







推荐系统实战系列篇是根据王喆老师在极客时间上的深度学习推荐系统实战课,并结合自己的所学所思所悟创作的,希望该系列可以跟志同道合的朋友一起探讨学习。
推荐系统demo - Sparrow Recsys
- clone代码
- 安装软件和环境
- 运行推荐系统
源代码放在github上 https://github.com/wzhe06/SparrowRecSys,可以通过 git clone https://github.com/wzhe06/SparrowRecSys.git命令,或者从 Web 端下载的方式,把代码下载到本地。
打开工具:IntelliJ IDEA
环境安装:
- Java 8
- Scala 2.11
- Python 3.6+(最好是3.6,比较稳定)
- TensorFlow 2.0+
注释:jdk和Scale版本需要一致。版本匹配
如果大家有需要的话,后续可以专门写一篇下载并安装IntelliJ IDEA全过程的文章。
打开本地的 Sparrow Recsys 项目根目录,如果项目没有自动识别为 maven project,还需要右键点击 pom.xml 文件,选择Maven,将该项目设置为 maven project。
项目编译完毕后,用快捷键Command+Shift+F (Mac)找到项目的主函数com.wzhe.sparrowrecsys.online.RecSysServer,右键点击运行。因为推荐服务器默认运行在 6010 端口,所以我们打开浏览器,输入http://localhost:6010/,就能看到整个推荐系统的前端效果了。

