






论文链接:WACV 2021 Open Access Repository
代码链接:GitHub - mjkwon2021/CAT-Net: Official code for CAT-Net: Compression Artifact Tracing Network. Image manipulation detection and localization.
前言:
CAT-Net模型是一个包含RGB流和DCT流的端到端全卷积神经网络,用于识别和定位图像中的拼接区域。接下来,我将先介绍CAT-Net的整体模型结构,然后再逐个模块进行讲解
1.整体结构:
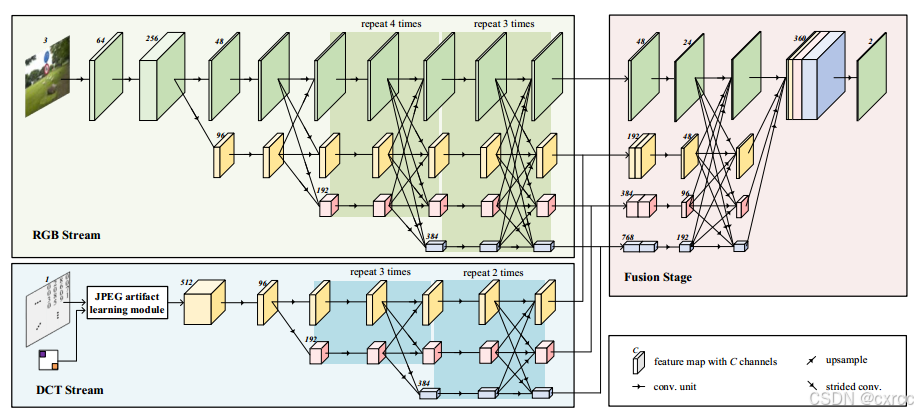
如上图所示,CAT-Net主要分为RGB流、DCT流和最后的融合阶段。其中,RGB流的输入是RGB像素值,用于提取视觉线索;而DCT流的输入为y-通道DCT系数和y-通道量化表,侧重于提取压缩伪影。然后,两个流的输出融合生成最终结果。
2.RGB分支:
2.1整体分析:
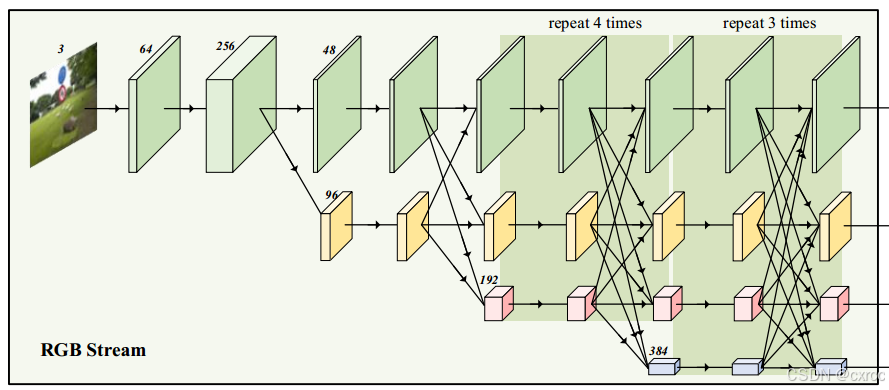
先解释图中图标的含义,输入是通道数为3的图片。长方体表示特征图,上方的数字是通道数。平行的箭头是卷积单元,这个部分留到后面详细讲解。向下的箭头是降维操作,是步长为2的3X3卷积。向上的箭头是升维操作,先是1X1卷积,再使用双线性插值。
RGB分支的输入是RGB像素值,第一个卷积单元,将分辨率变为1/4。然后从高分辨率路径出发,从高到低构建多条不同分辨率的路径,并将多分辨率路径并行连接。每个分辨率都保留到最后,分别是1/4,1/8,1/16,1/32。整个模型包括两种基本单元,分别为卷积单元和融合单元。总体上看,RGB分支可以分为4个阶段,第一个卷积单元(即第一个水平箭头)较为特殊,其余的卷积单元(即其余的水平箭头)都是由4个Basic block组成。各阶段间有一个融合单元,用于融合不同分辨率的特征图。接下来我将分别介绍卷积单元和融合单元。
2.2卷积单元
除了第一个卷积单元外(即图2中的第一个水平箭头),其余卷积单元都是由4个连续的Basic block组成。其中,Basic block的结构如下所示:
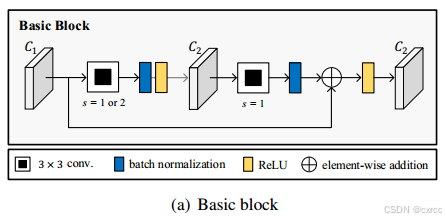
此Basic Block的结构与ResNet中的Basic Block的结构基本相似,就不再赘述了。
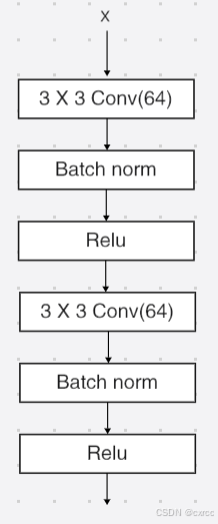
