范式
采用掩码重建(Masked Reconstruction)、对比学习(Contrastive Learning)等任务,在大规模时间序列数据(如金融、医疗)上预训练,增强跨领域泛化能力[97]。多模态融合
整合时间序列与外部模态(如文本、图结构),通过跨模态注意力实现联合表示学习(如Moirai[131])。
3. 高效性与轻量化
参数高效微调(PEFT)
提出前缀调优(Prefix-Tuning)、适配器(Adapters)等策略,在下游任务中仅更新少量参数,降低计算开销[98]。轻量级架构
设计极简MLP-Mixer变体(如Tiny Time Mixers[107]),通过自适应分块(Adaptive Patching)和多分辨率采样,实现低资源环境部署。
4. 任务特定创新
概率预测与不确定性量化
采用学生T混合模型(SMM[127])或高斯 copula 输出预测分布,增强异常检测与风险评估的可靠性(如Toto[125])。长期依赖建模
引入分层注意力(Hierarchical Attention[99])和分解架构(如Autoformer[70]),分离趋势-季节性成分,提升长期预测精度。
5. 可扩展性与鲁棒性
混合专家(MoE)扩展
通过动态门控选择专家网络(如Time-MoE[123]),实现模型容量与计算效率的平衡。对抗训练与鲁棒优化
集成GAN框架(如ST-LBAGAN[78])增强缺失数据插补的鲁棒性,应对噪声与分布偏移。
6. 理论与实践结合
时间序列与NLP/CV的跨域迁移
借鉴BERT的掩码语言建模思想(如BERT4Time[134]),探索时间序列的“语义”表示学习。可解释性增强
通过注意力权重可视化和归因分析(如Grad-CAM),揭示模型决策依据,提升工业场景可信度。
Detect Anything 3D in the Wild
论文标题:Detect Anything 3D in the Wild
论文链接:https://arxiv.org/abs/2504.07958
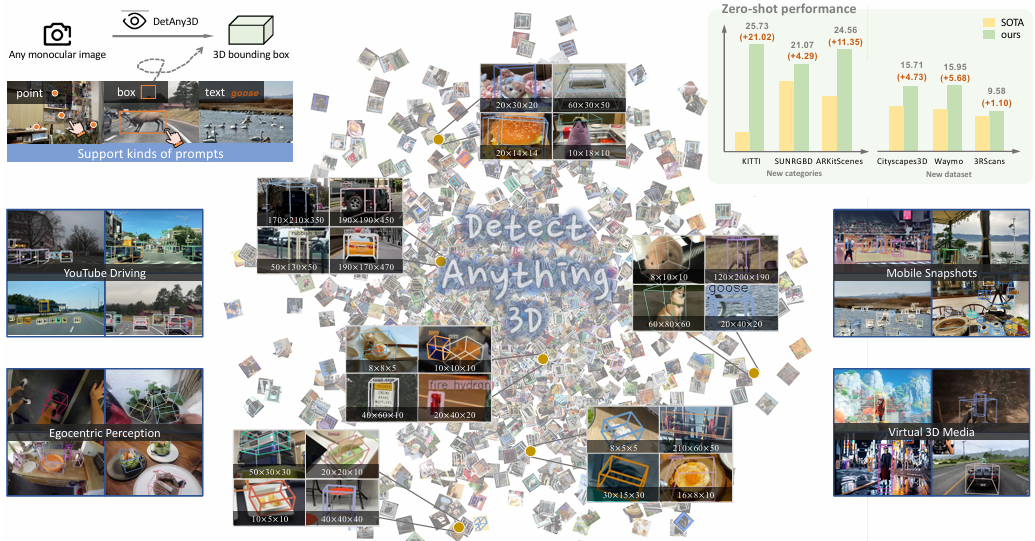
核心创新点:
1. 2D-3D知识迁移框架
双预训练模型融合 :首次联合SAM(分割)与深度预训练DINO(几何先验),通过2D Aggregator 模块实现跨模态特征对齐,动态平衡空间细节与几何语义。
