







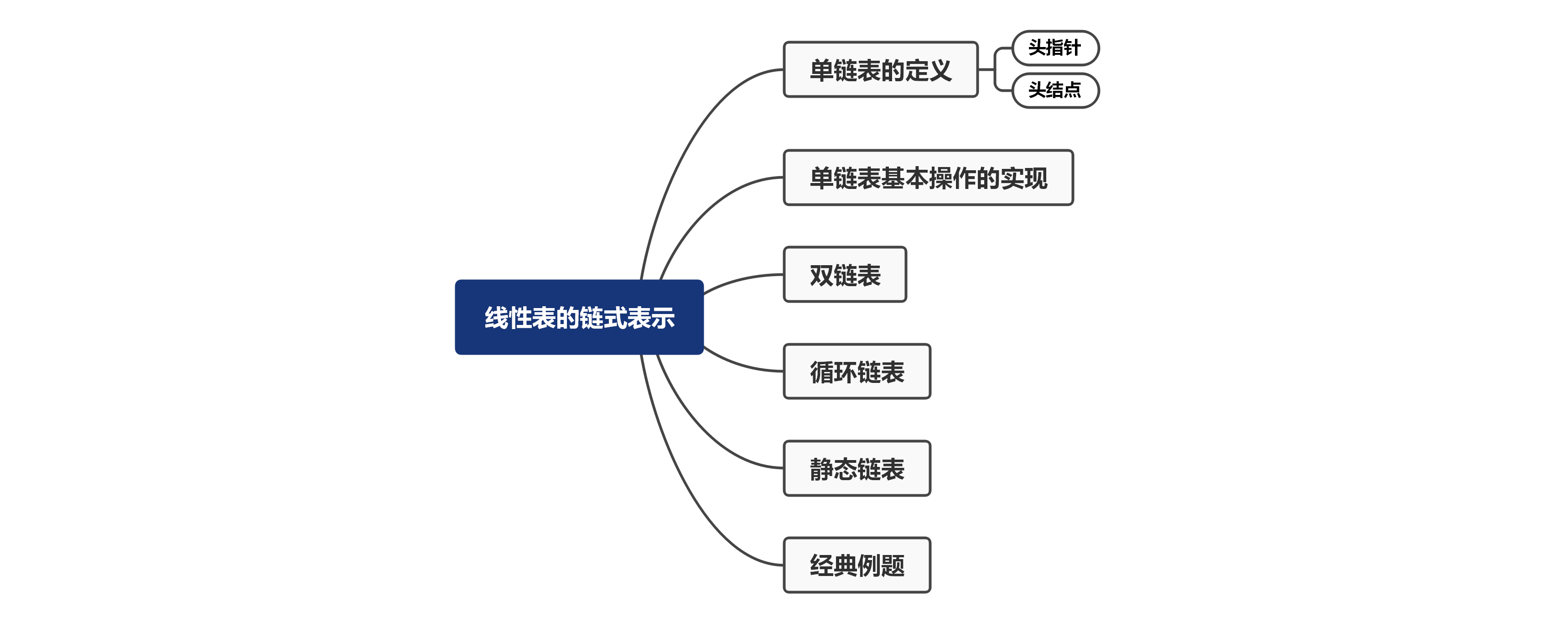
目录
一、单链表的定义
通过一组任意的存储单元来存储线性表中的数据元素
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;对上述代码进行简单说明,LNode和*LinkList都是结构体LNode的别名,定义两个别名的目的是,LNode用来定义结点,而LinkList用来作为头指针的定义 ElemType是一个抽象概念,就是代表任意数据类型的意思,在实际操作中不存在这个类型,只是描述算法中使用,具体场景中使用int、char等真实存在的数据类型进行替换即可
(一)头指针
通常用头指针来标识一个单链表,如单链表L,头指针为NULL时标识一个空表
不论有无头结点,头指针都始终指向链表的第一个结点
(二)头结点

头结点的数据域可以不设任何信息,也可以记录表长等信息
- 链表的第一个位置上的操作和其他位置的操作一致,无需特殊处理
- 无论链表是否为空,其头指针都指向头结点的非空指针,因此空表和非空表的处理得到了统一
判断是否带头结点,就看有没有给头指针申请分配内存
二、单链表基本操作的实现
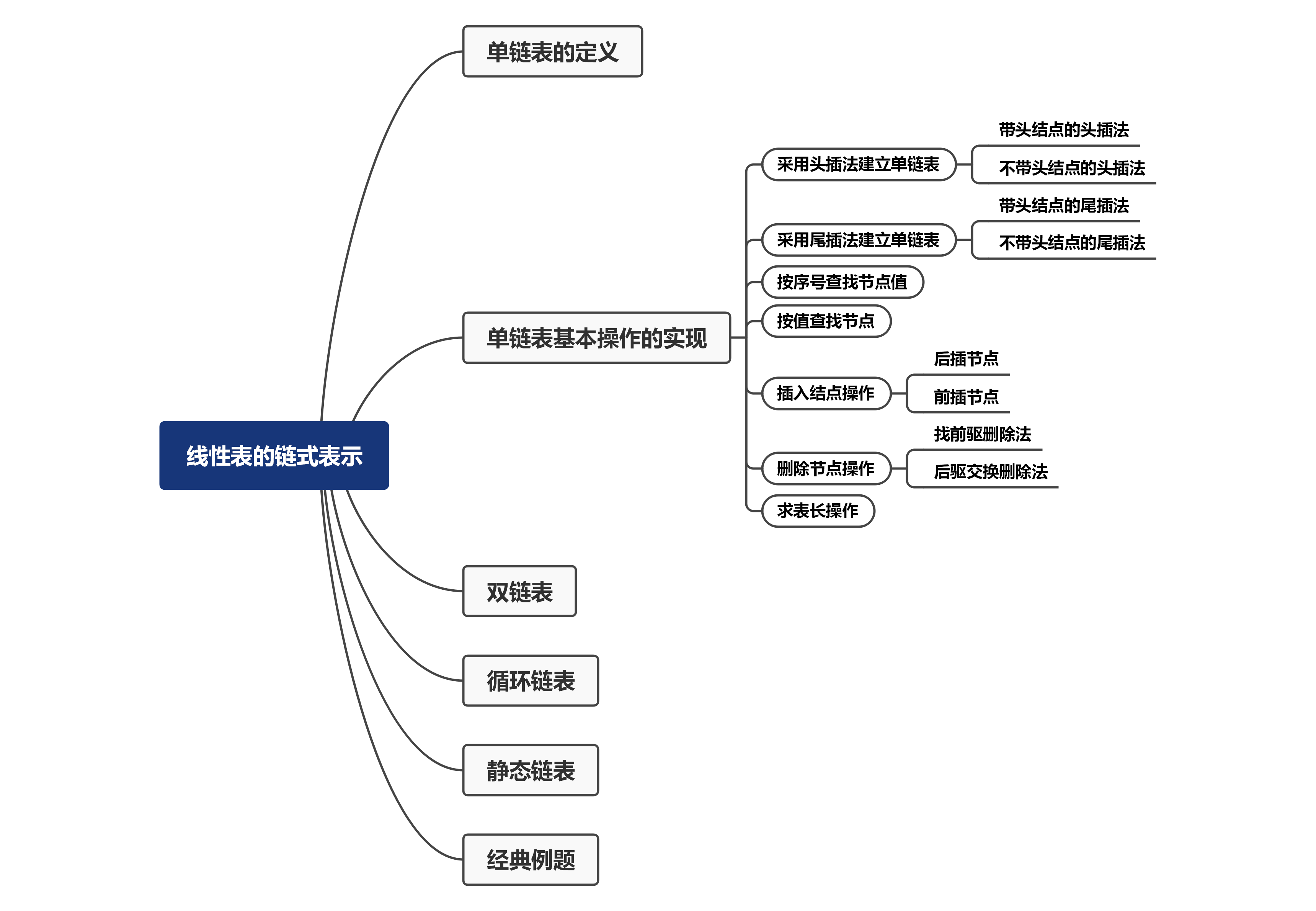
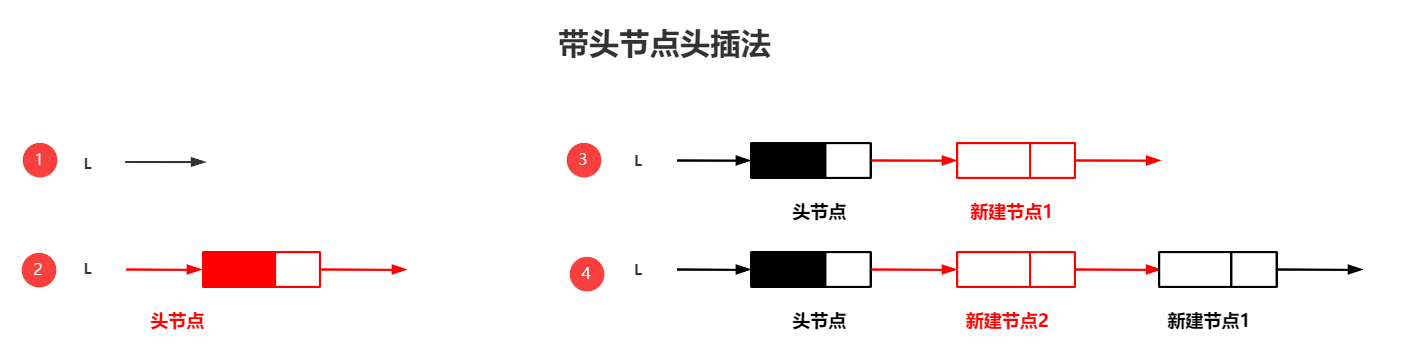
(一)采用头插法建立单链表
1.带头结点的头插法算法思路:
①先申请一个头指针并将其指向空地址
②将头指针指向头结点
也就是给头指针分配内存,此时头指针的值就是malloc分配的内存空间的地址值,也就是头指针指向头结点
③创建新的节点,将读取到的数据存放到新节点的数据域中
再申请一个指针,给指针分配内存就算完成创建了
④将新节点插入到头结点后面
先头结点指向新节点,再把新节点指向 原本头结点指向的位置
