







没代码
1 动机
目前基于强化学习的推荐系统在多行为推荐中存在兴趣差距问题,即用户在不同行为(如点击、加购、购买)上的兴趣是不同的。例如,用户可能对某个商品感兴趣并点击它,但最终却没有购买。需要针对不同行为采用不同的推荐策略,而不是统一处理所有行为。现有方法独立建模不同行为,忽略了不同行为之间的特性。并且所有行为共用一个推荐策略,导致信息的混杂,影响最终推荐效果 。
2 贡献
1:首次将多行为推荐视为多任务学习问题提出 MTRL4Rec 框架,利用强化学习优化推荐策略。通过引入模块化网络(建模不同行为的特性)和任务路由网络,动态调整不同行为任务所使用的模块化单元,从而确保不同行为的推荐路径最优,提升任务间信息共享和差异化建模能
2:结合分层强化学习,采用高层代理(负责决策推荐类别)和低层代理(选择具体推荐物品),提高推荐效率和策略优化能力。
3 强化学习
代理-执行推荐操作的智能体,它根据环境的状态(用户历史行为、偏好等)选择最优动作(推荐物品)DQN
状态-在推荐系统中通常表示用户的历史行为、兴趣偏好或当前上下文。
动作-推荐系统做出的决策(推荐物品)
奖励-是对 Agent 推荐决策的反馈(如购买)
环境-用户和推荐系统之间的交互
策略-是 Agent 在不同状态下选择动作的规则
DQN (Deep Q-Network,深度 Q 网络):它的目标是学习一个 状态-动作值函数 Q(s,a),使得在给定状态 s 下,选择动作 a 能获得最大化的累积奖励。
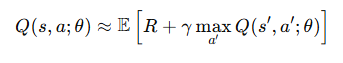
DQN的训练数据存储在一个回放缓冲区中,随机采样小批量数据进行训练,减少样本相关性,提高稳定性。然而DQN 计算下一个状态的 Q 值时,使用同一个网络进行动作选择和 Q 值计算,直接取最大 Q 值,可能会过高估计,导致不稳定。