零嵌入映射(ZEM)机制 :在3D解释器中引入零初始化层,渐进式注入几何信息,解决跨域(2D→3D)训练中的灾难性遗忘 问题,提升模型对新场景/相机参数的适应性。
2. 开放世界3D检测能力
多模态提示交互 :支持框/点/文本等任意提示,结合可选的相机内参输入,实现开放词汇3D检测(如罕见物体、未标注类别)。
相机自适应预测 :在无内参输入时,通过深度模块联合预测相机参数与3D框,缓解单目深度估计的病态问题。
3. 跨域泛化性增强
DA3D基准构建 :整合16个数据集(含10个新增),覆盖20种相机配置与多样化场景(室内外),规模达40万帧,支持零样本类别/相机配置评估。
零样本性能突破 :在KITTI/SUNRGBD等数据集上,对新类别AP3D提升达21.02;在Cityscapes3D/Waymo等新相机配置下,AP3D超基线4.7-5.7%。
4. 应用场景拓展
3D引导视频生成 :输出可直接作为Sora等生成模型的几何约束,提升动态场景的物理合理性(如物体位移与空间关系)。
Drive in Corridors
论文标题:Drive in Corridors: Enhancing the Safety of End-to-end Autonomous Driving via Corridor Learning and Planning
论文链接:https://arxiv.org/abs/2504.07507
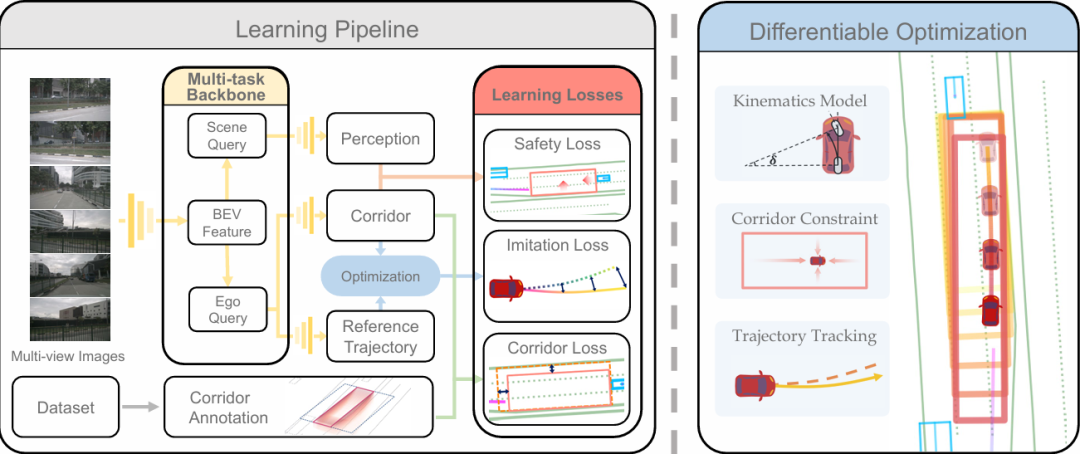
核心创新点:
1. 安全走廊的端到端集成
首次将机器人规划领域中的安全走廊(Safe Corridor)概念引入端到端自动驾驶,作为显式时空约束。通过矩形序列(每个时间戳对应BEV下的位置、朝向、尺寸)表示动态场景中的无障碍区域,解决了传统端到端方法缺乏行为约束的问题。
2. 走廊学习全流程构建
提出完整的走廊学习框架,包括:
数据标注 :基于最大空矩形(MER, Maximum Empty Rectangle)算法,结合动态障碍物(车辆、行人)和静态语义约束(车道、路沿)生成标注;
网络架构 :在VAD基础上新增走廊预测分支,输出走廊参数;