⑤然后重复第③、④步以此循环
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
void List_HeadInsert(LinkList &L)
{
LNode *s;
int x;
L = (LinkList)malloc(sizeof(LNode)); //创建头结点
L->next = NULL; //初始为空链表
scanf("%d",&X); //输入节点的值
while(x != 9999) //输入9999表示结束
{
s = (LNode*)malloc(sizeof(LNode)); //创建新节点
s->data = x;
s->next = L->next;
L->next = s; //新节点插入表中,L为头指针
scanf("%d",&x);
}
return L;
}
int main()
{
LinkList L = NULL; //空链表初始化
List_HeadInsert(&L);
return 0;
}2.不带头结点的头插法算法思路:
①先申请一个头指针并将其指向空地址
②创建一个新节点并为其赋值
再申请一个指针,给指针分配内存就算完成创建了
③将新节点插入到头指针后面
判断头指针是否为空指针,如果是,把头指针指向新节点;
若不是,则把新建节点指向原本头指针指向的节点,头指针指向 新建节点
④重复第②、③步以此循环

typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
void NoNode_HeadInsert(LinkList &L)
{
//初始化链表
LNode *s; //要插入的节点
ElementType x; //要插入的数据
scanf("%d", &x);
while (x != 999)
{
s = (LNode*)malloc(sizeof(LNode));
