






论文链接:http://arxiv.org/abs/2307.14863
代码链接:https://github.com/SunnyHaze/IML-ViT/tree/main
前言:
IML-ViT是首个以ViT为backbone的图像处理定位模型。论文指出了图像处理定位任务(IML)和传统的图像分割任务存在三个关键的差异:高分辨率、边缘监督和多尺度监督。基于这3个关键差异,作者设计了具有以下组件的IML-ViT:(1)接受高分辨率输入的带窗口ViT,大多数全局注意力块被窗口注意力取代,作为时间复杂性的权衡。2)引入多尺度监督的简单特征金字塔网络;3)基于形态学的边缘损失算法。
本文将分别介绍这三个组件。
1.总体结构概述
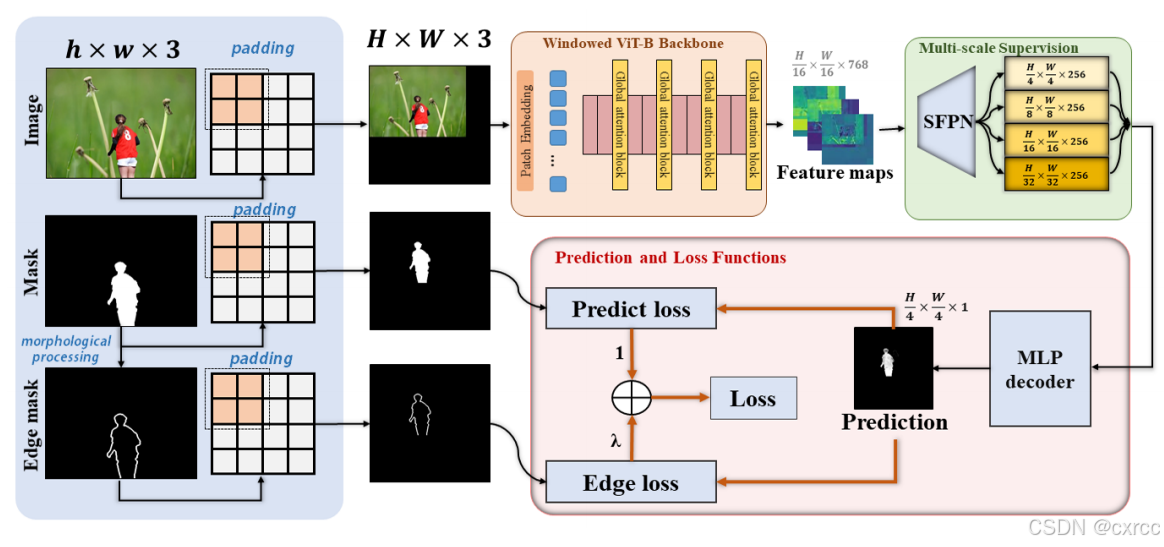
如上图所示,输入时三张图片,包括被篡改的图像、真值掩码图像和边界掩码图像。模型主要由三个组件组成,(1)带窗口的ViT-bone,在ViT的基础上增加了窗口,用于平衡高分辨率和计算复杂度;(2)简单特征金字塔网络(Simple Feature Pyramid Network,SFPN),引入了多尺度特征;(3)具有额外边缘监督的MLP解码器头,有助于专注于篡改痕迹相关的特征并保证稳定的收敛。
2.Windowed-ViT
IML-ViT是基于ViT的基础上发展而来的,而ViT又是基于Transformer的基础上发展而来,本节会先对Transformer和ViT做一个简要介绍,再介绍IML-ViT增添的窗口机制。本节主要探讨3个模型之间的演变,对具体模块(如多头注意力机制、位置编码)不做过多探讨,感兴趣的读者可以自行了解。
2.1Transformer
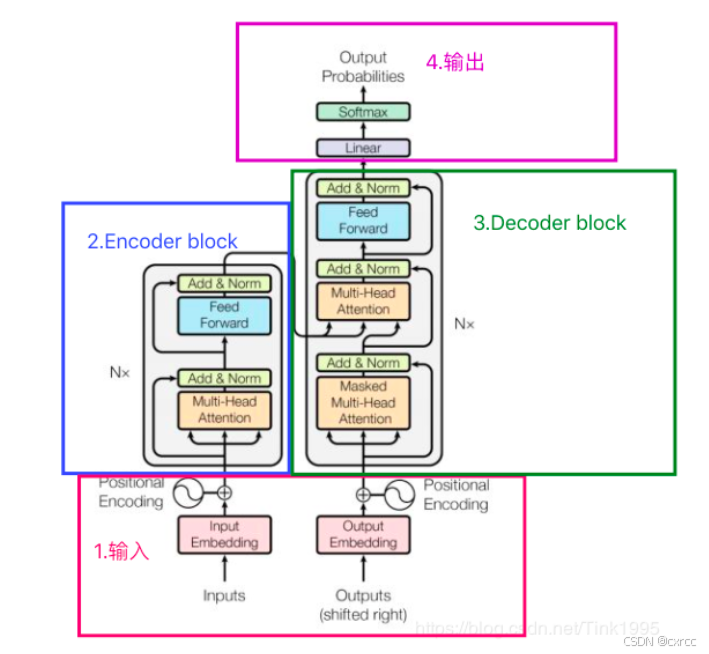
Transformer是一种用于自然语言处理(NLP)和其他序列到序列任务的深度学习模型架构,它的结构示意图如图2所示。由于Transformer没有内置的序列位置信息,它需要额外的位置编码来表达输入序列中单词的位置顺序。所以输入会先加上额外的位置编码再进入Encoder Block。
