






作者 | 黄浴 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1892243273671738953
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『扩散模型』技术交流群
本文只做学术分享,如有侵权,联系删文
25年3月来自酷睿程 Carizon 和北航的论文“DiffAD: A Unified Diffusion Modeling Approach for Autonomous Driving”。
端到端自动驾驶 (E2E-AD) 已迅速成为实现完全自动驾驶的一种有前途的方法。然而,现有的 E2E-AD 系统通常采用传统的多任务框架,通过单独的特定任务头来处理感知、预测和规划任务。尽管以完全可微分的方式进行训练,但它们仍然遇到任务协调问题,并且系统复杂性仍然很高。这项工作引入 DiffAD——一种扩散概率模型,它将自动驾驶重新定义为条件图像生成任务。通过将异构目标栅格化到统一的鸟瞰图 (BEV) 上并对其潜分布进行建模,DiffAD 统一各种驾驶目标并在单一框架中联合优化所有驾驶任务,显着降低系统复杂性并协调任务协调。逆过程迭代细化生成的 BEV 图像,从而产生更稳健和逼真的驾驶行为。
实现全自动驾驶不仅需要对复杂场景有深入的理解,还需要与动态环境进行有效的交互,并全面学习驾驶行为。传统的自动驾驶系统建立在模块化架构之上,感知、预测和规划都是独立开发的,然后集成到车载系统中。虽然这种设计提供可解释性并方便调试,但跨模块的单独优化目标往往会导致信息丢失和错误积累。
最近的端到端自动驾驶 (E2E-AD) 方法(例如 [3、16、20])试图通过实现所有组件的联合、完全可微分训练来克服这些限制,如图 (a) 所示。然而,仍然存在几个关键问题:
次优优化:像 UniAD [16] 和 VAD [20] 这样的方法仍然依赖于顺序流水线,其中规划阶段取决于前面模块的输出。这种依赖性可能会放大整个系统的错误。
-
查询建模效率低下:当前基于查询的方法(例如 [16, 20])部署数千个可学习查询来捕获潜在的交通元素。这种方法导致计算资源分配效率低下,过多关注上游辅助任务而不是核心规划模块。例如,在 VAD 中,感知任务消耗了总运行时间的 34.6%,而规划模块仅占 5.7%。
-
协调复杂性:由于每个任务头都使用不同的目标函数独立优化,并且目标的形状和语义含义各不相同,因此整个系统变得支离破碎,难以进行连贯训练 [5]。
为了解决这些限制,本文提出一种范式 DiffAD,它将所有驾驶任务的优化统一到一个模型中,如图 (b) 所示。具体来说,将感知、预测和规划中的异构目标栅格化到统一的鸟瞰图 (BEV) 空间中,从而将自动驾驶问题重塑为条件图像生成问题之一。