s->data = x;
s->next = NULL;
if (NULL == L)
{
L = s; //将新结点置位首节点也是尾结点
}
else
{
s->next = L;
L = s; //新结点置位尾结点
}
scanf("%d", &x);
}
}
int main()
{
LinkList L = NULL; //空链表初始化
NoNode_HeadInsert(&L);
return 0;
}(二)采用尾插法建立单链表
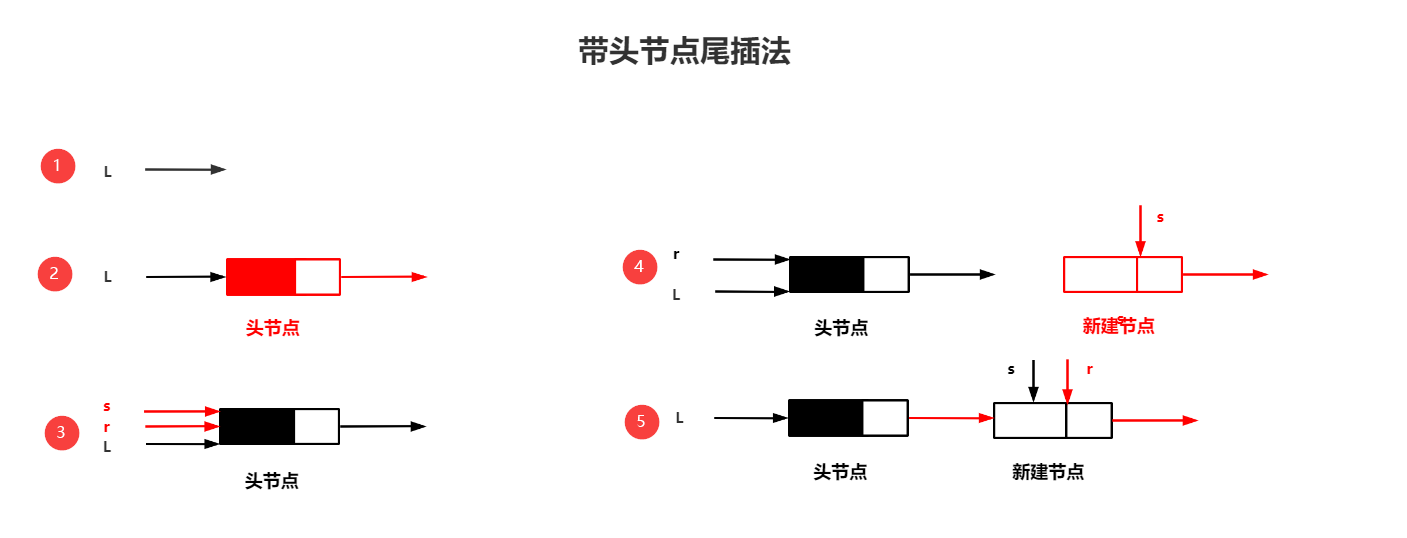
1.带头结点的尾插法算法思路:
①先申请一个头指针并将其指向空地址
②将头指针指向头结点
也就是给头指针分配内存,此时头指针的值就是malloc分配的内存空间的地址值,也就是头指针指向头结点
③创建一个表尾指针
意思就是表尾指针初始化指向头结点,第一次使用时可充当头指针的作用
④新建一个结点并为其赋值
再申请一个指针,给指针分配内存就算完成创建了
⑤将新节点挂在表尾
用表尾指针将表尾结点指向新节点,然后再将表尾指针指向新建节点即可
⑥重复④、⑤,以此循环
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
void List_TailInsert(LinkList &L)
{
int x;
L = (LinkList)malloc(sizeof(LNode));
LNode *s,*r = L;
scanf("%d",&x);
while(x != 9999)
{
s = (LNode *)malloc(sizeof(LNode)); //创建新节点
s->data = x;
r->next = s;
r = s;
scanf("%d",&x);
}
r->next = NULL;
}
int main()