Encoder block由6个encoder堆叠而成,图中的一个框代表的是一个encoder的内部结构,一个Encoder是由Multi-Head Attention和全连接神经网络Feed Forward Network构成。
和Encoder Block一样,Decoder也是由6个decoder堆叠而成的。包含两个 Multi-Head Attention 层。第一个 Multi-Head Attention 层采用了 Masked 操作。第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
2.2ViT
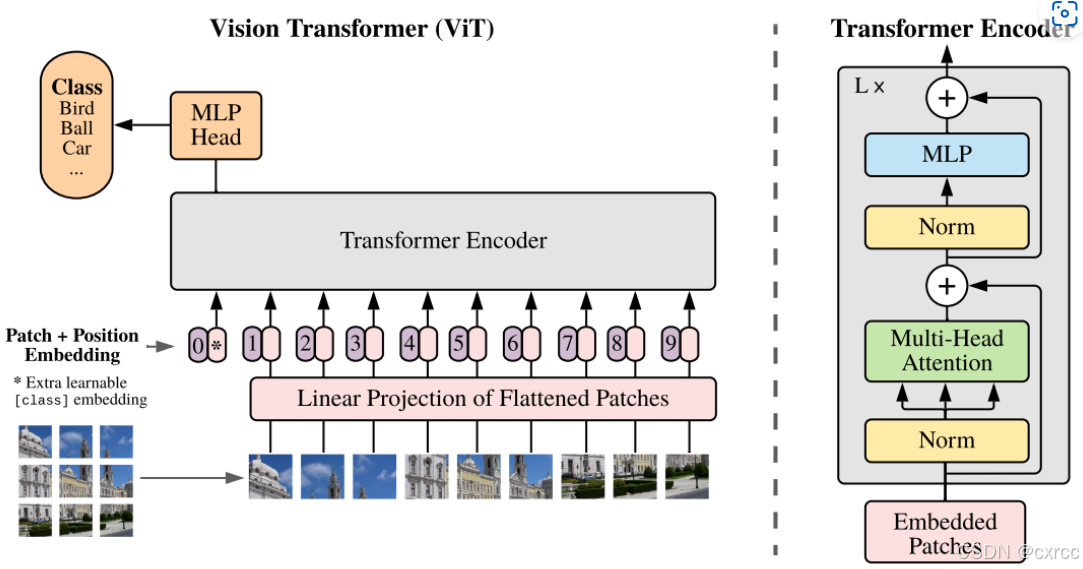
Vision Transformer是Transformer的视觉版本,Vision Transformer打破了这种NLP与CV的隔离,将Transformer应用于图像图块(patch)序列上,进一步完成图像分类任务。简单来理解,Vision Transformer就是将输入进来的图片,每隔一定的区域大小划分图片块。然后将划分后的图片块组合成序列,将组合后的结果传入Transformer特有的Multi-head Self-attention进行特征提取,最后利用Cls Token进行分类。
2.3 windowed ViT
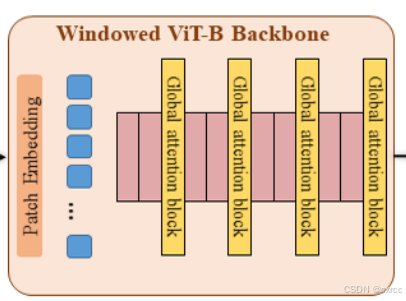
windowed ViT在ViT的基础上增加了窗口机制。它在除了第3、6、9、12的encoder都加了个窗口,就是先将图片裁剪成14X14的大小再投入解码器。为什么要增加一个窗口呢。这是避免下采样导致图像篡改痕迹丢失,输入图像采用高分辨率,也就是1024X1024,经过patch embed后,图片大小变为64X64,卷积计算成本是很大的。为了平衡分辨率和计算成本,就会进入多头注意力块前输入图片通过窗口进行裁剪,之后再恢复原始尺寸。
分割代码如下:
def window_partition(x, window_size):
"""
Partition into non-overlapping windows with padding if needed.
