



以下python脚本将选择srt字幕,清理序号和时间,只留下内容:
import re
import tkinter as tk
from tkinter import filedialog
def clean_srt_content(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
srt_content = file.read()
filtered_content = re.sub(r'\d+\n\d{2}:\d{2}:\d{2},\d{3} --> \d{2}:\d{2}:\d{2},\d{3}\n', '', srt_content)
filtered_content = re.sub(r'\n{2,}', '\n', filtered_content).strip()
return filtered_content
def save_to_txt(output_path, content):
with open(output_path, 'w', encoding='utf-8') as file:
file.write(content)
def select_srt_file_and_process():
root = tk.Tk()
root.withdraw() # Hide the main window
file_path = filedialog.askopenfilename(
title="Select a SRT file",
filetypes=(("SRT files", "*.srt"), ("All files", "*.*"))
)
if file_path:
cleaned_content = clean_srt_content(file_path)
output_file_path = file_path.rsplit('.', 1)[0] + '_cleaned.txt' # Save as a new file with '_cleaned' suffix
save_to_txt(output_file_path, cleaned_content)
print(f'Cleaned subtitles have been saved to {output_file_path}')
else:
print("No file selected, operation cancelled.")
# Invoke the file selection
select_srt_file_and_process()以下python脚本遍历当前目录下所有srt字幕,依次处理字幕文件为txt,移除序号和时间,只留下内容:
import re
import os
def clean_srt_content(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
srt_content = file.read()
# Remove indexes and timestamps
filtered_content = re.sub(
r'\d+\n\d{2}:\d{2}:\d{2},\d{3} --> \d{2}:\d{2}:\d{2},\d{3}\n', '', srt_content)
# Remove excessive empty lines
filtered_content = re.sub(r'\n{2,}', '\n', filtered_content).strip()
return filtered_content
def save_to_txt(output_path, content):