多任务损失 :设计走廊L1损失、地图/代理安全损失(基于点-矩形边缘距离)及面积正则化损失,确保走廊的准确性与安全性。
3. 可微分轨迹优化层
将走廊约束嵌入可微分二次规划(QP)优化层:
采用线性自行车动力学模型,以走廊H-表示(半空间交集)为约束,生成符合车辆运动学的轨迹;
通过隐式KKT条件反向传播梯度,首次实现优化轨迹与端到端网络的联合训练,提升可解释性。
4. 安全性与性能提升
在nuScenes数据集上实现66.7%的代理碰撞率下降 和46.5%的路沿碰撞率下降 ,并在Bench2Drive闭关测试中取得更高成功率。消融实验证明走廊约束对复杂场景(如切入、弯道)的安全轨迹生成具有关键作用。
Attention in Diffusion Model
论文标题:Attention in Diffusion Model: A Survey
论文链接:https://arxiv.org/abs/2504.03738
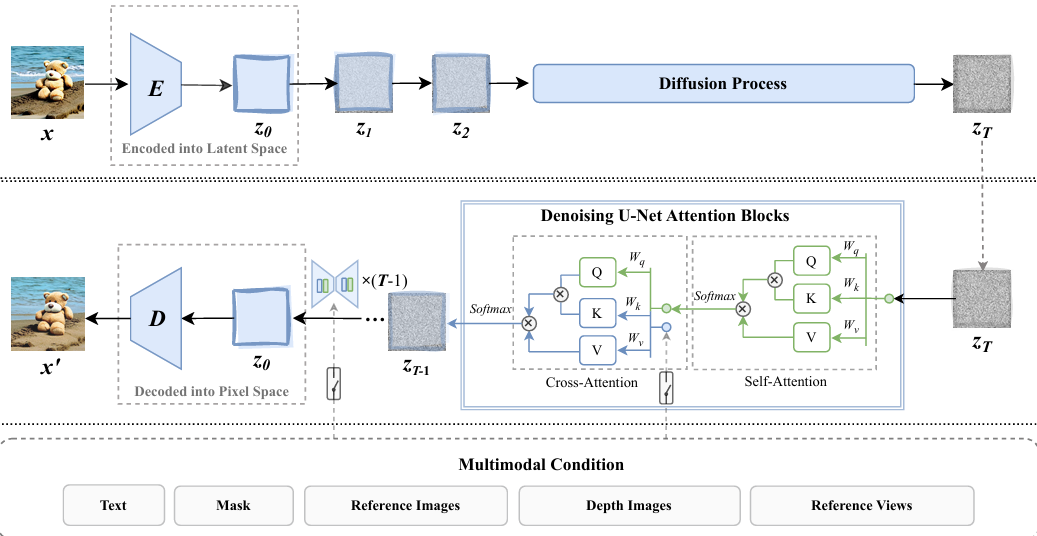
核心创新点:
1. 层级化注意力机制分类框架
首创五级分类体系(注意力图层级/权重层级/应用层级等),解构扩散模型中注意力组件的修改路径
提出「动态特征加权对齐」理论,揭示注意力机制在跨模态特征交互中的核心作用
2. 跨模态控制方法突破
Cross-Attention Map Control(P2P/BLIP-Diffusion):实现文本-图像编辑的精准空间控制
Video-P2P框架:通过时序注意力融合扩展至视频编辑,解决动态一致性难题
3D编辑创新:EditSplat提出多视角融合引导(MFG)与注意力导向修剪(AGT)方法
3. 计算效率优化技术
线性注意力机制(FlashAttention-2/QLoRA):时间复杂度从O(n²)降至O(n)
Token级优化:F3-pruning/Zero-TPrune实现训练-free的令牌剪枝策略
量化感知微调:EfficientDM解决低比特扩散模型的精度损失问题
4. 前沿领域方法论创新
多概念定制化生成:Multi-concept Diffusion突破单条件控制限制
持续学习框架:CODA-Prompt实现无回放的持续文本-图像生成
社交推荐系统:RecDiff首次将扩散模型应用于社交关系去噪推荐
Why Reasoning Matters?
