





导 读
本文主要介绍新的YOLO目标检测模YOLO-NAS以及如何使用YOLO-NAS做推理预测。
背景介绍
开发一种新的基于 YOLO 的架构可以通过解决现有的局限性并结合深度学习的最新进展来重新定义最先进的 (SOTA) 对象检测。深度学习公司 Deci.ai 最近推出了 YOLO-NAS。这种深度学习模型提供卓越的实时对象检测能力和高性能,可用于生产。这些 YOLO-NAS 模型是使用 Deci 的 AutoNAC™ NAS 技术构建的,性能优于 YOLOv7 和 YOLOv8 等模型,包括最近推出的 YOLOv6-v3.0。

我们可以使用OpenCV提供的中值滤波函数就可以轻松将噪声滤除,并较好地保留图像边缘特征。
什么是YOLO-NAS
YOLO-NAS是一种新的实时最先进的对象检测模型,在 mAP(平均精度)和推理延迟方面优于YOLOv6和YOLOv8模型。
,时长00:05
开发一种新的基于 YOLO 的架构可以通过解决现有的局限性并结合深度学习的最新进展来重新定义最先进的 (SOTA) 对象检测。
YOLO-NAS 是 Deci.ai 的一种新的对象检测基础模型。该团队结合了深度学习的最新进展,以找出并改进当前 YOLO 模型的一些关键限制因素,例如量化支持不足和准确度-延迟权衡不足。通过这样做,该团队成功地突破了实时对象检测功能的界限。

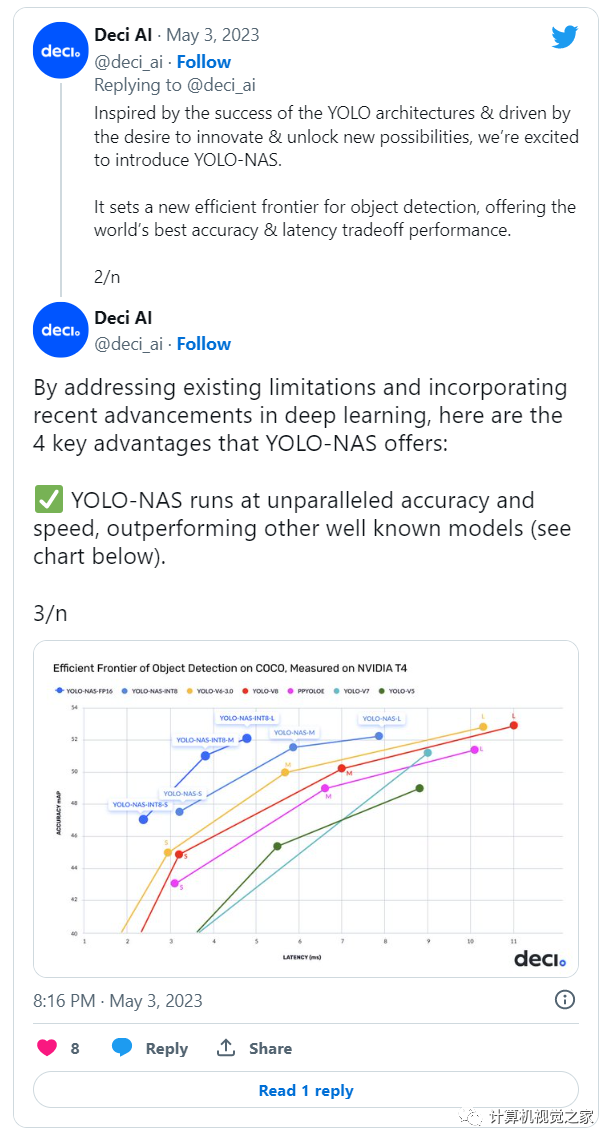

截至撰写本文时,已经发布了三种 YOLO-NAS 模型,可用于FP32、FP16和 INT8精度。截至撰写本文时,已经发布了三种 YOLO-NAS 模型,可用于FP32、FP16 和 INT8 精度。