{
LinkList L = NULL; //空链表初始化
List_TailInsert(&L);
return 0;
}上述代码可能有个容易被误导的地方, s = (LNode *)malloc(sizeof(LNode)),明明前面定义时LNode *s,*r = L将头结点的地址赋给s了,而且头结点也已经完成了内存分配创建,s与L值一样的怎么能再次分配内存。malloc函数是随机分配一块内存并且把该内存的地址赋给指针s,而不是给s原本的地址赋值,也就是说这里指针定义的时候可以不用LNode *s = L,直接LNode *s也没关系,当然LNode *r = L这一步是不能不赋值的
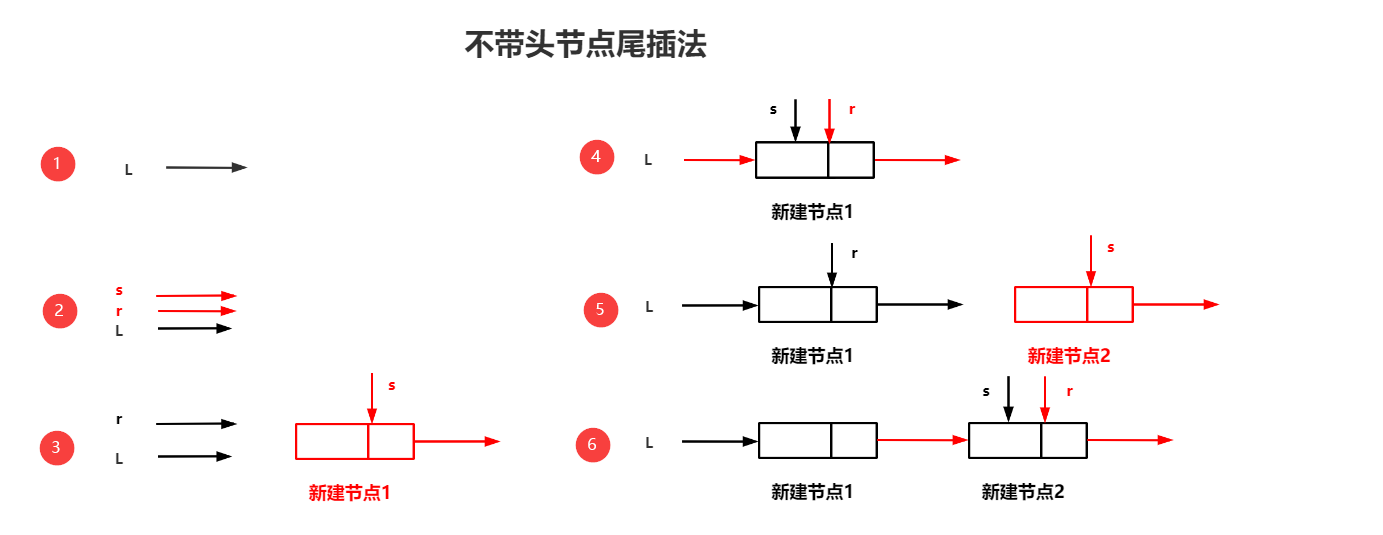
2.不带头结点的尾插法算法思路:
①先申请一个头指针并将其指向空地址
②创建一个表尾指针
意思就是表尾指针初始化指向头结点,第一次使用时可充当头指针的作用
④新建一个结点并为其赋值
再申请一个指针,给指针分配内存就算完成创建了
⑤将新节点挂在表尾
用表尾指针将表尾结点指向新节点,然后再将表尾指针指向新建节点即可
⑥重复④、⑤,以此循环
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
void NoNode_TailInsert(LinkList *L) {
ElementType x; //要插入的元素
LNode *s; //要插入的节点
LNode *r; //尾指针
scanf("%d", &x);
while (x != 9999) {
s = (LNode *) malloc (sizeof(LNode));
s->data = x;
s->next = NULL;
if (NULL == L) //链表是否为空
{
L = s; //将新结点置位首节点也是尾结点