![]()
因此DDQN 使用两个独立的 Q 网络,解决了 DQN 过估计问题。先用在线网络选择最优动作![]() ,再用目标网络计算 Q 值
,再用目标网络计算 Q 值![]() 。
。
4 多行为推荐的基础RL模型
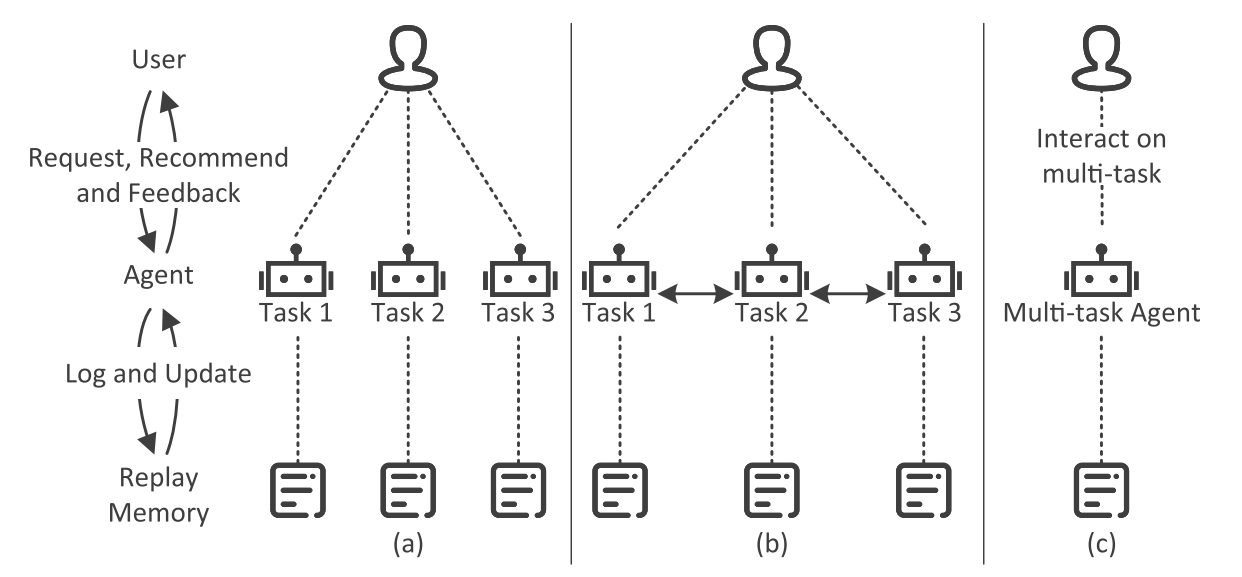
现有的基于强化学习的推荐方法实现多行为推荐的两种方法。 如图(a)所示,每个行为(如点击、加购、购买)都由单独的代理进行建模,彼此独立,没有信息共享。 图(b)描述了另一种方法,但仍然是多个独立的 RL 代理,但它们可以共享彼此的状态、动作和奖励,以提升学习效率。
算法1是单任务强化学习的离线训练,代理和经验回放池在第1-2行中初始化。 在每个会话的开始,使用前一个会话作为当前状态(第4行)。如果用户没有前一个会话,是一个空序列。 遍历任务列表 task_list,为每个任务生成一个推荐物品 at(第 6-8 行);观察用户的行为 t(例如,用户是否点击/加购/购买)(第 9 行);基于用户行为推荐物品 at(第 10 行)记录用户反馈和下一个状态 st+1(第 11 行);存储这次交互记录到经验回放 Dt(第 12 行);从经验回放 Dt 采样数据,更新当前任务的强化学习代理 At(第 13-14 行);如果 st+1 是终止状态(session 结束),跳出循环。第 15-16 行)

因此不管是单任务还是多个独立的任务都不能充分挖掘不同行为之间的共性(“加购” 和 “购买” 可能具有高度相似的行为模式),图(b) 允许代理之间共享状态和奖励,并且无法高效建模不同行为的特性(例如,用户可能对某个商品感兴趣,但仅点击而不购买)。导致各个任务仍然相对独立,无法形成更有效的策略优化。因此MTRL4Rec(图c)通过单一的代理来同时管理所有行为任务,并采用模块化网络和任务路由网络来动态分配任务。