论文标题:Why Reasoning Matters? A Survey of Advancements in Multimodal Reasoning (v1)
论文链接:https://arxiv.org/abs/2504.03151
核心创新点:
1. 多模态推理范式扩展
提出视觉-文本联合推理框架 ,将Chain-of-Thought(CoT)与Tree-of-Thought(ToT)扩展至多模态场景,通过分步显式推理路径 解决模态冲突问题(如LLama系列模型通过自生成路径优化)。
引入蒙特卡洛树搜索(MCTS) 与动态视觉搜索 技术,实现跨模态推理的多路径探索与最优轨迹选择(如CoMCTS、VisVM)。
2. 训练策略创新
开发强化学习与模仿学习混合策略 ,包括:
RLS3 :基于Soft Actor-Critic的视觉空间推理优化。
FuRL :双阶段对齐框架解决奖励信号稀疏性。
Thought Cloning :通过中间步骤对齐提升模仿学习效果。
提出奖励模型对齐方法 ,如CLIP-DPO(基于CLIP的偏好学习)、MMViG(细粒度视觉反馈)。
3. 模型架构突破
嵌套架构(MaGNeTS) :通过参数共享与缓存机制平衡计算效率与精度。
空间-时序建模 :
GeoGLIP :几何特征路由实现符号-视觉模态动态平衡。
VisCoT :结合目标检测与迭代裁剪的视频推理框架。
自监督视觉接地 :ROSS架构将多模态理解直接编码至模型核心,支持深度图等跨模态推理。
4. 评估体系重构
构建多维度基准 ,覆盖:
结构化推理 (Visual-RFT、STAR)
时空推理 (TemporalVQA、FrameCap)
反事实逻辑 (CounterCurate、CausalChaos!)
提出动态评估指标 ,如Recall@k与AUROC结合的MM-SAP基准,量化模型感知-认知-行动链能力。
Detect Anything 3D
论文标题:Detect Anything 3D in the Wild
论文链接:https://arxiv.org/pdf/2504.07958
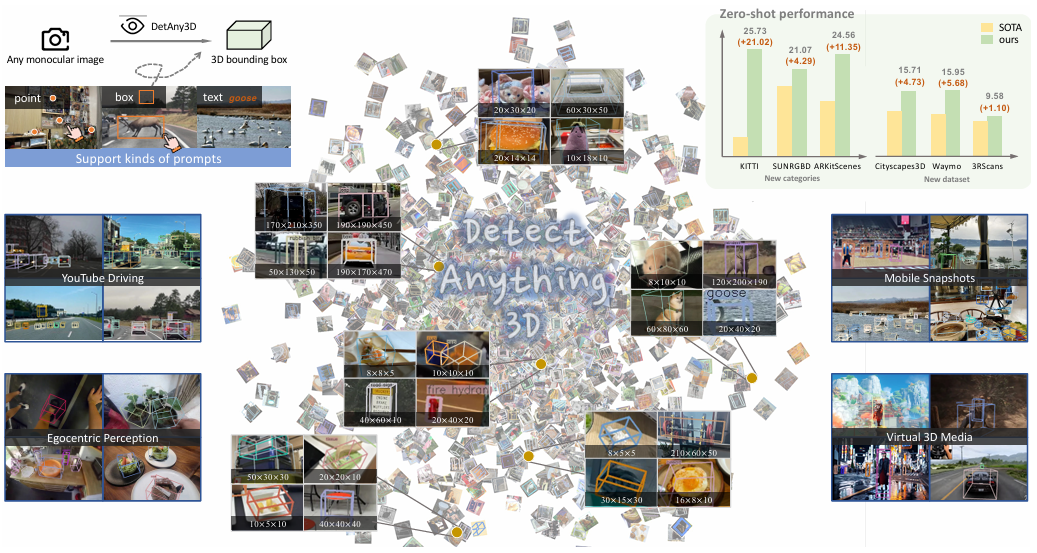
核心创新点:
1. 双模块架构实现2D到3D知识迁移
2D Aggregator :通过跨注意力机制动态融合SAM(分割)与深度预训练DINO的特征,结合低层空间细节与高层几何先验,解决异构特征冲突问题。
3D Interpreter :引入零初始化嵌入映射(Zero-Embedding Mapping, ZEM),渐进式注入几何信息,缓解跨模态训练中的灾难性遗忘,支持零样本3D定位。
2. 多提示交互与开放域检测
支持框(box)、点(point)、文本(text)多模态提示输入,结合可选相机内参约束,实现开放词汇3D检测。首次在单目输入下统一处理新类别与新相机配置的泛化问题。
