









《Large-scale Video Classification with Convolutional Neural Networks》
核心思想:
使用2D卷积神经网络对视频帧进行分析,为了捕获temporal维度的特征,提出了3中特征融合方法,Late Fusion,Early Fusion和Slow Fusion。

为了提升训练速度,使用更低分辨率的图像进行训练。
数据预处理方法:裁剪每帧图像的中间区域,然后缩放到200 x 200大小,然后再模型训练时随机裁剪170 x 170大小进行训练。
算法结果:

《C3D: Learning Spatiotemporal Features with 3D Convolutional Networks》
开源代码:https://github.com/facebookarchive/C3D
开源代码:https://github.com/jfzhang95/pytorch-video-recognition
核心思想:
使用3D卷积神经网络进行时空特征学习,增加时间维度的卷积。使用3x3x3的卷积核大小。2D卷积与3D卷积的区别,对于一组输入图像[![]() ],如果使用2D卷积,2D卷积核参数为[
],如果使用2D卷积,2D卷积核参数为[![]() ],则对于2D卷积来说,输入的特征维度为[
],则对于2D卷积来说,输入的特征维度为[![]() ], 卷积之后得到的输出特征维度为[
], 卷积之后得到的输出特征维度为[![]() ]。对于一组输入图像[
]。对于一组输入图像[![]() ],如果使用3D卷积,3D卷积核参数为[
],如果使用3D卷积,3D卷积核参数为[![]() ],输出特征维度为[
],输出特征维度为[![]() ]。
]。


双流网络
《Two-Stream Convolutional Networks for Action Recognition in Videos》
光流提取:https://github.com/sniklaus/pytorch-spynet
光流提取:https://github.com/sniklaus/pytorch-pwc
开源代码:https://github.com/jeffreyyihuang/two-stream-action-recognition
核心思想:
网络有两个输入分支:
分支一:输入单张原始图片进行卷积,然后进行softmax分类
分支二:输入光流片段optical flow clip,然后对optical flow clip进行2D卷积,然后进行softmax分类。保存每帧图像在x和y轴方向的光流数据保存为光流图像的两个channel,所以对于输入长度为L的光流片段,其输入到分支二的数据维度为[2L, H, W]
输出:对两个分支的输出结果进行融合。

论文中同时验证了使用光流和使用轨迹来表示运动特征的方法,使用轨迹表示运动特征的性能一般:

论文中还验证了双向光流特征,也叫反向光流特征的性能,性能一般。
《TSN: Temporal Segment Networks: Towards Good Practices for Deep Action Recognition》
开源代码:https://github.com/yjxiong/temporal-segment-networks
核心思想:
之前的双流网络性能不好的原因是提取的光流特征不好,密集的光流特征采样不仅增加了计算的负担,还带来了融入的信息。本论文中提出了一种光流数据稀疏采样方法,此种方法分片段稀疏采样整个视频的光流数据,能够在不增加计算负担的同时,保持了整个视频的光流运动信息。
TSN网络结构:
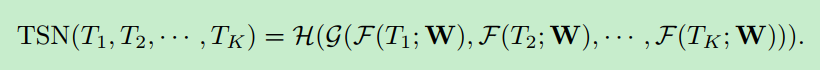
对一段视频采集K个片段,然后分辨对每个片段进行预测,然后对预测结果进行融合。

与上一篇的双流网络采用同样的光流数据输入方式。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