第一部分的卷积(也就是图2中的第一个平行箭头),论文中没有详细介绍,但从代码中可以找到具体的实现。它的主要作用是将通道数由3变为64,并降低分辨率。
def __init__(..)
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1,
bias=False) # 改变通道数,并降低分辨率
self.bn1 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn2 = BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
def forward(self,x)
RGB = x[:, :3, :, :]
x = self.conv1(RGB)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
模型图如下所示:
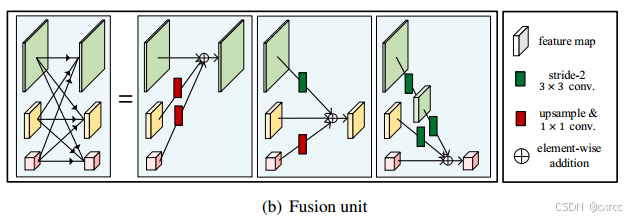
2.3融合单元(fusion unit)
在各阶段之间有一个融合单元,用于不同分辨率的分支进行融合。融合单元通过双线性插值(上采样)或步长为2的卷积(下采样)匹配分辨率后,将多分辨率特征相加,实现多分辨率特征图的融合。融合单元的结构图如下所示:
3.DCT分支:
3.1整体分析
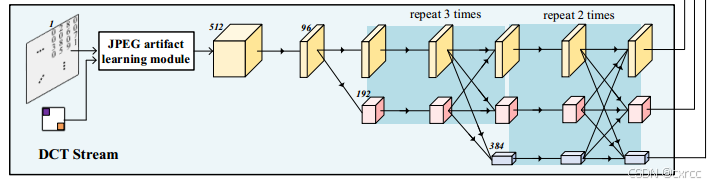
DCT流(如图6所示)侧重于捕捉JPEG伪影。该分支的输入为y-channel的DCT系数和量化表,先经过一个JPEG artifact learning module,再经由卷积单元和融合单元。DCT流的卷积单元全部由4个Basicblock组成。由于卷积单元和融合单元已经在上一节中讲过了,在此节中就不再赘述。
3.2JPEG artifact learning module
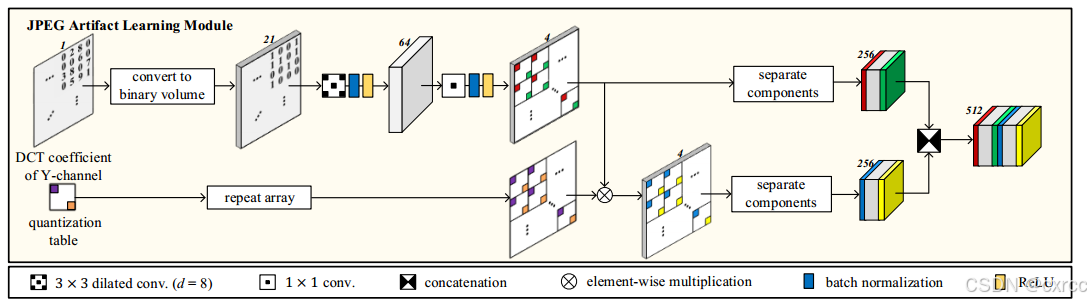
JPEG artifact learning module(结构图如上图所示)首先将DCT系数的矩阵M转换为二进制体积。转化方式如下:
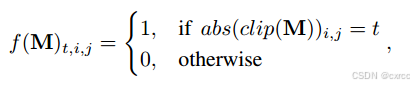
其中clip函数将数组元素裁剪到区间[-T, T]中,abs函数获取元素的绝对值,T取值为20。然后对二进制体积再进行连续的卷积操作。先是一个dilation为8的3X3空洞卷积,用于提取相同频率的DCT系数的特征。然后再是一个1X1卷积,将通道数由64降到4。