Mean Average Precision (mAP)是评估机器学习模型的性能指标。
目前,YOLO-NAS 模型架构在开源许可下可用,但预训练的权重仅可用于 Deci 的 SuperGradients 库的研究用途(非商业)。
YOLO-NAS中的“NAS”代表什么
“NAS”代表“神经架构搜索”,这是一种用于自动化神经网络架构设计过程的技术。NAS 不依赖手动设计和人类直觉,而是采用优化算法来发现最适合给定任务的架构。NAS 的目标是找到一种在准确性、计算复杂性和模型大小之间实现最佳权衡的架构。
YOLO-NAS 的一些关键架构见解
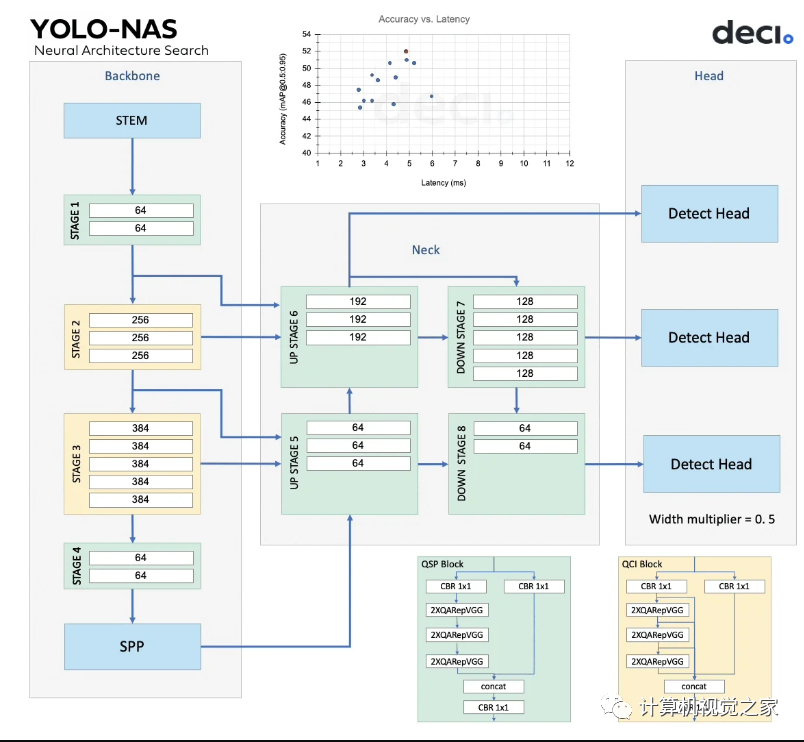
YOLO-NAS 模型的架构是使用 Deci 的专有 NAS 技术AutoNAC “发现”的。该引擎用于确定阶段的最佳大小和结构,包括块类型、块数和每个阶段中的通道数。
NAS 搜索空间中总共有10的14次方种可能的架构配置。作为硬件和数据感知,AutoNAC 引擎考虑了推理堆栈中的所有组件,包括编译器和量化,并磨练到称为“效率边界”的区域以找到最佳模型。所有三个 YOLO-NAS 模型都在搜索空间的这个区域中找到。
在整个NAS 过程中,Quantization-Aware RepVGG (QA-RepVGG) 块被合并到模型架构中,保证了模型与 Post-Training Quantization (PTQ) 的兼容性。
使用由 QA-RepVGG 块组成的量化感知“QSP”和“QCI”模块可提供 8 位量化和重新参数化优势,从而在 PTQ 期间实现最小的精度损失。
研究人员还使用了一种混合量化方法,可以选择性地量化特定层,以优化准确性和延迟权衡,同时保持整体性能。
YOLO-NAS 模型还使用注意力机制和推理时间重新参数化来提高目标检测能力。
YOLO-NAS模型训练小结
在撰写本文时,尚未公布整个训练方案的全部细节。一旦有论文或任何新信息可用,我们将更新此部分。从我们从他们的官方新闻稿中收集到的信息来看,这些模型经历了连贯且昂贵的训练过程。
这些模型在著名的 Object365 基准数据集上进行了预训练。由 2M 图像和 365 个类别组成的数据集。
“伪标记”123k COCO 未标记图像后的另一轮预训练。
还结合了知识蒸馏 (KD) 和分布焦点损失 (DFL) 以增强 YOLO-NAS 模型的训练过程。

在对模型进行预训练后,作为一项实验,该团队决定在 RoboFlow的“RoboFlow100 数据集”上测试性能,以展示其处理复杂物体检测任务的能力。不用说,YOLO-NAS 的性能大大优于其他 YOLO 版本。