Sparrow Recsys的功能
- 首页:按照平均分排序
- 电影详情页:相似影片推荐
- 为你推荐页:个性化推荐
原始数据来源
它的数据源来自于著名的电影开源数据集MovieLens。
-
movies.csv(电影基本信息数据)
movies 表是电影的基本信息表,它包含了电影 ID(movieId)、电影名(title)、发布年份以及电影类型(genres)等基本信息。
MovieLens 20M Dataset 包含了 2016 年前的约 13 万部电影,实验数据集从中抽取了前 1000 部电影。
-
ratings.csv(用户评分数据)
ratings 表包含了用户 ID(userId)、电影 ID(movieId)、评分(rating)和时间戳(timestamp)等信息。
MovieLens 20M Dataset 包含了 2000 万条评分数据,实验数据集从中抽取了约 104 万条评论数据。
-
links.csv(外部链接数据)
links 表包含了电影 ID(movieId)、IMDB 对应电影 ID(imdbId)、TMDB 对应电影 ID(tmdbId)等信息。
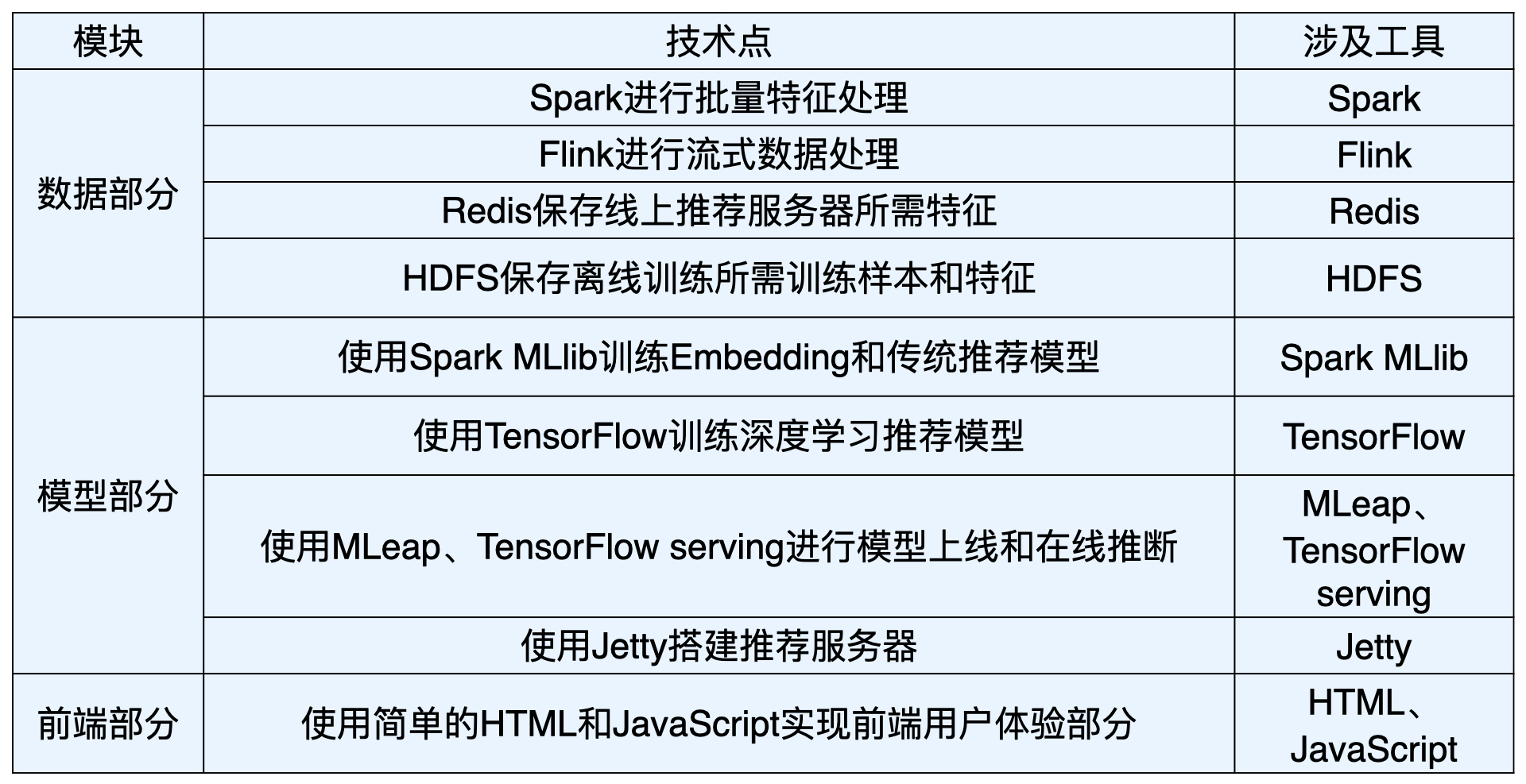
Sparrow Recsys 技术架构
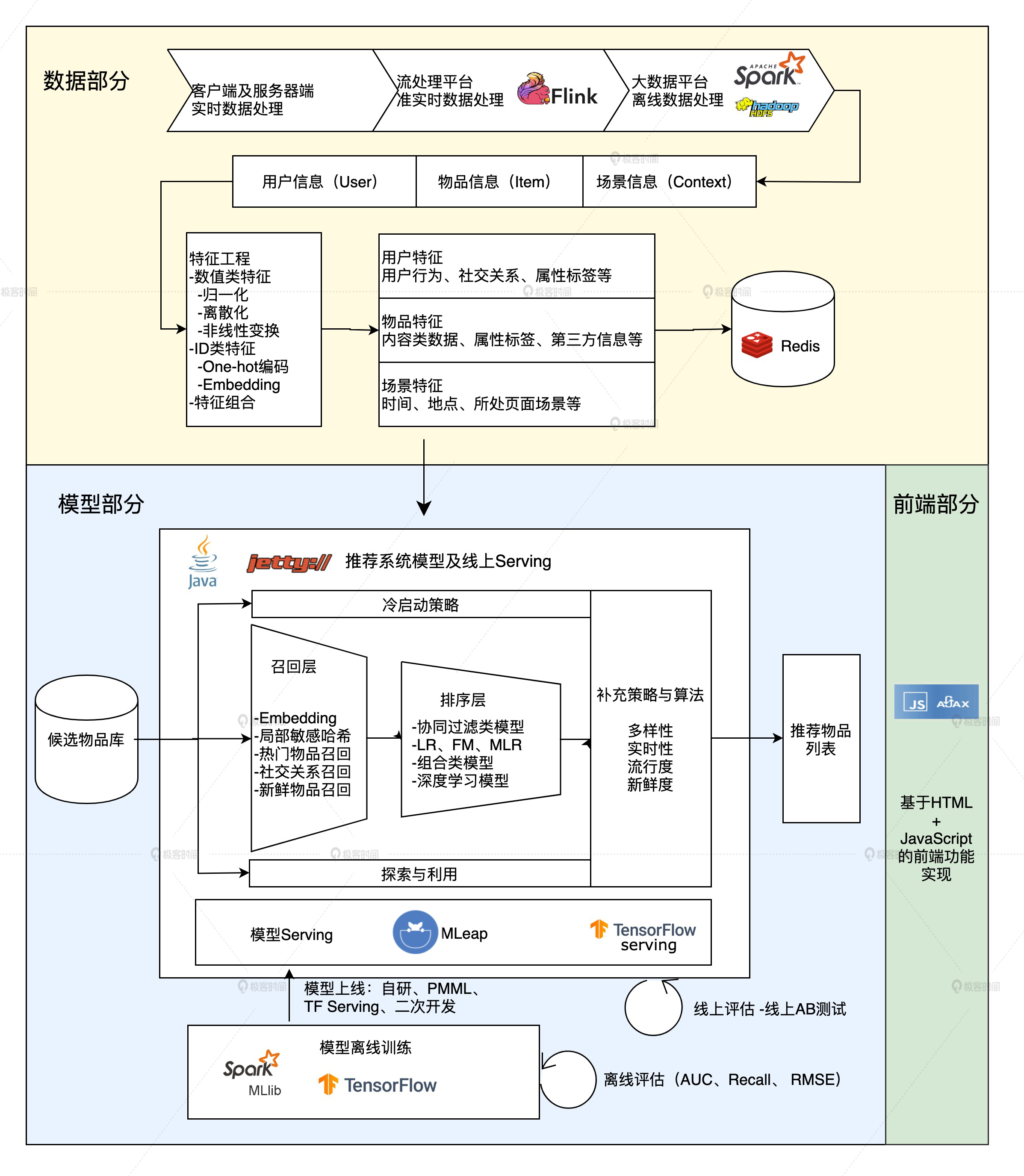
一共分为三个模块,分别是数据、模型和前端。















 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