r = L;
}
else
{
r->next = s;
r = s; //新结点置位尾结点
}
scanf("%d", &x);
}
}
int main()
{
LinkList L = NULL; //空链表初始化
NoNode_TailInsert(&L);
return 0;
}(三)按序号查找节点值
- 先判断序号是否合法
序号为0,直接传出头结点,为小于0的数则返回NULL
- 再往下进行循环
关键就在哪里停下来,满足节点不为空并且序号等于输入值的时候
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
LNode *GetElem(LinkList L,int i)
{
int j = 1;
LNode *p=L->next; //头结点赋给p
if(i == 0)
return L;
if(i<1)
return NULL //若i无效,则返回NULL
while(p&&j < i)
{
p=p->next;
j++;
}
return p;
}
int main()
{
LinkList L = NULL; //空链表初始化
LNode *x;
x = GetElem(L,5);
return 0;
}查找的时候,带头结点的,头结点为第0个节点,第一个带数据的节点才是第1个结点
(四)按值查找节点
循环对比值即可
循环条件是不为空并且值不等于输入的值
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
LNode *LocateElem(LinkList L,ElemType e)
{
LNode *p = L->next;
while(p!=NULL&&p->data!=e) //循环条件是不为空以及值不等于要找的
p = p->next;
return p;
}
