







YOLOV5的小细节,天坑!
最近想用做了一个demo,测无人机航拍数据,首先在官网下载好YOLOV5模型:GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
我使用的是v6.0版本,训练时按照Readme 来就可以,改一些参数和配置,训练时没什么问题,最终得到了训练好的pt文件。但项目需要将训练好的pt文件转换为onnx、caffemodel。该版本的yolov5支持.pt转为.onnx,但由于caffemodel的转换过程中不支持5维的shape,故需要在源代码中进行修改。将models/yolo.py文件进行修改,主要操作是把reshape为5维的操作和后续的画grid去掉,将其作为后处理。
得到onnx文件后,进行Onnx文件的前向推理,由于网络结构变了,所以需要自己写后处理,主要是加上yolo.py去掉的部分和nms等。没想到得到的效果很差!!找了好几天的错,尝试了重新写推理文件,重新转换onnx等等都没得到好的结果。
后经过我老师大神的指导,原来是在训练过程,train.py的参数配置上有一个参数
![]()
该参数的含义是自动调整anchor大小,一般来说,我们训练用的是coco的anchor,由于该anchor的适应性很强,几乎能用在所有的数据中,平时也就不需要修改,但本数据为航拍数据,anchor需要很小,所以训练时自动调整了大小。通过Debug,得到网络层的最后一层为detect, 利用model.model.model[-1]得到
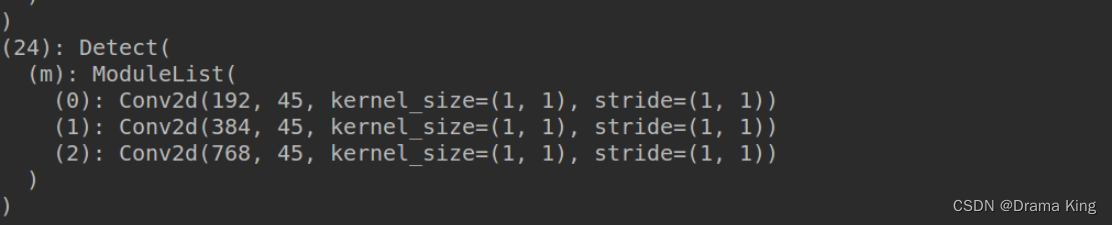
然后再利用model.model.model[-1],anchor_grid得到该detect的anchor。
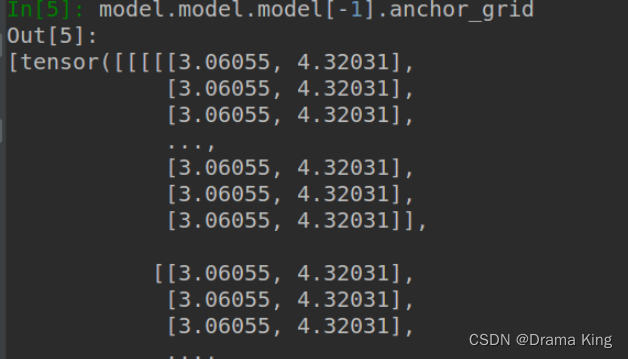
可以看到anchor的大小不再是coco定义好的大小,故再进行后续操作时,填写anchor大小一定记 得改!!!
坑!!!!















 1272
1272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