5 模型
5.1 分层强化学习
传统的强化学习导致不同行为之间的共同特征无法共享,导致每个行为的推荐策略孤立训练。分层强化学习由两个层次的 RL 代理组成,高层代理HRA负责选择推荐的类别,低层代理LRA在 HRA 选定的类别中,选择具体的物品,如下图所示。
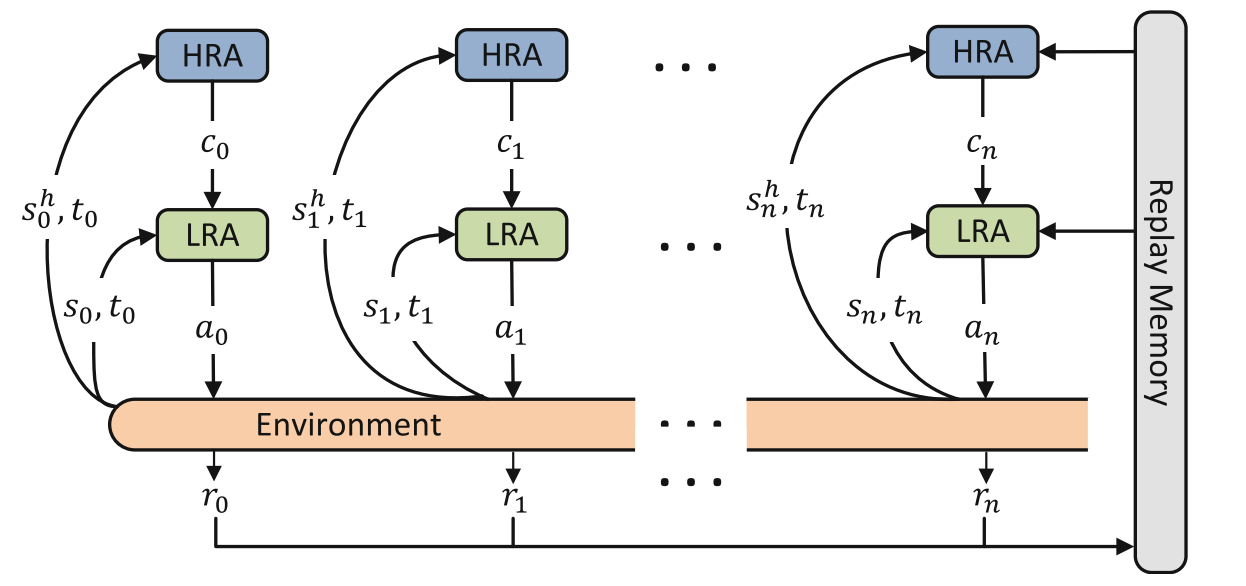
高层代理(HRA)通过 Q-learning 选择类别,类别信息是数据集中项目的一个属性。
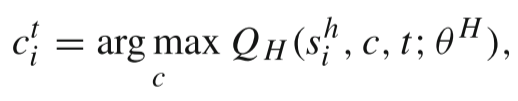
HRA 是一个全局策略,可以共享不同行为任务之间的信息,从而更好地捕捉用户的全局兴趣。 采用 ϵ贪心策略(1−ϵ概率选择最佳类别,ϵ概率随机探索新类别),提高探索能力。
低层代理(LRA) 在 HRA 选定类别的限制下选择具体物品
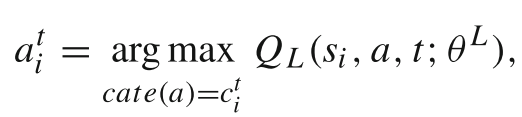
5.2 低层代理网络
LRA网络结构如下图所示。 它有三个重要组成部分(嵌入、任务路由网络和模块化网络)。嵌入层处理输入数据,将离散数据转换为连续向量;任务路由网络: 决定不同行为在模块化网络中的计算路径;模块化网络共享任务间的共同信息,同时保持任务的独立性,提高推荐性能。
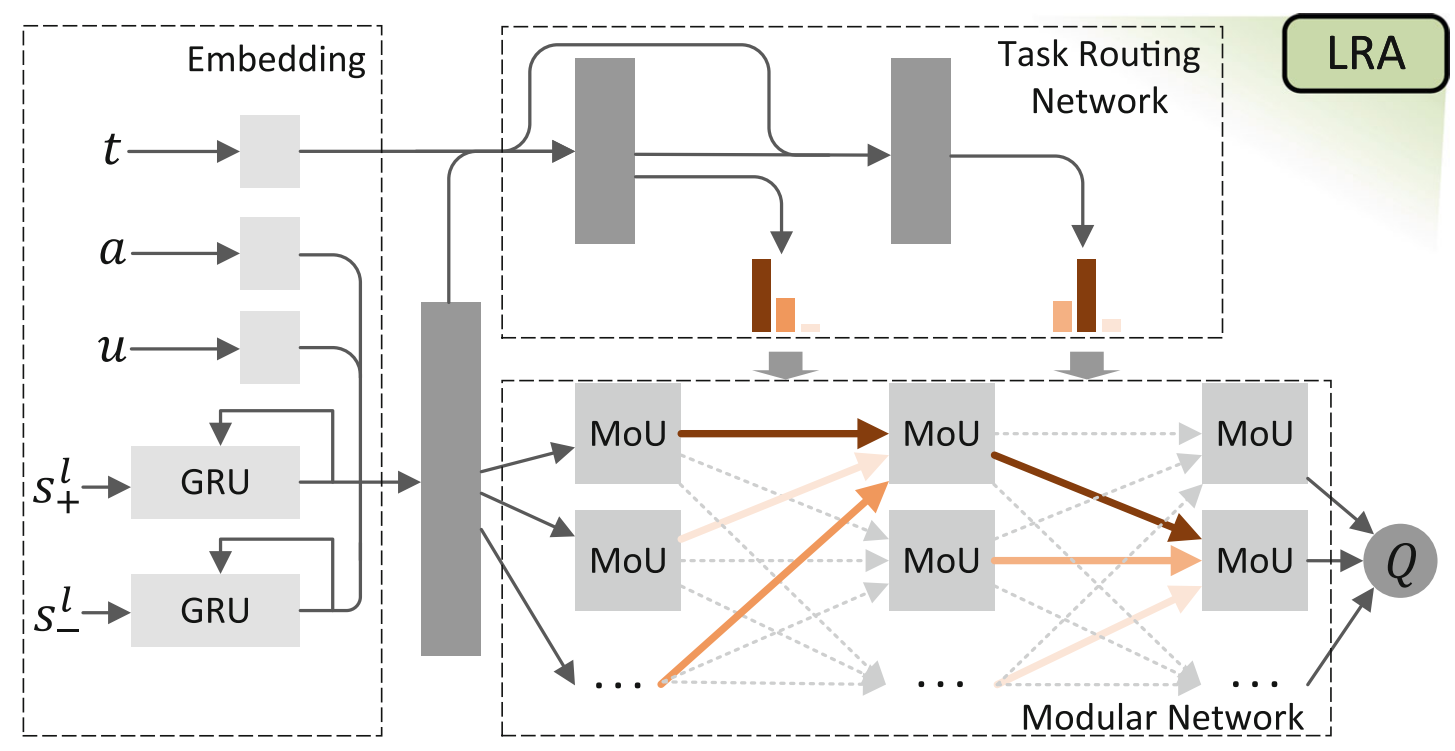
5.2.1 嵌入层
将用户、任务和动作(推荐的物品) 转换为向量表示,采用 GRU进行序列建模,提取历史行为模式。输入包括用户 ID u,行为标签 t,物品 ID a,正样本序列s+ 用户交互过的物品,负样本序列s− 用户跳过的物品。
