








这是我在mooc中听课的一部分截图,主要是方便以后自己学习!其中主要从以上几个方面来讲解python网络爬虫和信息提取。

requests库的七个常用方法,其中get方法经常使用到。截图很清晰明了了。


其中r=resquests.get("http://www.baidu.com")中的r是一个response对象,这句话用于链接对应的url,还有就是那个返回值200表示正确链接了。否则就是错误的。


这些异常都是在做爬虫工作中的一些常见异常,如果出现对应的错误,再找对应的解决办法。(后续补充)

以上的代码主要是为了获取html的一个文本信息。


我们可以理解为我们客户向云端通过URL链接,然后向通过get和head方法来获取一些信息。



r,text得到具体的文本数据。
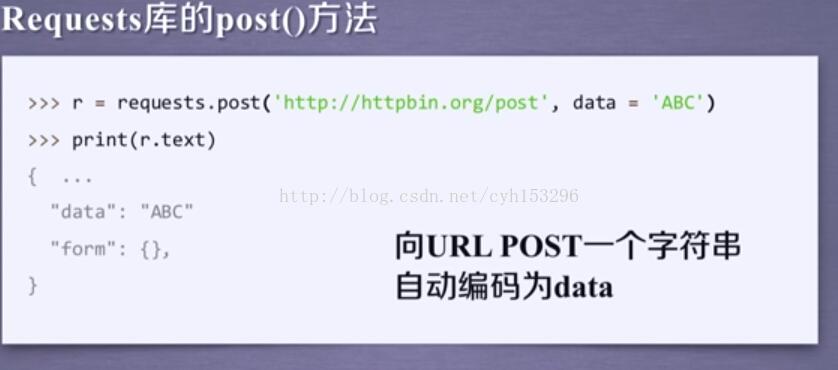
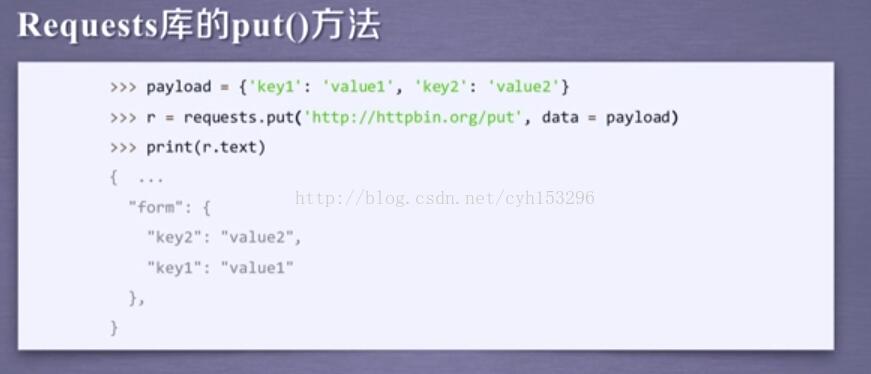

这就是之前说的那七个常见方法。

把一些键值对增加到对应的url中,并且可以再增加一些参数,进一步获取链接 ,比如一些网站的进一步链接。。。


http://www.icourse163.org/learn/BIT-1001870001?tid=1001962001 这就是之前的听课的一部分内容。。。yhk















 3189
3189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









