






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
目录
前言
提示:以下是本篇文章正文内容,下面案例可供参考
一、BP神经网络是什么?
BP神经网络(Backpropagation Neural Network)是一种常用的人工神经网络模型,广泛应用于机器学习和深度学习领域。它是一种前向反馈的神经网络模型,通过反向传播算法进行训练和优化。
BP神经网络由输入层、隐藏层和输出层组成,其中隐藏层可以包含多个层次。每个层次由多个神经元节点组成,神经元之间的连接具有权重。输入层接收原始数据,隐藏层通过计算和传递信息,最终输出层给出网络的预测结果。
BP神经网络的训练过程通过反向传播算法进行,该算法通过计算预测结果与实际结果之间的误差,并将误差从输出层反向传播到隐藏层和输入层,根据误差调整权重值。这个过程通过梯度下降法来最小化损失函数,使网络的预测结果与实际结果尽可能接近。
二、使用步骤
1.导入数据
%% 导入数据
res = xlsread("C:\Users\86182\Desktop\时间序列\工商银行.xlsx"');
[m,n]=size(res)2.划分训练集和测试集
rand('seed',70);
temp = 1: 1: m;
round(m*0.7)
P_train = res(temp(1: round(m*0.9)), [1:3,5:10])';
T_train = res(temp(1: round(m*0.9)), 4)';
M = size(P_train, 2);
P_test = res(temp(round(m*0.9)+1: end), [1:3,5:10])';
T_test = res(temp(round(m*0.9)+1: end), 4)';
N = size(P_test, 2);设置随机种子,因为bp神经网络每次运行不一样。
3.数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
消除单位和数值的影响
4.创建网络
net = newff(p_train, t_train, 5);设计隐藏层的个数,可调
其中h为隐含层节点数目,m为输入层节点数目,n为输出层节点数目,,a为1~10之间的调节常数。
5.设置训练参数
%% 设置训练参数