使用两个GRU 处理正样本序列和负样本序列,最终将 用户嵌入、任务嵌入、物品嵌入、正负样本序列嵌入进行拼接,并通过一个全连接层作为任务路由网络(TRN)的输入
5.2.2 模块化网络
模块化网络来捕捉共性(多行为之间相似的行为模式)。 模块化网络有多层,每层有M个模块单元,如上图所示。 通过这种方式,不同行为可以共享部分 MoU(多层全连接网络,用于提取行为特定的特征),同时保持个性化计算路径。 每个MoU都具有相同的多层全连接结构,如下图所示MoU计算如下:
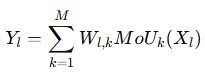
Wl,k 由任务路由网络控制,MoUk(Xl) 是第 k个 MoU 的输出。
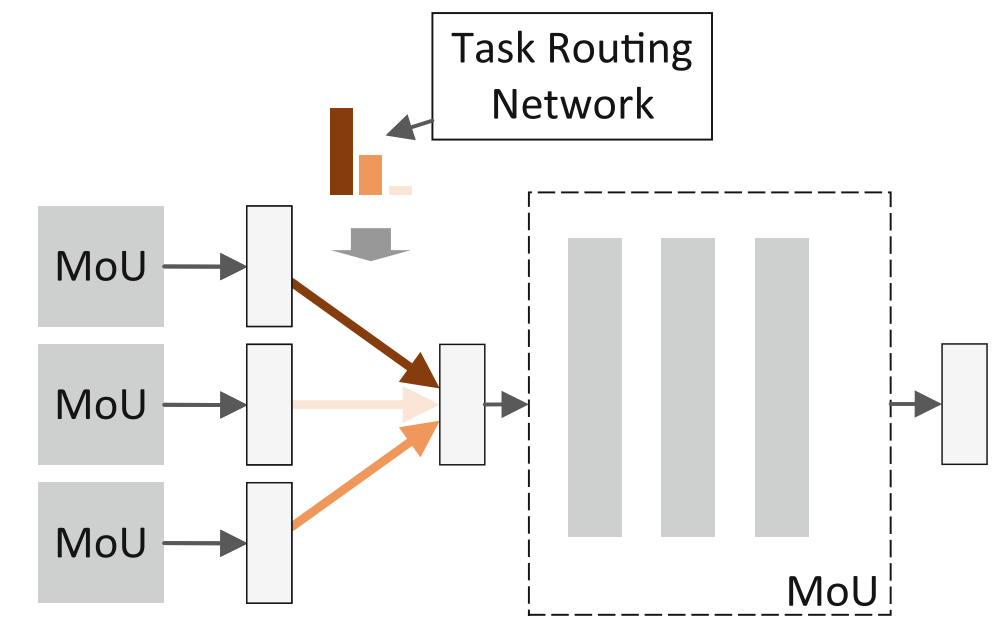
5.2.3 任务路由网络
任务路由网络TRN的作用是对模块化网络中不同行为的计算路径进行控制。 它通过控制哪些Mou被激活来为模块化网络中的不同行为选择不同的路径,不同任务行为具有个性化计算路径,避免不同行为相互干扰。除了当前状态,任务路由网络的输入还包含当前行为。 TRN采用多层结构,每层会输出一个权重矩阵 Wl和隐藏状态 Hl:
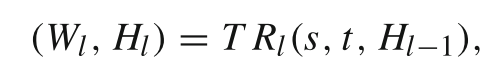
s 是当前状态的嵌入,t 是行为的嵌入,Hl−1 是上一层的隐藏状态,Wl 是该层的权重矩阵,用于重新加权模块化网络(MoUs) 的输出,任务路由网络生成的 权重矩阵 控制每个 Modular Unit(MoU) 的计算:
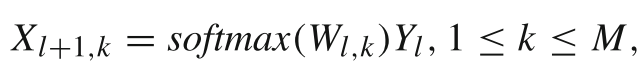
