







embedding+MLP用一句话总结就是:对于类别特征,先利用 Embedding 层进行特征稠密化,再利用 Stacking 层连接其他特征,输入 MLP 的多层结构,最后用 Scoring 层预估结果。
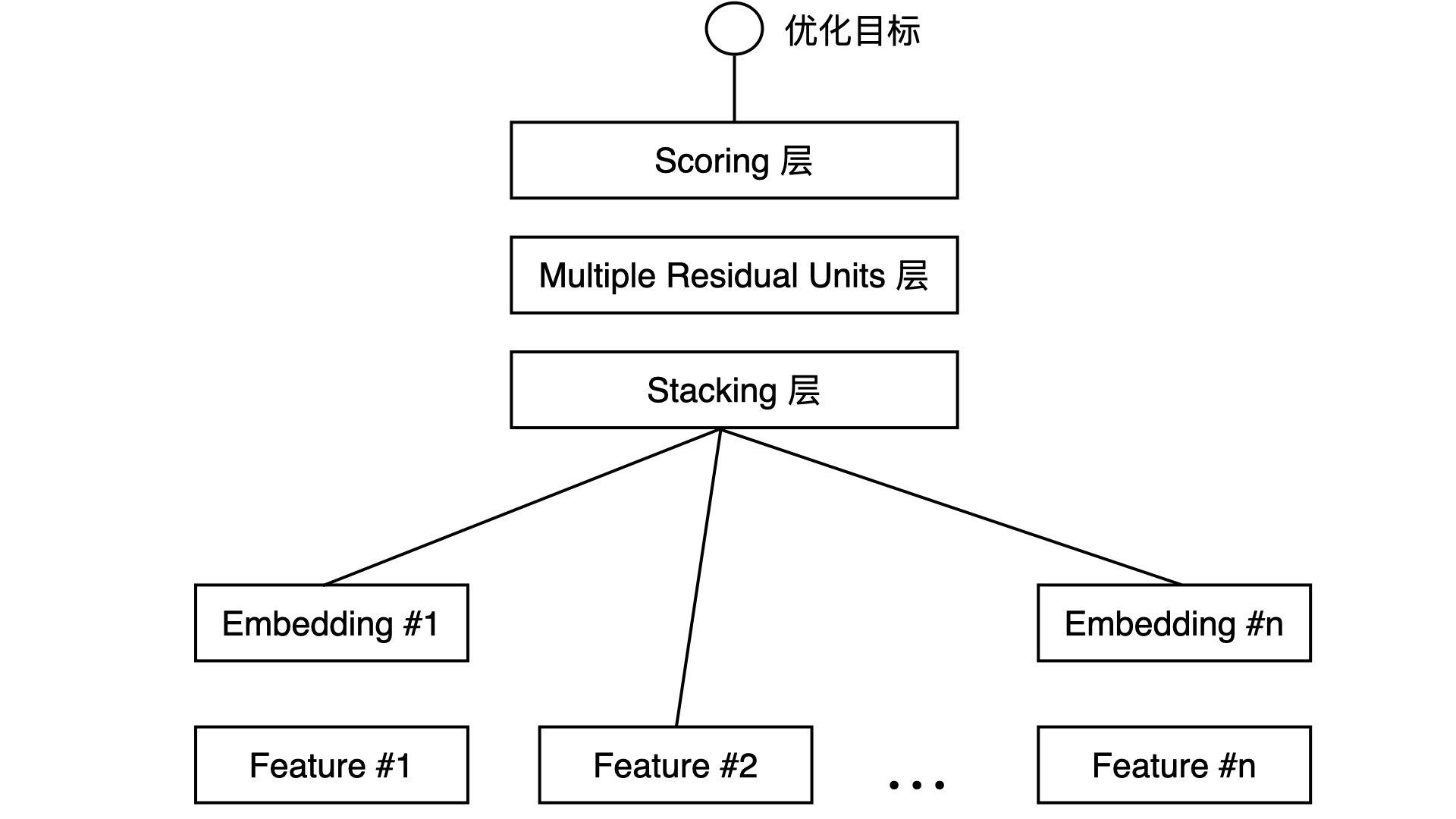
具体步骤为:
-
将分类特征embedding,转为N维的稠密向量。
-
数值特征不做处理。
-
将embedding后的向量和数值向量进行concat操作,也就是Stacking层
-
输入MLP层,全连接充分交叉,中间层输出为128维,使用RELU激活函数(维度和激活函数根据具体项目按照经验调节)。
-
输出为1维向量,使用sigmoid激活函数。
预测电影评分实战代码如下,代码见EmbeddingMLP.py:
import tensorflow as tf
# Training samples path, change to your local path
training_samples_file_path = tf.keras.utils.get_file("trainingSamples.csv",
"file:///Users/xxx/workspace/SparrowRecSys/src/main"
"/resources/webroot/sampledata/trainingSamples.csv")
# Test samples path, change to your local path
test_samples_file_path = tf.keras.utils.get_file("testSamples.csv",
"file:///Users/xxx/workspace/SparrowRecSys/src/main"
"/resources/webroot/sampledata/testSamples.csv")
# load sample as tf dataset
def get_dataset(file_path):
dataset = tf.data.experimental.make_csv_dataset(
file_path,
batch_size=12,
label_name='label',
na_value="0",
num_epochs=1,
ignore_errors=True)
return dataset
# split as test dataset and training dataset
train_dataset = get_dataset(training_samples_file_path)
test_dataset = get_dataset(test_samples_file_path)
# genre features vocabulary
genre_vocab = ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War', 'Comedy', 'Western', 'Documentary',
'Sci-Fi', 'Drama', 'Thriller',
'Crime', 'Fantasy', 'Animation', 'IMAX', 'Mystery', 'Children', 'Musical']
GENRE_FEATURES = {
'userGenre1': genre_vocab,
'userGenre2': genre_vocab,
'userGenre3': genre_vocab,
'userGenre4': genre_vocab,
'userGenre5': genre_vocab,
'movieGenre1': genre_vocab,
'movieGenre2': genre_vocab,
'movieGenre3': genre_vocab
}