net.trainParam.epochs = 1000; % 迭代次数
net.trainParam.goal = 1e-6; % 误差阈值
net.trainParam.lr = 0.01; % 学习率
以上是参数,可调整。
6.训练网络
net = train(net, p_train, t_train);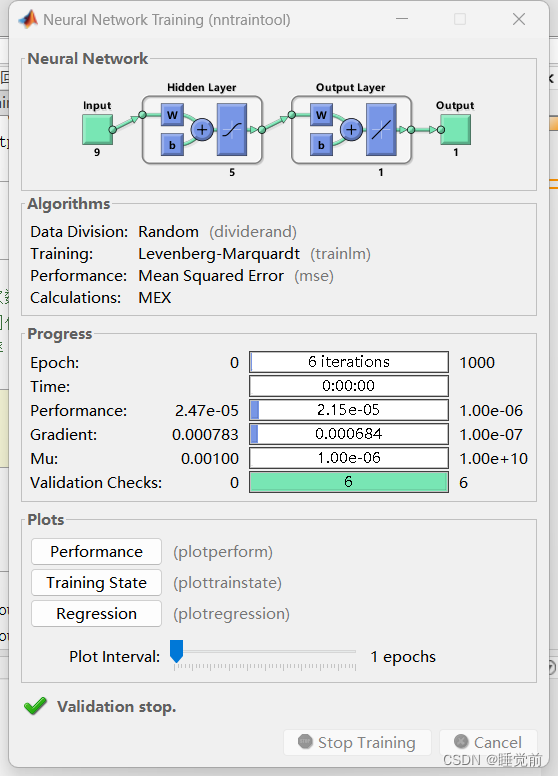
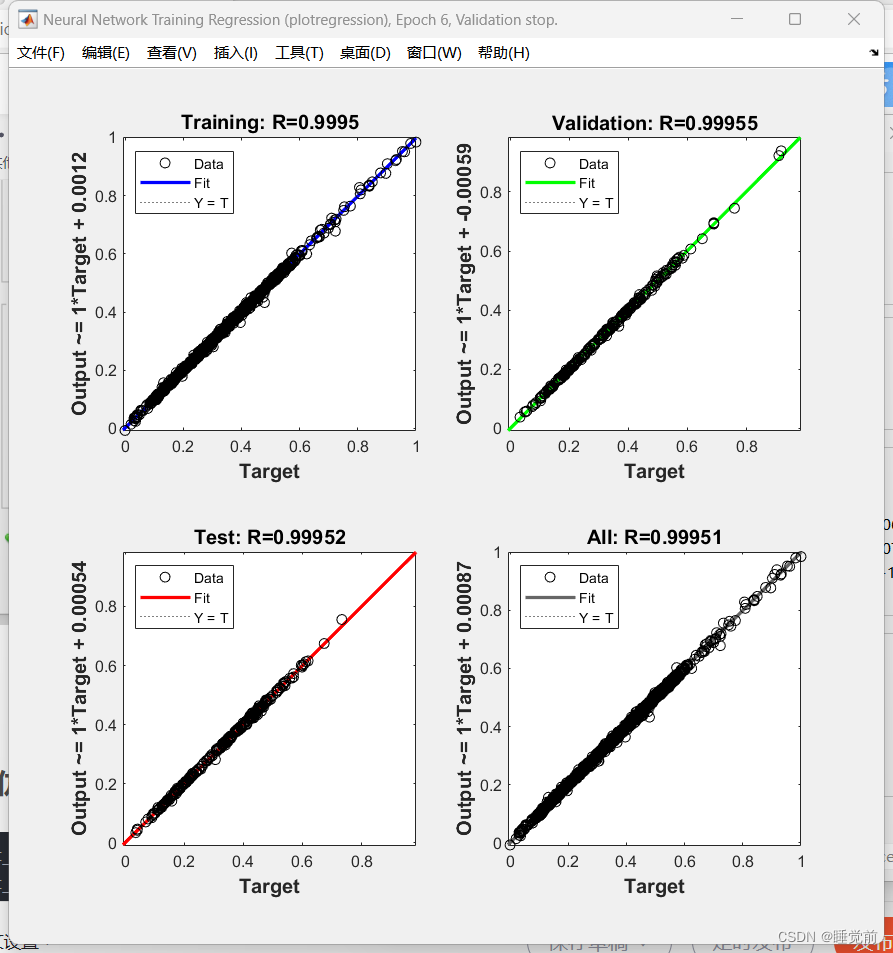
以上图像不做解释,可参考相关论文知道其意思。
7.仿真测试
t_sim1 = sim(net, p_train);
t_sim2 = sim(net, p_test);8.数据反归一化
T_sim1 = mapminmax('reverse', t_sim1, ps_output);
T_sim2 = mapminmax('reverse', t_sim2, ps_output);
9. 绘图
figure
plot(1: M, T_train, 'r-*', 1: M, T_sim1, 'b-o', 'LineWidth', 1)
legend('真实值','预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'训练集预测结果对比'; ['RMSE=' num2str(error1)]};
title(string)
xlim([1, M])
grid
figure
plot(1: N, T_test, 'r-*', 1: N, T_sim2, 'b-o', 'LineWidth', 1)
legend('真实值','预测值')
xlabel('预测样本')
ylabel('预测结果')
string = {'测试集预测结果对比';['RMSE=' num2str(error2)]};
title(string)
xlim([1, N])
grid
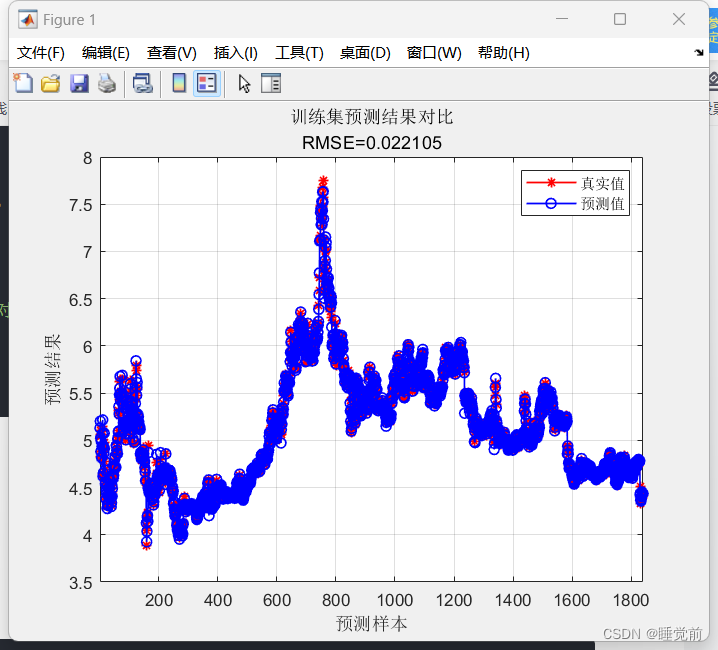
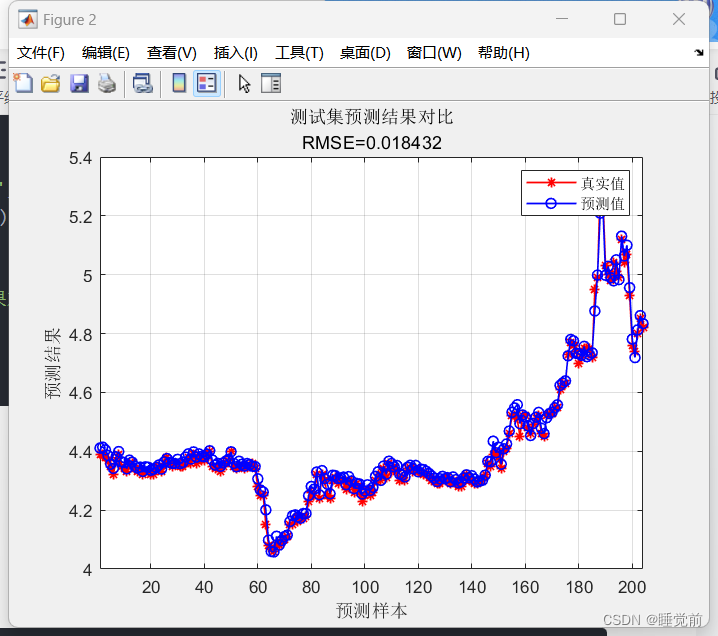
仅从图像来看,拟合情况还是很好的。具体模型评估还得相关指标。
10.模型评估
%% 相关指标计算
% R2
R1 = 1 - norm(T_train - T_sim1)^2 / norm(T_train - mean(T_train))^2;
