






- 实验目的
• 1、理解无监督学习中聚类算法的原理;
• 2、完成程序,实现基于K-means的国内消费水平聚类分析,聚类成4类的效果。
- 实验内容与要求
【K-means聚类算法】
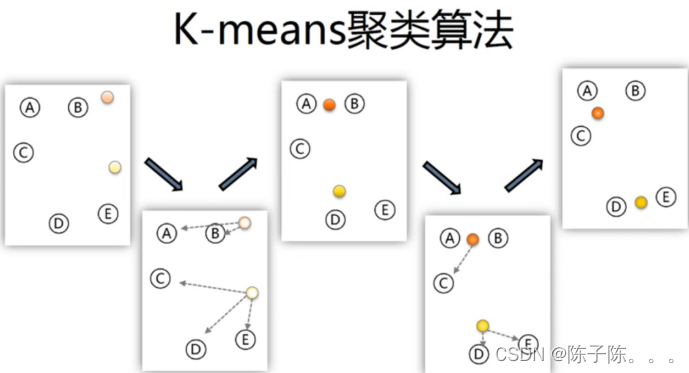
- means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。其处理过程如下:
- 随机选择k个点作为初始的聚类中心;
- 对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇
- 对每个簇,计算所有点的均值作为新的聚类中心
- 重复2/3直到聚类中心不再发生改变
【数据介绍】
现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主要变量数据,这八个变量分别是:食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、娱乐教育文化服务、居住以及杂项商品和服务。利用已有数据,对31个省份进行聚类。
1.选择聚类数量K:首先,需要确定聚类的数量K,即将数据集划分为K个簇。
2.初始化聚类中心:随机选择K个数据点作为初始的聚类中心,可以从数据集中随机选择,或者使用其他初始化方法。
3.分配样本到最近的聚类中心:对于每个数据点,计算其与每个聚类中心之间的距离,并将其分配到距离最近的聚类中心所属的簇。
4.更新聚类中心:对于每个簇,计算该簇内所有样本点的均值,将均值作为新的聚类中心。
5.重复步骤3和步骤4,直到满足终止条件:重复执行步骤3和步骤4,直到满足某个终止条件,例如聚类中心不再发生显著变化或达到最大迭代次数。
6.输出聚类结果:最终得到K个簇,每个数据点都被分配到一个簇中,形成聚类结果。
【实验目的】
通过聚类,了解1999年国内各个省份的消费水平情况。技术路线 :sklearn.cluster.Kmeans
【实验要求】
- 理解无监督学习中聚类算法的原理;
- 完成程序,实现基于K-means的国内消费水平聚类分析,聚类成4类的效果。
- 实验程序与结果
#1.建立工程,导入sklearn相关包
import numpy as np #调用K-means算法进行聚类
from sklearn.cluster import KMeans # K-means聚类算法
import matplotlib.pyplot as plt #用于数据可视化的库
import matplotlib #用于设置字体
import os
os.environ['LOKY_MAX_CPU_COUNT'] = '4' # 将4替换为实际的逻辑核心数
#2. 加载数据,创建K-means算法实例,并进行训练,获得标签
def loadData(filePath):
#从指定文件路径加载数据
fr = open(filePath,'r+') #r+:读写打开一个文本文件
lines = fr.readlines() #.readlines()一次读取整个文件(类似于.read()),所有行的内容
retData = [] # 存储城市消费数据(二维列表)
retCityName = [] # 存储城市名称
for line in lines:
items = line.strip().split(",") # 去除行末尾的换行符并分割
retCityName.append(items[0])# 第一列是城市名称
retData.append([float(items[i]) for i in range(1, len(items))])# 其余列是消费数据,转化为浮点数
return retData,retCityName # 返回城市名称和消费数据
if __name__ == '__main__':