int main()
{
LinkList L = NULL; //空链表初始化
LNode *x;
x = LocateElem(L,e);
return 0;
}(五)插入结点操作
1.后插节点
- 先将新节点通过第一个结点指向下第二个节点
- 再将第一个结点指向新结点
p = GetLem(L,i-1);
s->next = p->next;
p->next = s;顺序不能颠倒,如果颠倒了,就找不到第二个节点在哪了
2.前插节点
普通的前插节点要从头找该节点的前一个结点,插入时间复杂度为O(n),因此使用后插法再加上交换数据域方式来实现,时间复杂度为O(1)
s->next = p->next;
p->next = s;
temp = p->data;
p->data = s->data;
s->data = temp;(六)删除节点操作
1.找前驱删除法
①删除节点
先查找要删除位置的前驱节点,然后把前驱节点直接指向要删节点的后继节点
②释放删除节点空间
使用free函数
p = GetElem(L,i-1);
q = p->next;
p->next = q->next;
free(q);2.后驱交换删除法
①找到要删除的节点位置
②要删节点与其后驱节点交换数据域
③删除后驱节点即可
q = p->next;
p->data = p->next->data;
p->next = q->next;
free(q);(七)求表长操作
先从头指针定位到头结点,然后一直循环往后查找到为空
链表长度不包括头结点
三、双链表

(一)双链表的定义
产生原因,单链表在某个节点只能找到后继节点,找前驱节点必须从头开始找,因此诞生了部分后驱节点交换数据域的算法。直接再设置一个前驱节点就完事了,这就是双链表
typedef struct DNode
{
ElemType data;
struct DNode *prior,*next;