R2 = 1 - sum((T_test - T_sim2).^2) / sum((T_test - mean(T_test )).^2);
disp(['训练集数据的R1为:', num2str(R1)])
disp(['测试集数据的R2为:', num2str(R2)])
% MAE
mae1 = sum(abs(T_sim1 - T_train)) ./ M ;
mae2 = sum(abs(T_sim2 - T_test)) ./ N ;
disp(['训练集数据的MAE为:', num2str(mae1)])
disp(['测试集数据的MAE为:', num2str(mae2)])
% MBE
mbe1 = sum(T_sim1 - T_train) ./ M ;
mbe2 = sum(T_sim2 - T_test) ./ N ;
disp(['训练集数据的MBE为:', num2str(mbe1)])
disp(['测试集数据的MBE为:', num2str(mbe2)])
mse1 = sqrt(sum((T_sim1 - T_train).^2)) ./ M;
mse2 = sqrt(sum((T_sim2 - T_test).^2)) ./ N;
disp(['训练集数据的MSE1为:', num2str(mse1)])
disp(['测试集数据的MSE2为:', num2str(mse2)])
rmse1 = sqrt(mean((T_sim1 - T_train).^2));
rmse2 = sqrt(mean((T_sim2 - T_test).^2));
disp(['训练集数据的RMSE1为:', num2str(rmse1)])
disp(['测试集数据的RMSE2为:', num2str(rmse2)])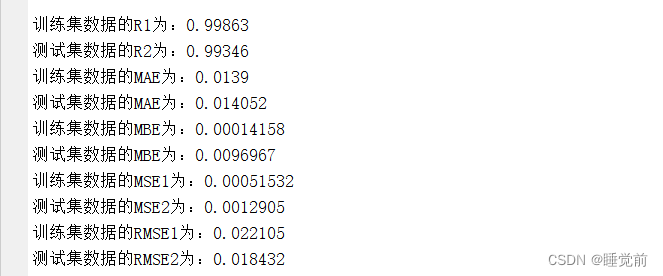
可见拟合优度很高,其他指标也很好。
总结
因为本篇文章预测的收盘价中用来回归的自变量含有开盘价,涨幅和收盘价等其他指标,这种预测值用手算也能算出来。所以本篇只作为参,具体问题,自变量的选取很重要。模型优度就不一定有这么好了。















 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