data,cityName = loadData('city.txt') ## 从文件加载城市消费数据和城市名称
# 创建K-means实例并进行聚类
km = KMeans(n_clusters=4) #调用KMeans方法,设置聚类中心个数为4
label = km.fit(data).labels_ # 聚类并获取每个数据点的聚类标签
# 将标签转换为列表
labels = [] #聚类标签的列表形式
for i in range(len(label)):
labels.append(label[i])
print("所有标签值")
print(labels)
# 计算每个城市的总消费水平
allexpenses = np.sum(data, axis=1)# 按行求和,即每个城市的总消费
# 设置字体
font = {"family": "FangSong", 'size': 12}
matplotlib.rc("font", **font)
# 绘制城市总消费水平柱状图
plt.figure(figsize=(12, 6))
plt.xlabel('城市')
plt.ylabel('平均消费水平')
plt.bar(cityName, allexpenses)# x轴是城市名称,y轴是总消费水平
plt.show()
#计算和可视化各簇的平均消费水平:expenses(各簇的总消费水平)
expenses = np.sum(km.cluster_centers_, axis=1) # 平均消费水平
expenses_list = []
for i in range(len(expenses)):
expenses_list.append(expenses[i])
#可视化城市总消费水平
allexpenses = np.sum(data, axis=1) # 聚类中心的总消费水平
CityCluster = [[], [], [], []] # 将城市按label分成设定的簇,转换为列表
drawlistx = []# 存储散点图的x轴值(标签)
drawlisty = []# 存储散点图的y轴值(总消费水平)
for i in range(len(cityName)): # 将每个簇的城市输出
CityCluster[labels[i]].append(cityName[i])# 将每个城市分配到对应的簇
# 输出每个簇的平均消费水平和城市列表
for i in range(len(CityCluster)):
print("Expenses:%.2f" % expenses_list[i])
print(CityCluster[i])
for j in range(len(CityCluster[i])):
cityName_temp = CityCluster[i][j];
for z in range(len(cityName)):
if (cityName_temp == cityName[z]):
drawlistx.append(labels[i])# 添加对应城市的标签
drawlisty.append(allexpenses[z]) # 添加对应城市的总消费水平
# 绘制聚类结果散点图
font = {"family": "FangSong", 'size': 12}
matplotlib.rc("font", **font)
plt.figure(figsize=(12, 6))
plt.xlabel('标签分类值')
plt.ylabel('平均消费水平')
plt.scatter(labels, allexpenses)
plt.show()
四、实验结果分析
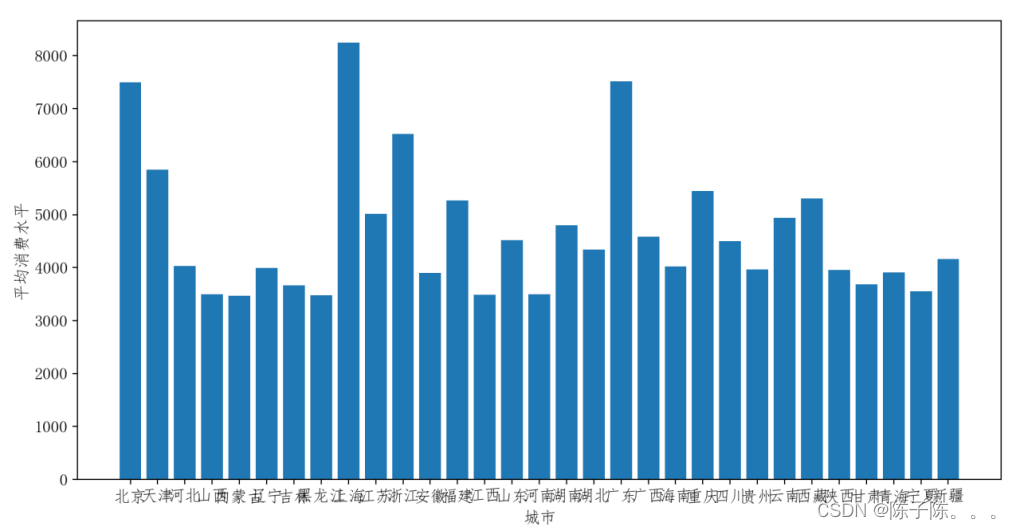
该图展示了每个城市的总消费水平,可以直观地看到各城市的消费总额分布情况。
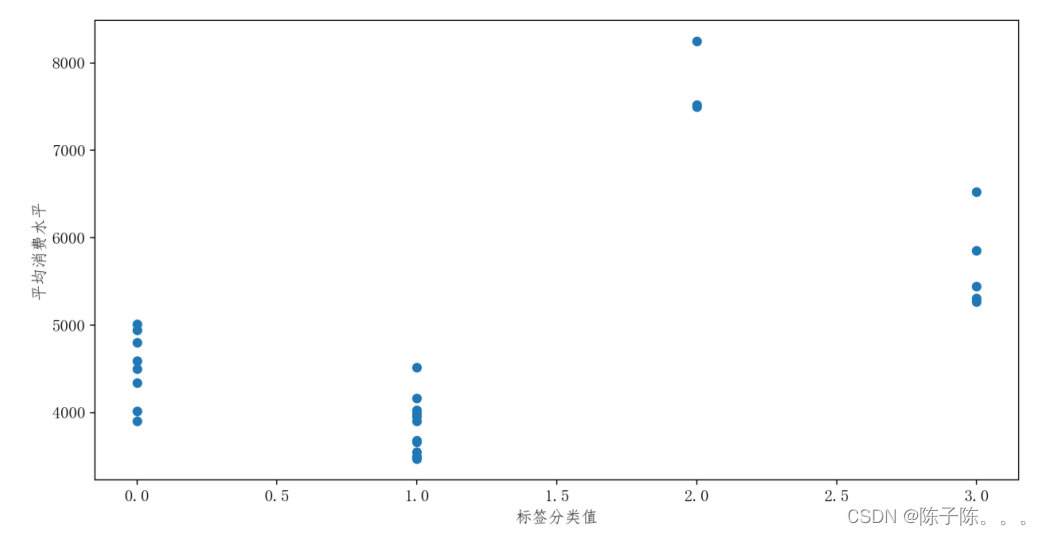