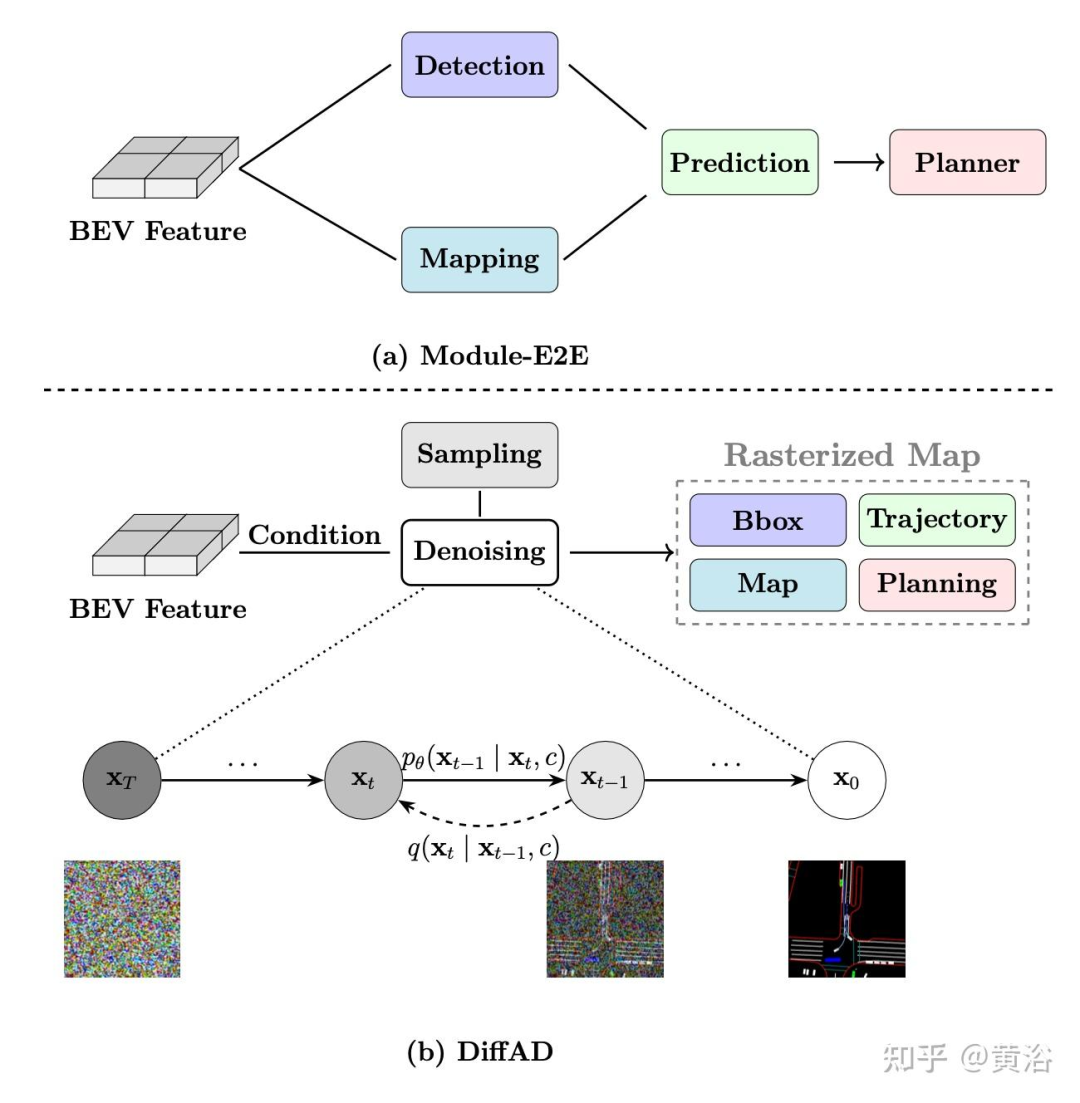
扩散模型,也称为基于分数的生成模型 [14, 39, 42],在正向(扩散)过程中逐渐将噪声注入数据,并通过反向(去噪)过程从噪声中生成数据。
如图所示,DiffAD 由三个主要组件组成:潜在扩散模型、BEV 特征生成器和轨迹提取网络 (TEN)。
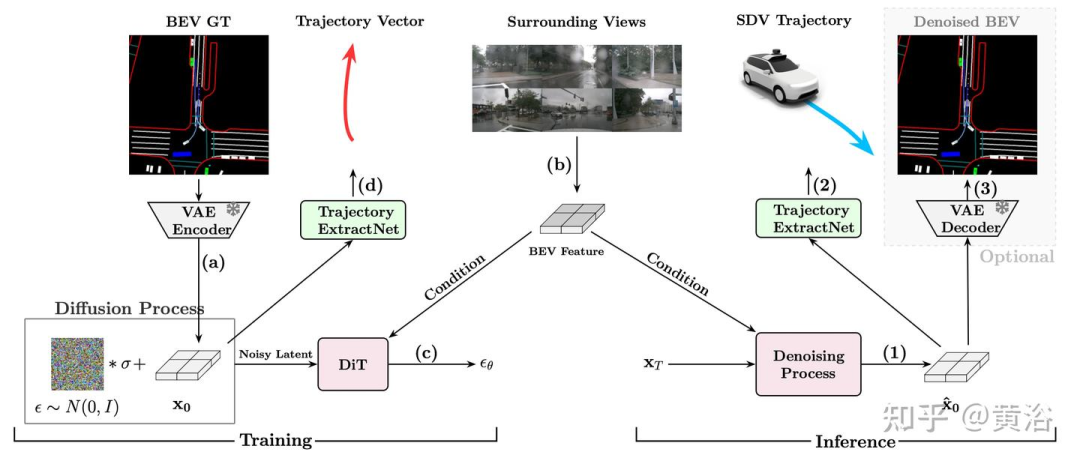
训练过程:
栅格化和潜空间编码:DiffAD 首先将感知、预测和规划目标栅格化为 BEV 图像。然后使用现成的 VAE 编码器将 BEV 图像压缩到潜空间以进行降维。
特征提取和转换:将周围视图图像输入到特征提取器中,该提取器将生成的透视图特征转换为统一的 BEV 特征。
用于噪声预测的扩散模型:将高斯噪声添加到潜 BEV 图像中以获得噪声潜图像。训练扩散模型以根据 BEV 特征预测来自噪声潜表示的噪声。
轨迹提取:训练基于查询的 TEN,从潜 BEV 图像中恢复自我智体的矢量化轨迹。
推理过程:
条件去噪:DiffAD 首先根据 BEV 特征,从纯高斯噪声中生成去噪的潜 BEV 图像。
规划提取:TEN 然后从潜 BEV 图像中提取自智体的规划轨迹。
解码 BEV:通过将潜 BEV 图像解码回像素空间,可以获得预测的 BEV 图像以供解释和调试。
据说开环评估不足以满足 E2E 模型的要求 [19, 26]。为了解决这个问题,用 Bench2Drive 数据集在 CARLA 模拟器中进行训练和闭环评估[8]。Bench2Drive 提供三个数据子集:mini(10 个剪辑用于调试)、base(1,000 个剪辑)和 full(10,000 个剪辑用于大规模研究)。按照 [19] 的方法,用基础子集进行训练。
训练。用来自 Stable Diffusion[36] 的现成预训练变分自动编码器 (VAE) 模型 [23]。VAE 编码器的下采样因子为 8。在所有实验中,扩散模型都在潜空间中运行。保留来自 DiT [34] 的扩散超参。为了促进学习过程,在第一阶段从感知部分(即检测和地图)的单幅图像学习开始,而预测和规划 BEV 图像则用零填充。然后在时间设置中与所有感知、预测和规划部分联合训练模型。
推理。利用 DDIM-10 采样器 [40] 进行推理,并使用官方评估工具 [19] 来计算闭环指标。对于车辆控制,采用官方提供的 PID 控制器。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 3513
3513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