Args:
x (tensor): input tokens with [B, H, W, C].
window_size (int): window size.
Returns:
windows: windows after partition with [B * num_windows, window_size, window_size, C].
(Hp, Wp): padded height and width before partition
"""
B, H, W, C = x.shape
pad_h = (window_size - H % window_size) % window_size
pad_w = (window_size - W % window_size) % window_size
if pad_h > 0 or pad_w > 0:
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
Hp, Wp = H + pad_h, W + pad_w
x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows, (Hp, Wp)
融合代码如下:
def window_unpartition(windows, window_size, pad_hw, hw):
"""
Window unpartition into original sequences and removing padding.
Args:
x (tensor): input tokens with [B * num_windows, window_size, window_size, C].
window_size (int): window size.
pad_hw (Tuple): padded height and width (Hp, Wp).
hw (Tuple): original height and width (H, W) before padding.
Returns:
x: unpartitioned sequences with [B, H, W, C].
"""
Hp, Wp = pad_hw
H, W = hw
B = windows.shape[0] // (Hp * Wp // window_size // window_size)
x = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1)
if Hp > H or Wp > W:
x = x[:, :H, :W, :].contiguous()
return x3.Simple Feature Pyramid Network(SFPN)
为了引入多尺度监督,我们在ViT编码器后采用简单特征金字塔网络(simple feature pyramid network, SFPN)。该方法从ViT中获取单个输出特征图Ge,然后使用一系列卷积和反卷积层进行上采样和下采样,得到多尺度特征图。输入的特征图大小为64X64X768,输出的特征图的大小分别为256X256X256、128X128X256、64X64X256、32X32X256。
官方代码实现如下所示:
class SimpleFeaturePyramid(nn.Module):
def __init__(self,
in_feature_shape, # 输入形状为(N,C,H,W),(1,768,256,256)
out_channels, # 输出的通道数256
scale_factors, # 缩放的比例 [4.0,2.0,1.0,0.5]
input_stride = 16,
top_block=None, # 额外的操作
norm=None
) -> None:
super().__init__()
_, dim, H, W = in_feature_shape
self.dim = dim
self.scale_factors = scale_factors
self.stages = []
strides = [input_stride // s for s in scale_factors]
_assert_strides_are_log2_contiguous(strides)
use_bias = norm == ""
for idx, scale in enumerate(scale_factors):
out_dim = dim
if scale == 4.0:
layers = [
nn.ConvTranspose2d(dim, dim // 2, kernel_size=2, stride=2),
get_norm(norm, dim // 2),
nn.GELU(),
nn.ConvTranspose2d(dim // 2, dim // 4, kernel_size=2, stride=2),
]
out_dim = dim // 4
elif scale == 2.0:
layers = [nn.ConvTranspose2d(dim, dim // 2, kernel_size=2, stride=2)]
out_dim = dim // 2
elif scale == 1.0:
layers = []
elif scale == 0.5:
layers = [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
raise NotImplementedError(f"scale_factor={scale} is not supported yet.")
layers.extend(
[
Conv2d(
out_dim,
out_channels,
kernel_size=1,
bias=use_bias,
norm=get_norm(norm, out_channels),
),
Conv2d(
out_channels,
out_channels,
kernel_size=3,
padding=1,
bias=use_bias,
norm=get_norm(norm, out_channels),
),
]
)
layers = nn.Sequential(*layers)
stage = int(math.log2(strides[idx]))
self.add_module(f"simfp_{stage}", layers)
self.stages.append(layers)
self.top_block = top_block
# Return feature names are "p<stage>", like ["p2", "p3", ..., "p6"]
self._out_feature_strides = {"p{}".format(int(math.log2(s))): s for s in strides}