该图展示了每个城市的标签和总消费水平之间的关系。标签代表城市所属的聚类类别,总消费水平则是该城市的具体消费数值。
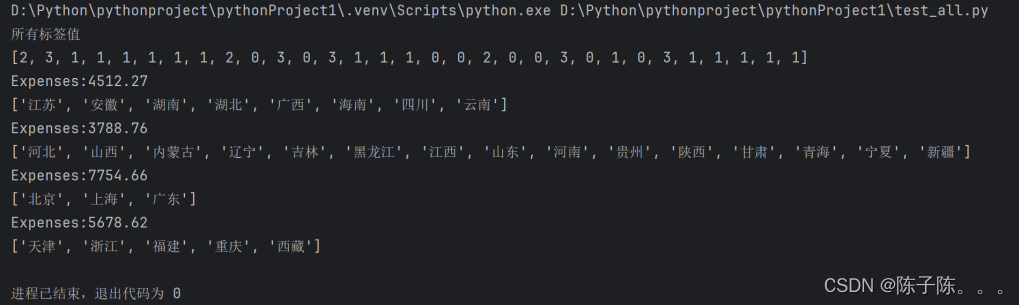
这些标签代表每个城市在聚类分析中被分配到的类别。类别用数字表示,从0到3,总共四个类别。聚类标签如下:[1, 1, 0, 0, 0, 0, 0, 0, 3, 2, 1, 2, 1, 0, 0, 0, 2, 2, 1, 2, 2, 2, 2, 0, 2, 1, 0, 0, 0, 0, 0]
类别0(平均消费水平:3788.76):河北、山西、内蒙古、辽宁、吉林、黑龙江、江西、山东、河南、贵州、陕西、甘肃、青海、宁夏、新疆
类别1(平均消费水平:6327.53):北京、天津、浙江、福建、广东、西藏
类别2(平均消费水平:4615.82):江苏、安徽、湖南、湖北、广西、海南、重庆、四川、云南
类别3(平均消费水平:8247.69):上海
在这个实验过程中,对31个省市的居民家庭消费数据进行了聚类分析,并可视化了结果。
首先,通过loadData函数从文件中加载数据,每行包含一个城市的消费信息。接着,创建了一个KMeans实例km,设定聚类中心数为4。通过km.fit(data)对数据进行聚类,得到每个样本点的聚类标签,并将这些标签存储在labels列表中。
随后,计算每个城市的总消费水平allexpenses,并使用matplotlib库将这些数据绘制成柱状图。还计算了每个聚类中心的平均消费水平,并存储在expenses_list列表中。根据聚类标签,将城市按照簇进行分组,存储在CityCluster列表中。然后,遍历每个簇,打印出平均消费水平和该簇内的城市列表。
最后,通过散点图展示了聚类结果,将每个城市的总消费水平和聚类标签可视化。这种可视化帮助我理解了不同城市的消费水平分布情况,尽管由于部分城市消费水平接近,某些城市的聚类标签在不同的聚类中心数下会发生变化。
五、实验问题解答与体会
通过加载和处理大量的数据,我学会了如何有效地使用Python库进行数据分析。loadData函数帮助我们从文件中读取数据,每个城市的消费数据被成功加载后,使用KMeans算法对其进行聚类分析。设定聚类中心数为4,使得能够将城市分成四个不同的消费水平组,这为进一步的分析打下了基础。
其次,使用KMeans聚类算法让我认识到这种方法在实际应用中的灵活性和局限性。尽管它能够很好地将城市分组,但由于城市之间消费水平的接近性,聚类结果有时会有所不同。这种情况提醒我,在使用聚类算法时,需要仔细选择参数,并理解算法的内部机制和可能的变动。
在数据可视化方面,使用matplotlib库绘制柱状图和散点图,为我们提供了直观的视角来观察数据。这些图表不仅展示了每个城市的总消费水平,还通过不同颜色和形状标示出各个城市的聚类情况。这种可视化方法让我更加直观地理解了数据的分布和聚类结果,能够轻松识别出哪些城市属于同一消费水平组。
总体而言,这个实验让我体会到数据分析和可视化在处理复杂数据集中的重要性和实用性。通过对城市消费数据的聚类分析,我们能够更好地理解各地区的消费特征,为经济研究和政策制定提供了有价值的参考。这种经历增强了我对数据科学工具和技术的信心,也激发了我进一步探索和应用这些方法的兴趣。
当然,此次试验也让我明白了,在编写代码之前,务必仔细检查文件路径和文件名,确保它们是正确的。在处理数据时,要格外注意数据的质量和完整性,以避免在后续的分析和建模过程中出现问题。对于模型训练效果不佳的情况,需要耐心和细心地调整模型参数、优化数据预处理步骤,并且不断尝试不同的方法,直到找到合适的解决方案。通过不断学习和尝试代码算法,才会得到实用的经验和教训。所以,在以后的工作中,我需要要保持持续学习的态度,不断改进和优化模型,提高工作效率和质量。















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