with open(output_path, 'w', encoding='utf-8') as file:
file.write(content)
def process_all_srt_files(directory):
for filename in os.listdir(directory):
if filename.endswith(".srt"):
file_path = os.path.join(directory, filename)
cleaned_content = clean_srt_content(file_path)
output_file_path = os.path.splitext(file_path)[0] + '_cleaned.txt'
save_to_txt(output_file_path, cleaned_content)
print(f"Processed {filename}")
# Call the function with the current directory
process_all_srt_files(".")SRT字幕如下:

从youtube下载字幕后,处理结果:
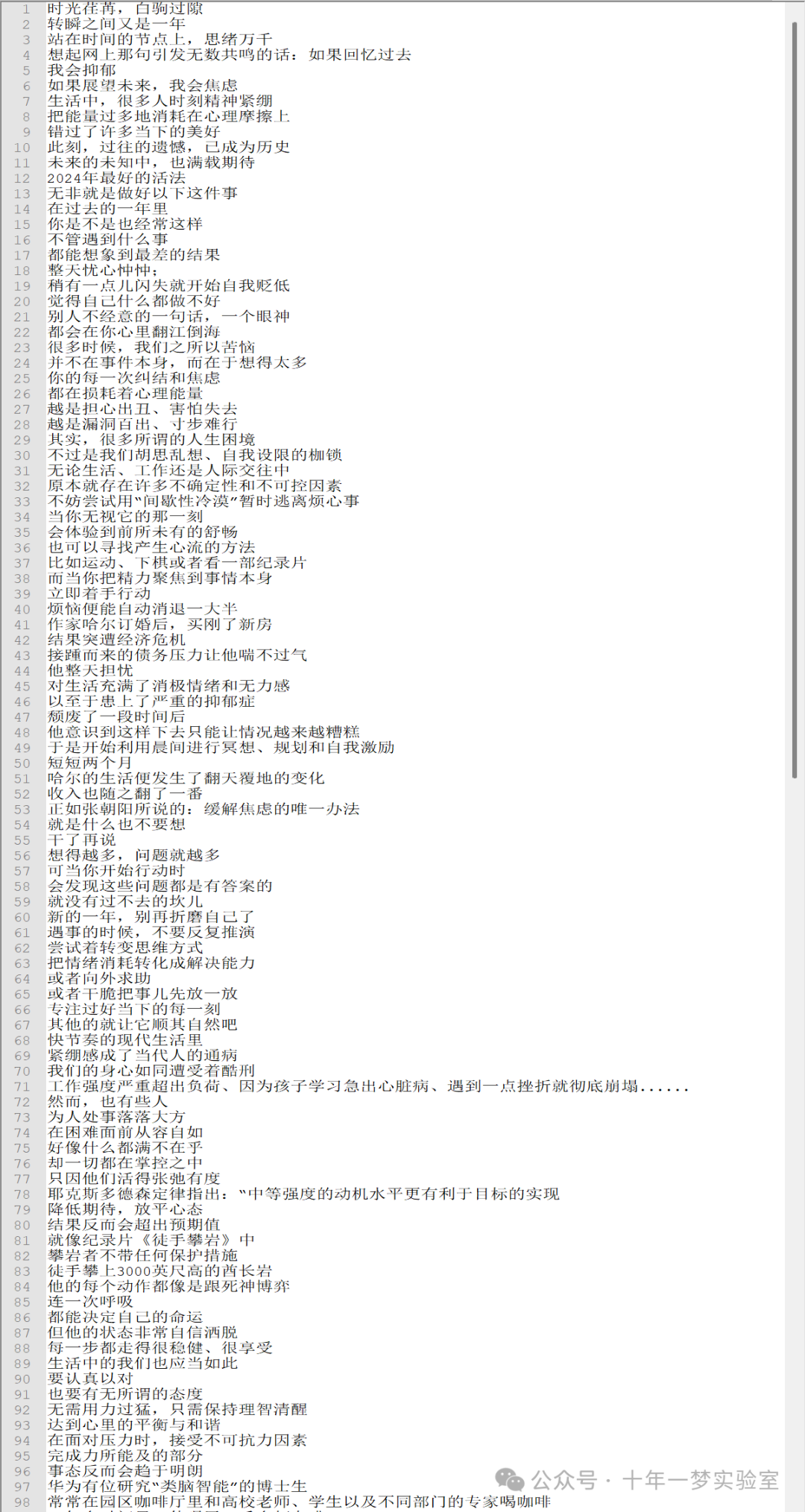
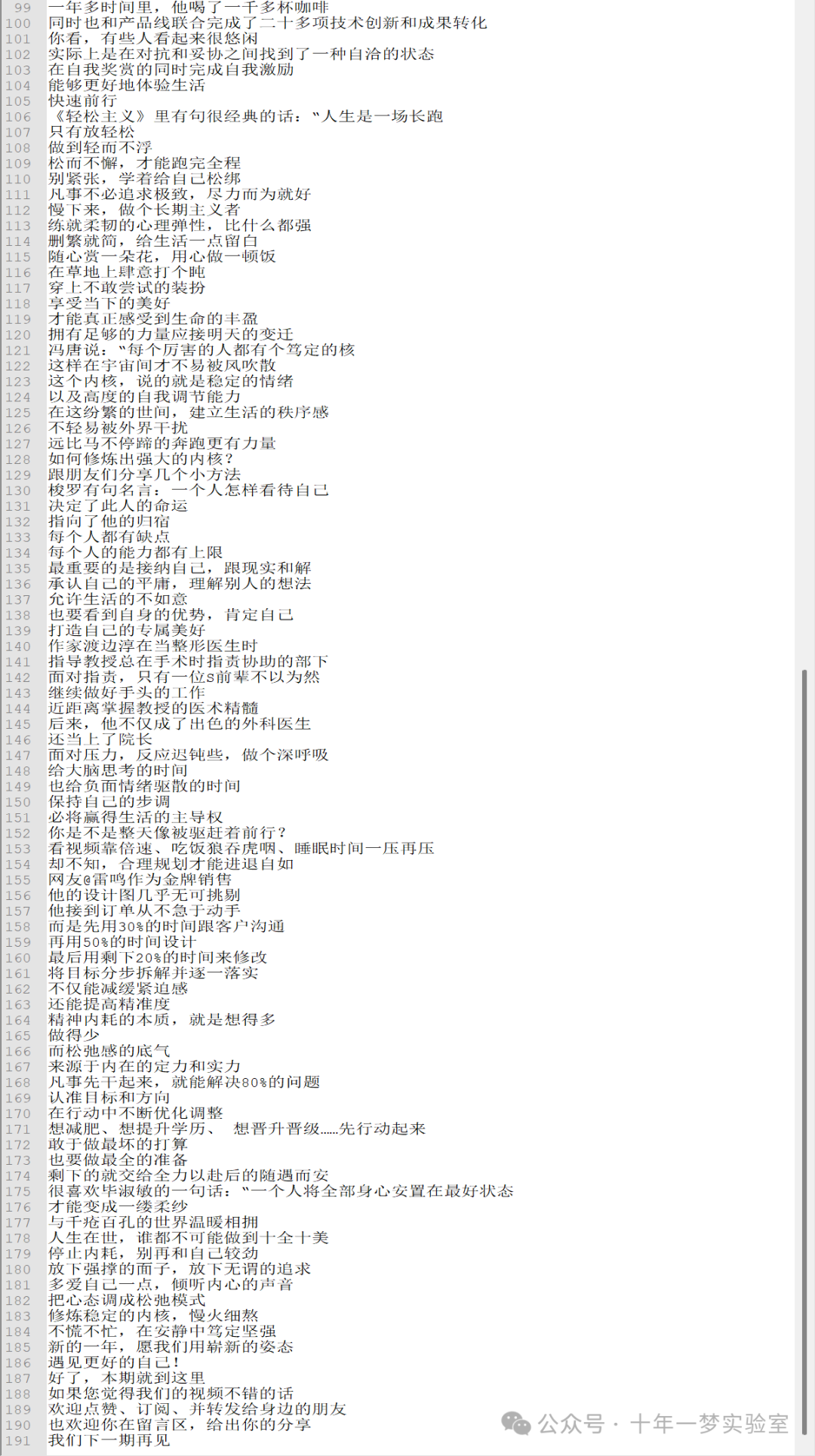
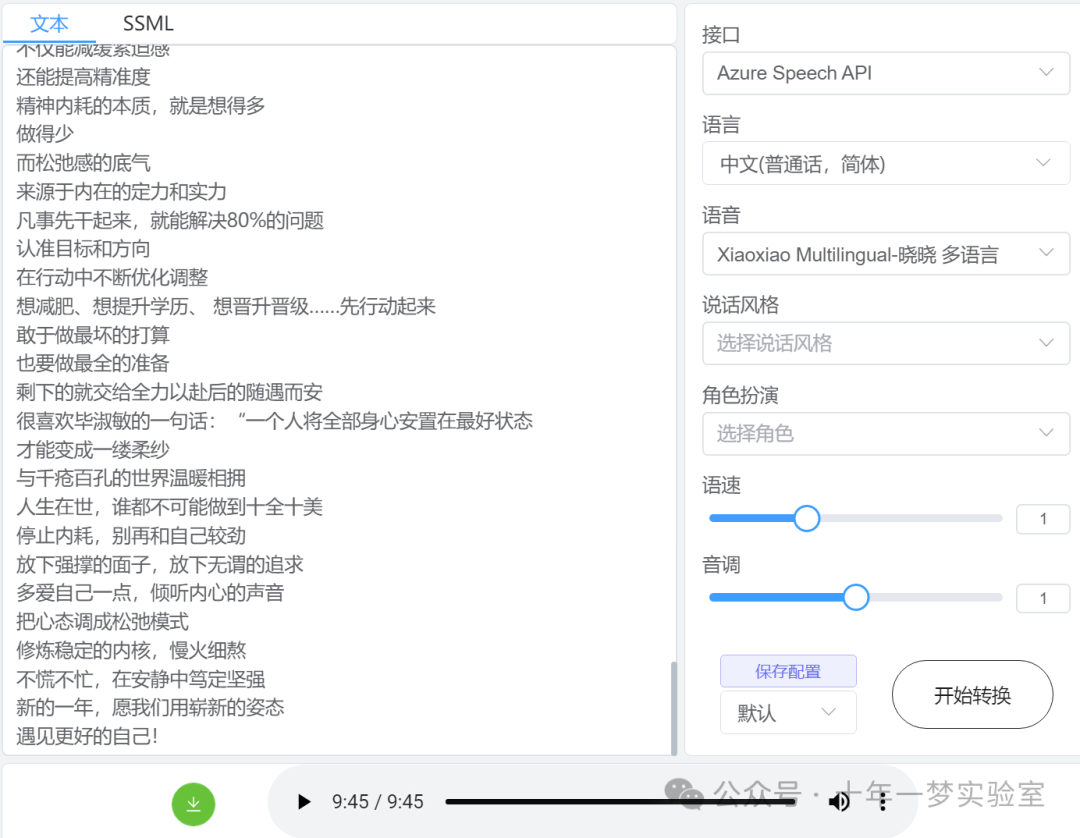
生成的字幕使用Azure Speech API文本转语音:(选择最新的XiaoXiao-Multilingual)

















 5979
5979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