# all categorical features
categorical_columns = []
for feature, vocab in GENRE_FEATURES.items():
cat_col = tf.feature_column.categorical_column_with_vocabulary_list(
key=feature, vocabulary_list=vocab)
emb_col = tf.feature_column.embedding_column(cat_col, 10)
categorical_columns.append(emb_col)
# movie id embedding feature
movie_col = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
movie_emb_col = tf.feature_column.embedding_column(movie_col, 10)
categorical_columns.append(movie_emb_col)
# user id embedding feature
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, 10)
categorical_columns.append(user_emb_col)
# all numerical features
numerical_columns = [tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev')]
# embedding + MLP model architecture
model = tf.keras.Sequential([
tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
# compile the model, set loss function, optimizer and evaluation metrics
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy', tf.keras.metrics.AUC(curve='ROC'), tf.keras.metrics.AUC(curve='PR')])
# train the model
model.fit(train_dataset, epochs=5)
# evaluate the model
test_loss, test_accuracy, test_roc_auc, test_pr_auc = model.evaluate(test_dataset)
print('\n\nTest Loss {}, Test Accuracy {}, Test ROC AUC {}, Test PR AUC {}'.format(test_loss, test_accuracy,
test_roc_auc, test_pr_auc))
# print some predict results
predictions = model.predict(test_dataset)
for prediction, goodRating in zip(predictions[:12], list(test_dataset)[0][1][:12]):
print("Predicted good rating: {:.2%}".format(prediction[0]),
" | Actual rating label: ",
("Good Rating" if bool(goodRating) else "Bad Rating"))

















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









