







 本文详细介绍了ID3决策树的概念,包括信息熵和信息增益的计算。ID3算法适用于标称数据分类,通过信息增益选择最优特征进行数据集划分。文章通过实例展示了ID3决策树的构建过程,并讨论了ID3算法存在的问题,如偏好类别多的特征,以及计算效率问题。
本文详细介绍了ID3决策树的概念,包括信息熵和信息增益的计算。ID3算法适用于标称数据分类,通过信息增益选择最优特征进行数据集划分。文章通过实例展示了ID3决策树的构建过程,并讨论了ID3算法存在的问题,如偏好类别多的特征,以及计算效率问题。
一、什么是ID3决策树
决策树概念:机器学习之决策树–原理分析
ID3决策树是由Ross Quinlan在1986年提出的一种决策树,其可以说是决策树的最早实现,之后发展的决策树系列算法都是在ID3的基础上变化发展而来。
ID3主要用于对标称数据进行分类,而未涉及对数值属性的分类。
ID3算法用信息熵变化产生的信息增益做为最优特征的选择依据,即每一步都选择信息增益最大的特征进行数据集划分。
二、什么是信息熵?
1850年,德国物理学家克劳休斯提出“熵”(Entropy)的概念,表示能量在空间分布的均匀程度,能量分布越均匀,熵越大。
1948年,香农在他的《信息论》中借用“熵”的概念,提出“信息熵”。在“信息熵”概念之前的概念是“信息量”,认为某一个事件发生的概率越大,其信息量越小,因为其不确定性小,导致里面包含的信息少,反之,发生的概率越小,其信息量越大。举个例子:你每天都6点钟放学到家,今天你也6点钟到家了,跟平常一样,所以你爸妈不会觉得有什么问题,因为这个概率非常大,也就是说这个信息量小。但是如果你今天9点钟还没有到家,和平常相差太大,你爸妈肯定觉得里面有问题,就会满世界找你,因为这个概率非常太小,一旦发生就证明其中有很多反常的事情发生,所以说这个事情的信息量就大了。
信息量的计算函数:事件U发生的概率是p,则该事件包含的信息量为:
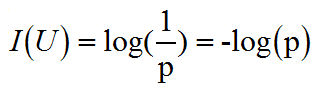
在一个信源中,不能仅仅考虑单一事件发生的不确定性,而是要考虑所有可能事件的平均不确定性。在考虑平均不确定性时,通常认为各个可能事件是相互独立的关系,所以可以将所有可能事件的信息量求期望,该期望就是“信息熵”。
信息熵的计算函数:事件U可能有n个可能,分别为U1,U2,U3……Un,对应的发生概率为p1,p2,p3……pn,则该事件的信息熵为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2311
2311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