如何使用YOLO-NAS进行推理
要使用YOLO-NAS模型,我们首先需要安装一些库。在新的开发环境中,执行以下Python安装命令:
pip install -qU super-gradients imutilspip install -qU roboflowpip install -qU pytube
“super-gradients”包将安装所有必需的包,例如 PyTorch 和 TorchVision,以及 Cuda 支持和其他必要的库。
对象检测推理
为了进行推理,首先,我们将导入两个必要的包:
import torchfrom super_gradients.training import models
对图像进行推理非常容易。以下命令加载模型YOLO-NAS S小型模型。
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")model = models.get("yolo_nas_s", pretrained_weights="coco").to(device)# "yolo_nas_m"# "yolo_nas_l"
我们正在经典的对象检测测试图像上测试模型。我们需要调用模的.predict(...)方法来执行推理。
out = model.predict("test_1.jpg", conf=0.6)最后,要可视化输出,只需运行:out.show()

要保存预测图像,请调用:
out.save("save_folder_path")同样,为了对视频进行推理,API 调用保持不变。只有这一次,我们将使用最大的可用模型。
model = models.get("yolo_nas_l", pretrained_weights="coco").to(device)model.predict("/test_videos/kitchen_small_items.mp4").save("kitchen_small_items_detections.mp4")
,时长00:30
在免费的 Colab T4 GPU 上,该推理以约 22 次迭代/秒的速度运行,即 22 FPS。30 秒的视频大约需要 35 秒才能完全处理。
请注意,(目前)我们没有将模型与 YOLOv8 和 YOLOv6 进行具体比较,因为尽管 YOLO-NAS 模型在数量上更好,但差距很小。我们尝试进行的任何比较在影响方面都是最小的。准确的比较将在 YOLO-NAS 系列的下一篇文章中进行,我们将在自定义任务上训练这些模型,并记录与当前巨头相比训练的难易程度和质量。
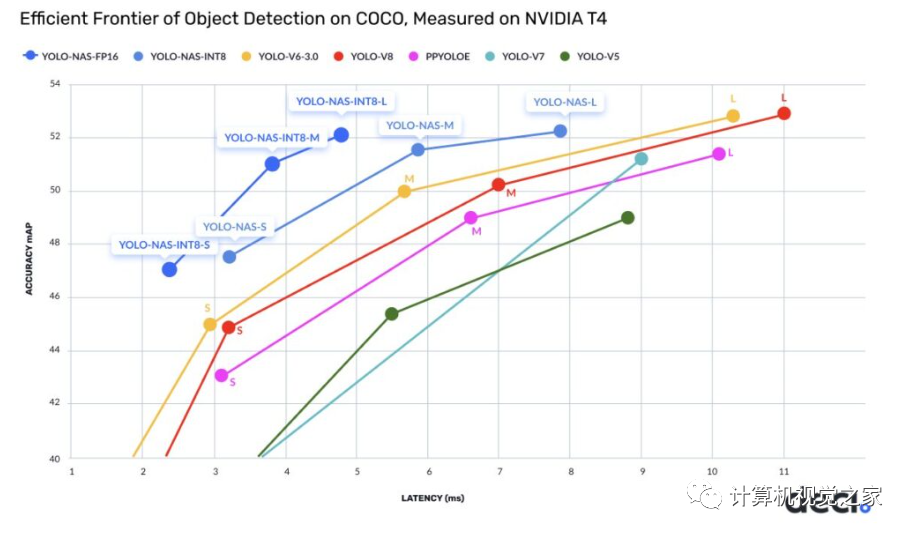
下表列出了 YOLOv6 3.0、YOLOv8 和 YOLO-NAS 的所有指标:

总 结
在计算机视觉和深度学习领域不懈的研究和创新的推动下,最先进的对象检测 (SOTA) 模型的前景在不断发展。最近,YOLOv6 和 YOLOv8 被认为是公开可用的最佳实时对象检测模型。最近,Deci.ai 的新竞争模型“YOLO-NAS”在提供更好的实时对象检测功能方面位居榜首。
在本文中,我们探索了最新的 YOLO 模型,即 YOLO-NAS。我们简要介绍了这些新模型及其性能的探索和训练细节。此外,我们还对视频进行了推理。














 2293
2293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