在下面这条路径上,将JPEG报头得到的8 × 8量化表乘以相应的频率分量。然后在两条路径上,将频率分量分离成8X8大小。注意,前面的操作是按频率进行的,因此8 × 8块中的每个值代表一个频率分量。分离组件将形状从4 × H × W更改为256 × H /8 × W /8,这有助于大大地降低分辨率。最后,在该模块中,将两条路径的特征映射在通道维度上进行连接。输出传递DCT流的剩余路径。
4.融合部分:
4.1 整体分析
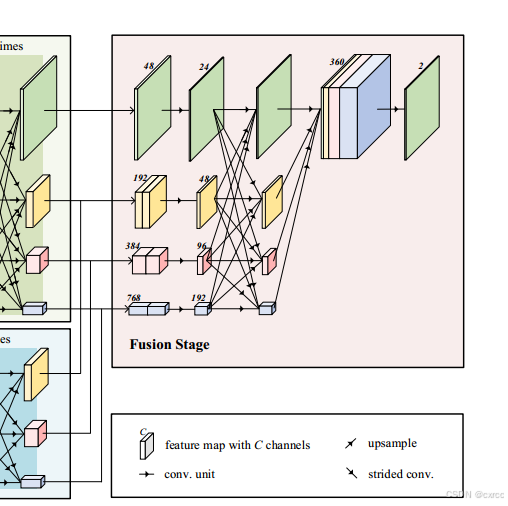
RGB分支输出的特征图的分辨率分别为原始大小的1/4,1/8,1/16和1/32。DCT分支输出的特征图分别为原始大小的1/8,1/16和1/32。两流特征图按通道尺寸按分辨率进行连接,并传递到最后的融合阶段(如上图所示)。再各经过一次卷积单元和融合单元后,所有四个分辨率的特征映射都进行双线性上采样,以匹配最高分辨率,连接并通过最后的卷积层。最终输出是每个类(真实的和篡改的)的2 × H /4 × W /4的逻辑值数组。
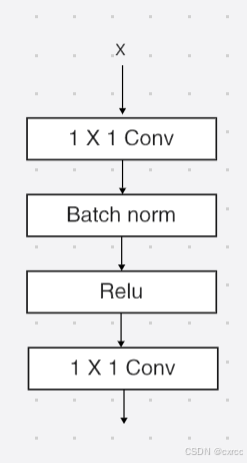
4.2 最后的卷积层
最后一个卷积单元从官方代码中可以得到其实现,具体代码如下所示:
def forward(self,x):
....
x = self.last_layer(x)
....
def __init__():
....
nn.Conv2d(in_channels=last_inp_channels,
out_channels=last_inp_channels,
kernel_size=1,
stride=1,
padding=0)
BatchNorm2d(last_inp_channels, momentum=BN_MOMENTUM)
nn.ReLU(inplace=True)
nn.Conv2d(in_channels=last_inp_channels,
out_channels=config.DATASET.NUM_CLASSES,
kernel_size=extra.FINAL_CONV_KERNEL,
stride=1,
padding=1 if extra.FINAL_CONV_KERNEL == 3 else 0)
....
模型图如下所示:

















 2646
2646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