}Dnode,*DLinkList;(二)双链表的后插操作
1.算法思路
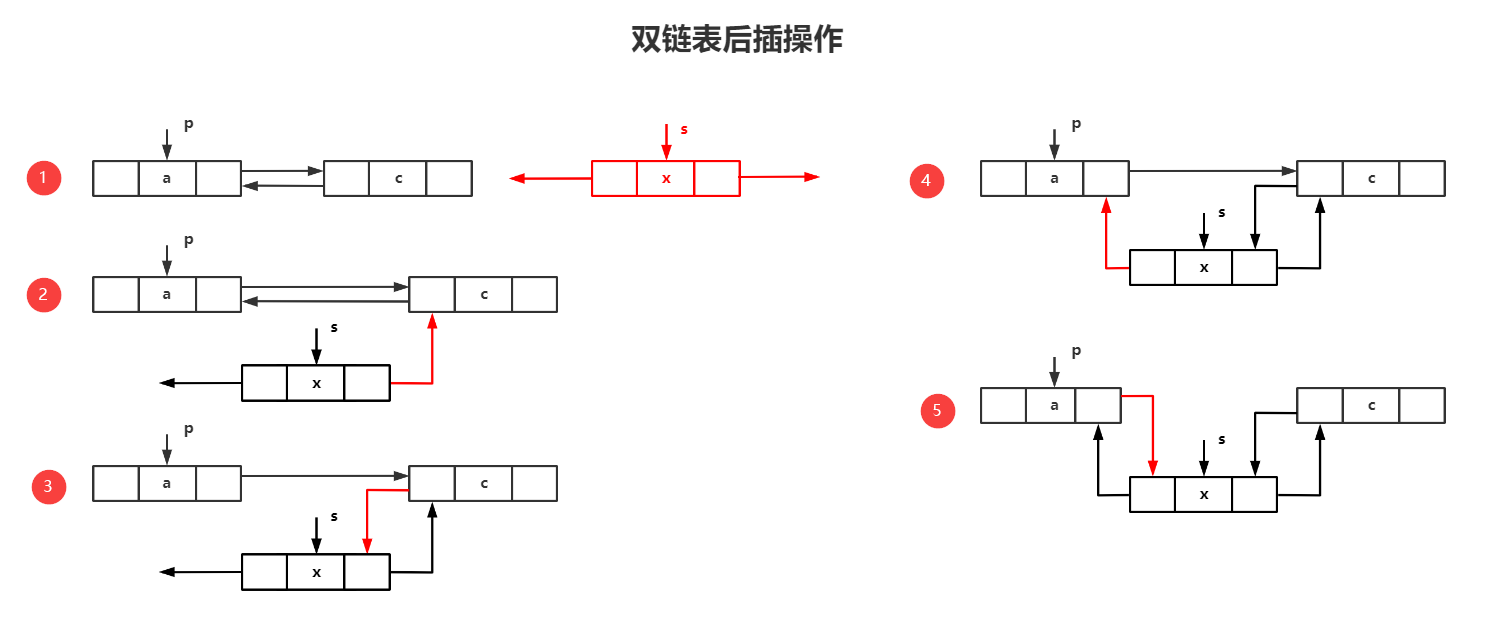
2.代码实现
s->next = p->next;
p->next-prior = s;
s->prior = p;
p->next = s;(三)双链表的删除操作
1.算法思路
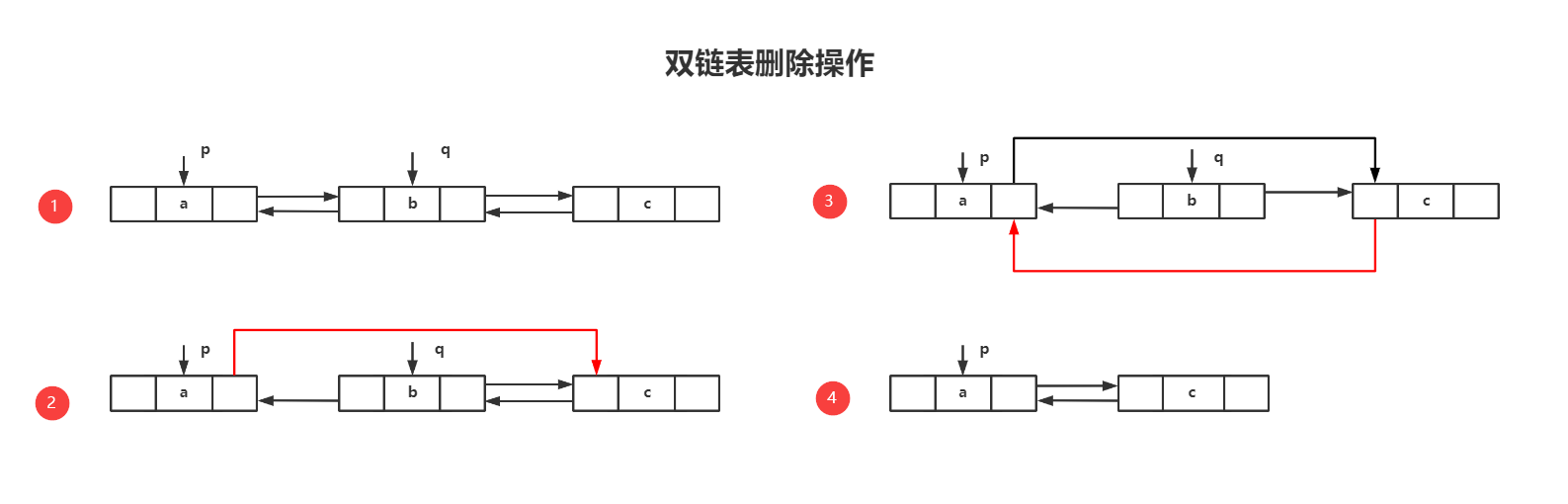
2.代码实现
p->next = q->next;
q->next->prior = p;
free(q);四、循环链表
(一)循环单链表的定义
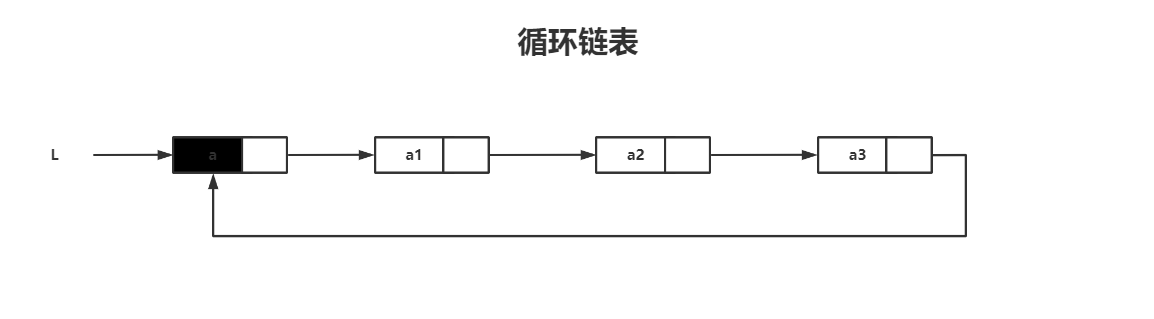
与单链表的区别在于,表中最后一个节点的指针不是NULL,而改为指向头节点,从而整个链表形成一个环
循环链表的判空条件不是头节点的指针是否为空,而是他是否等于头指针
(二)循环双链表的定义
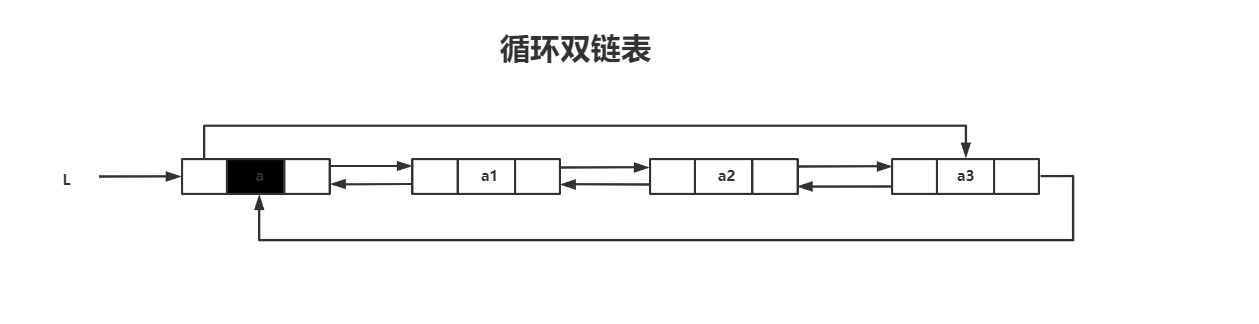
循环双链表中,头节点的prior指针指向表尾节点
判断循环双链表节点为空的条件,头节点的prior和next域都等于头指针L
五、静态链表
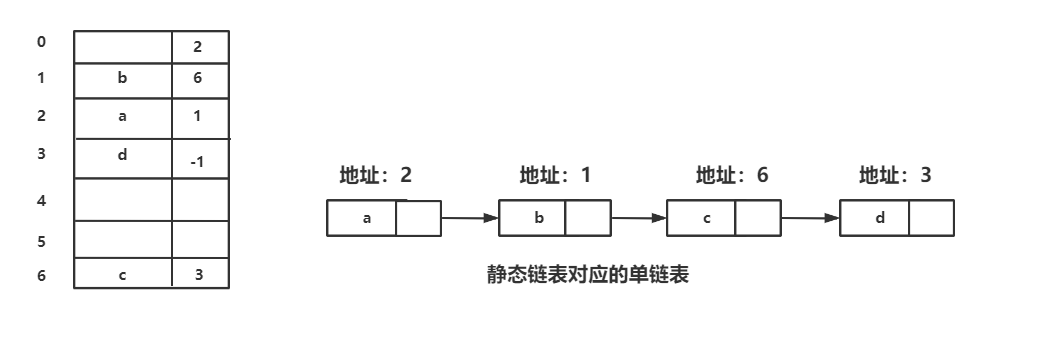
静态链表借助数组来描述线性表的链式存储,指针域是节点的相对地址,也就是数组的下标,称为游标
普通链表的指针里是绝对地址
和顺序表一样,静态链表也要预先分配一块连续的内存空间
指针指向-1的就是尾结点
#define MaxSize 50
typedef struct
{
ElemType data;
int next;
}SLinkList[MaxSize];总体来说,静态链表没有单链表使用方便,但在一些不支持指针的高级语言(如Basic)中,这是一种非常巧妙的设计方法