# top block output feature maps.
if self.top_block is not None:
for s in range(stage, stage + self.top_block.num_levels):
self._out_feature_strides["p{}".format(s + 1)] = 2 ** (s + 1)
self._out_features = list(self._out_feature_strides.keys())
self._out_feature_channels = {k: out_channels for k in self._out_features}
def forward(self, x):
bottom_up_features = x # input contains the output of backbone ViT
# print(bottom_up_features)
features = bottom_up_features['last_feat']
results = []
for stage in self.stages:
results.append(stage(features))
if self.top_block is not None:
if self.top_block.in_feature in bottom_up_features:
top_block_in_feature = bottom_up_features[self.top_block.in_feature]
else:
top_block_in_feature = results[self._out_features.index(self.top_block.in_feature)]
results.extend(self.top_block(top_block_in_feature))
assert len(self._out_features) == len(results)
return {f: res for f, res in zip(self._out_features, results)}4.Light-Head Predict Head
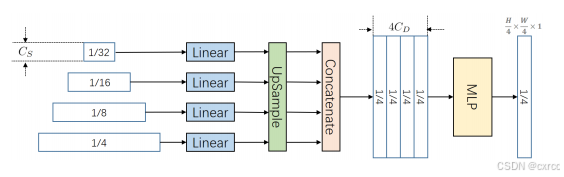
如上图所示,轻量级的MLP解码器首先应用线性层来统一通道尺寸,然后使用双线性插值将所有的特征图上采样到256X256大小,接着再将所有的特征图拼接在一起,最后经过一系列的线性层输出预测图。最后输出的大小为256X256X1。
这里官方代码实现与论文中所描述的有点区别。官方代码是没有最开始的线性层的,然后输入的多尺度特征图是有5个,再最后还添加了一个16X16X1大小的。我按照官方代码的实现,修改了结构图,如下:
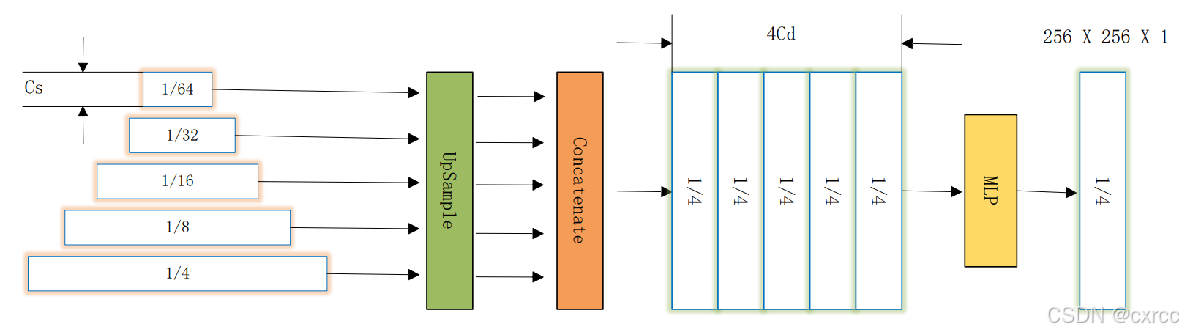
5.Edge Supervision Loss
5.1 Edge Mask
考虑到篡改痕迹通常在篡改区域的边缘更普遍这一事实,我们制定了一个策略,更加强调被篡改区域的边界区域。具体来说,我们使用包括膨胀(dilation,⊕)和侵蚀(erosion)在内的数学形态学运算,从原始掩码图像M生成一个二值边缘掩码M *,然后取结果的绝对值。生成边缘掩码的公式如下:
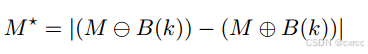
B函数,是生成一个(2k+1)*(2k+1)的交叉矩阵,只有第k列和第k行为1,其余全为0。
圈里一个减号代表腐蚀操作,圈里一个加号代表膨胀操作。 最后取绝对值,保证无论图片中是真实区域占比大,还是篡改区域占比大,mask只会关注两者的交界处。
5.2 Combined Loss
为了计算最后的损失函数,我们将真值掩码M和边缘掩码M*填充到大小为HxW,并将他们分别称为Mp和Mp*,具体计算公式如下:
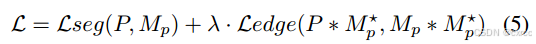
Lseg和Ledg都是指二元交叉熵损失函数。λ是一个超参数,用于平衡分割和边缘损失,默认将λ设为20,来引导模型聚焦于边缘区域。
参考文章:
【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客神经网络学习小记录67——Pytorch版 Vision Transformer(VIT)模型的复现详解_vit复现代码-CSDN博客

















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