3. 跨域数据整合与训练策略
构建DA3D基准,聚合16个数据集(含20种相机配置、0.4M帧),涵盖深度、内参、3D框多模态监督,解决3D标注稀缺性。
采用分层损失设计(SILog深度损失+Chamfer旋转损失)及目标感知评估指标,应对标注缺失与语义歧义问题。
4. 零样本泛化性能突破
在KITTI/SUNRGBD/ARKitScenes新类别上AP3D提升21.02/4.29/11.35,在Cityscapes3D/Waymo/3RScan新相机配置下AP3D提升5.17/5.68/1.1,验证模型在开放场景下的鲁棒性。
CAFE-AD
论文标题:CAFE-AD: Cross-Scenario Adaptive Feature Enhancement for Trajectory Planning in Autonomous Driving
论文链接:https://arxiv.org/pdf/2504.06584
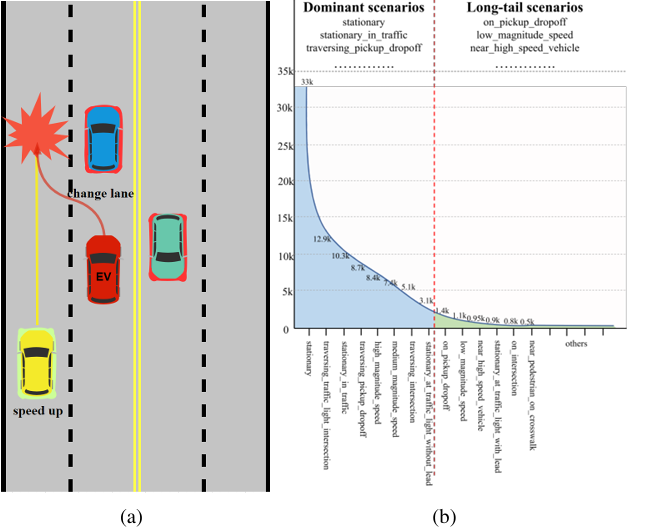
核心创新点:
1. 自适应特征剪枝模块(Adaptive Pruning Transformer Encoder)
基于Transformer的动态剪枝机制,通过注意力概率对场景特征(如动态障碍物、地图元素)进行重要性排序,自适应地剪除与当前规划任务无关的冗余token及注意力连接。
通过保留关键因果特征(如与规划决策强相关的障碍物),显著降低开放环路训练中的因果混淆(causal confusion)问题,提升模型对动态场景的因果推理能力。
2. 跨场景特征插值模块(Cross-Scenario Feature Interpolation)
引入场景分类器将特征分解为场景相关特征 (scenario-relevant)与通用特征 (scenario-generic),通过跨场景的特征插值增强训练数据多样性。
针对长尾分布(long-tail distribution)问题,对主导场景(如静态场景)的特征进行跨类别插值,强制模型学习跨场景的泛化表示,缓解对高频场景的过拟合。
3. 联合优化框架
结合上述模块,在nuScenes和nuPlan数据集上实现闭环仿真性能的显著提升(Test14-Hard基准上CLS-R评分超SOTA方法2.81),并在真实场景验证了鲁棒性。
方法兼容性高,可集成至现有规划网络(如PLUTO、PlanTF),提升其抗干扰能力与场景适应性。
本文均出自『自动驾驶之心知识星球』硬核资料在星球置顶链接,加入即可获取:
行业招聘信息&独家内推;
自驾学习视频&资料;
前沿技术每日更新;




















 4283
4283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