六、经典例题
(一)选择题
1.给定有n个元素的一维数组,建立一个有序单链表的最低时间复杂度是()
A. B.
C.
D.
如果先建立链表,然后依次插入建立有序表,每插一个元素就需遍历链表寻找插入位置,时间复杂度为
如果先将数组排好序,再建立链表。建立链表的时间复杂度为,数组排序最好时间复杂度为
,因此总时间复杂度为
2.将长度为n的单链表链接在长度为m的单链表后面,其算法的时间复杂度是()
A. B.
C.
D.
插入的时间复杂度为O(1),但是要先找到m单链表的表尾,因此时间复杂度为O(m)
3.在一个长度为n的带头结点的单链表h上,设有尾指针r,则执行()操作与链表的表长有关
A.删除单链表的第一个元素
B.删除单链表的最后一个元素
C.在单链表第一个元素前插入一个新元素
D.在单链表最后一个元素后插入一个新元素
删除单链表最后一个元素,需要把最后一个元素的前驱节点的指针域修改为NULL,因此从头遍历找到这个前驱节点,因此跟表长有关
4. 设对n(n>1)个元素的线性表的运算只有四种:删除第一个元素;删除最后一个元素;在第一个元素之前插入新元素;在最后一个元素之后插入新元素,最好使用()
A.只有尾结点指针没有头结点指针的循环单链表
B.只有尾结点指针没有头结点指针非循环双链表
C.只有头结点指针没有尾结点指针的循环双链表
D.既有头结点指针又有尾结点指针的循环单链表
首先,只要有删除最后一个元素这个条件,单链表就不适合了,不论是否带尾结点或者循环,因为要修改表尾结点的前驱节点的指针,而单链表要找前驱节点,只能遍历循环,所以直接排除单链表选项A、D
只有尾结点指针又不循环,则无法一步找到表头节点的位置,又需要遍历,因此排除选项B
(二)应用题














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