Wl,k 是 第 k 个 MoU 的权重,Yl 是上一层模块化网络(MoU)的输出,通过 softmax 归一化权重,动态控制 MoU 的计算贡献
4.3 训练
LRA 采用DQN,优化 Q 值:
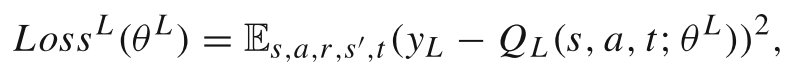
yL是当前迭代的目标:
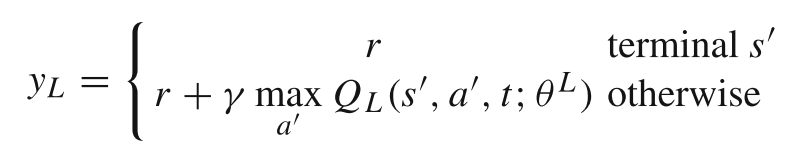
r 是即时奖励,γ 是折扣因子,通过优化 LRA 选择物品的策略,使得 Q 值最大化。类似地,HRA忽略特定项,并为每个行为生成候选类别。 HRA网络损失函数:
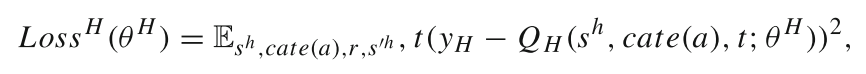
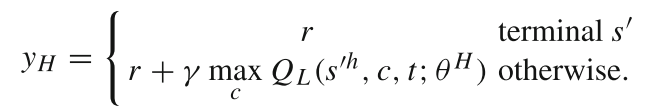
MTRL4Rec训练过程如下:
初始化 LRA 网络参数 θL,创建经验回放池 D;每次交互时由 HRA 选择类别 cti--由 LRA 在该类别中选择具体物品 ati--观察用户反馈(是否点击/购买),若购买则加入正样本序列--计算奖励 r并存入经验回放池 D,从D中采样数据 (s,t,a,r,s′)进行更新

那么由于在第三节讲的,DQN会导致Q 值过估计,MTRL4Rec进一步采用了DDQN方法。
6 总结
MTRL4Rec采用多任务学习 方法,将每种行为独立的数据存储。那么在选择最优动作时,在多个行为序列里通过计算Q值来选取物品,但不同任务也有共性,任务路由网络自适应地决定哪些行为可以共享,如果加购和购买具有类似的行为模式,TRN 会为它们分配相似的 MoUs,使得它们共享特征。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









