







代码:https://github.com/Scofield666/MBSSL
论文:https://arxiv.org/pdf/2305.18238.pdf
在论文阅读中我会根据自己以往的阅读经历和自己的一些工作进行总结(才疏学浅)~ 至于为什么要写这个论文阅读文章,也是因为总结学到的东西,总好过匆匆看完一篇论文。在此之后我会不定期更新关于推荐的各大顶会论文的阅读笔记(更多是多行为推荐)。
这篇论文的代码阅读也写完了,可以搭配一起看,地址:
代码阅读:SIGIR 2023 Multi-behavior Self-supervised Learning for Recommendation_推荐系统YYDS的博客-CSDN博客
1 摘要
现代推荐系统通常处理各种用户交互,例如点击、转发、购买等。这要求底层推荐引擎充分理解和利用来自用户的多行为数据。尽管最近人们努力利用异构数据,多行为推荐仍然面临巨大的挑战。首先,稀疏的目标信号和嘈杂的辅助交互仍然是一个问题。其次,现有的利用自监督学习(SSL)解决数据稀疏问题的方法忽略了SSL任务和目标任务之间严重的优化不平衡。因此,我们提出了一个多行为自监督学习(MBSSL)框架和一个自适应优化方法。具体来说,我们设计了一个行为感知图神经网络,结合了自我注意机制,以捕捉行为的多样性和依赖性。为了提高对目标行为下的数据稀疏性和来自辅助行为的噪声交互的鲁棒性,我们提出了一种新的自监督学习范式,在行为间和行为内两个层次进行节点自鉴别。此外,我们开发了一个定制的优化策略,通过混合操作梯度自适应地平衡自监督学习任务和主监督推荐任务。
2 以往研究存在的问题
2.1 数据稀疏和交互噪声的鲁棒性
尽管辅助行为(浏览,收藏,加购物车)的交互数据可以为目标行为的推荐提供很好的补充信息,但是目标行为下的数据稀疏性仍然是一个问题。CML中提出了一种可能的解决方案,通过在每个辅助行为和目标行为对之间进行对比学习,充分利用来自辅助行为的监督信号。然而,辅助行为可能同时包含对目标任务有害的噪声交互。因此,简单地采用CML中的对比学习范式可能会加剧对辅助行为中噪声分布的负迁移,极大地破坏目标行为的真实语义。在这方面,一种综合和自适应使用交互数据的方法在性能增强中起着至关重要的作用。
2.2 辅助任务和目标任务之间的优化不平衡
现有的多行为推荐解决方案基本上采用多任务学习(MTL)范式来联合优化辅助任务和目标任务。然而,忽略每个任务对优化目标的贡献的估计将遭受严重的优化不平衡问题,其中辅助任务可能支配网络权重,导致目标任务的更差性能。此外,现有的多任务学习方法不适用于将自监督学习(SSL)任务视为辅助任务的情况,因为SSL任务对目标任务具有混淆效应,这取决于SSL的特定设计。因此,多行为推荐中的另一个关键问题是优化方法的精心设计,以缓解辅助任务和目标任务之间的优化不平衡。
3 贡献
1:设计了一个行为感知图神经网络,该网络增强了行为表征学习和自我注意机制,以联合建模行为内部上下文和行为相互依赖。
2:为了处理目标行为下的稀疏监督信号,引入了一种综合的自监督学习范式,分别从行为间和行为内两个层次对比节点。SSL通过选择性地构造负节点对,将信息语义从辅助行为传递到目标行为。为了进一步提高对噪声交互的鲁棒性,行为内SSL合并了目标行为中的自我监督信息,以抵消行为间SSL带来的潜在负迁移。
3:基于SSL任务相对于目标任务表现出任意优化趋势的观察,设计了一种多行为优化方法,该方法混合地调整梯度的方向和幅度,以在优化中平衡SSL任务和目标任务。

4 方法
4.1 问题定义:用户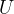 ,项目
,项目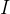 ,行为
,行为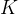
4.2 行为感知图神经网络
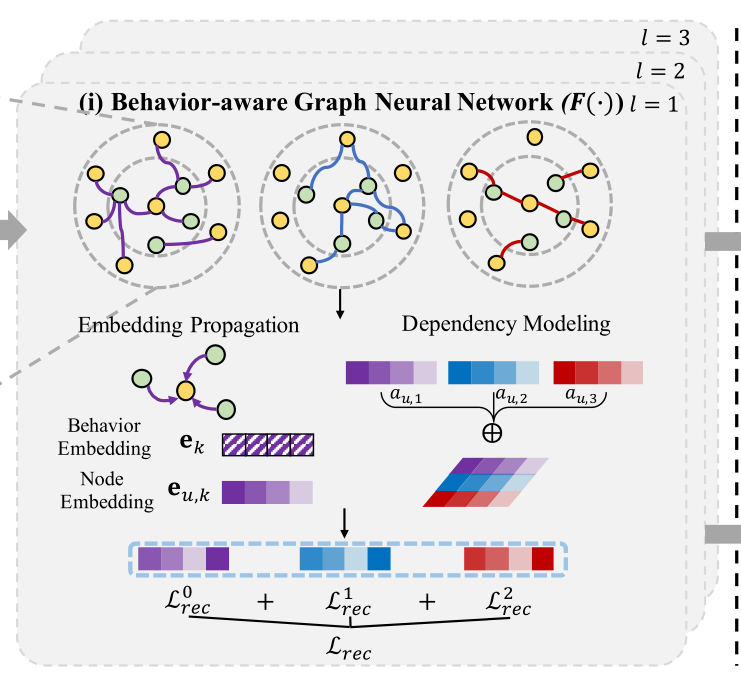
4.2.1特定于行为的嵌入传播
首先根据交互行为类型构建每个特定于行为的用户项目二分图,然后对每个图执行嵌入传播,以获得每个行为下每个节点的表示。为了明确显示每个行为的区别性语义并捕捉上下文化的用户偏好,我们还在节点上编码行为,并将每个行为的表示合并到消息传递范式中:
![]()
很正常的GNN的消息传递范式,用户的嵌入由项目的嵌入和行为的嵌入生成。
4.2.2 跨行为依赖建模
![]()
值得注意的是,这里的行为嵌入不是与传统多行为Rs那样由初始嵌入层生成的,而是通过与参数相乘更新的。鉴于不同的行为会以隐含的方式相互交织,并且行为之间的相关性因用户而异,利用自我注意机制来建模跨行为依赖性。首先将用户的所有行为进行串联,使用ATT来生成权重系数,在使用权重系数与用户嵌入相乘生成最终特定于行为的用户嵌入,并mean pool集成GNN所有层的嵌入,计算如下:
![]()
![]()
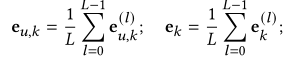
(个人总结)在这里与MBGCN也有所不同,MBGCN生成自适应的多行为权重(使用用户总交互数量以及用户单行为交互数量),并使用行为权重与用户嵌入相乘,而不是使用ATT生成权重。
4.3 多行为自监督学习
如前所述,与辅助行为相比,目标行为的稀疏监督信号可能会导致学习表征的严重偏差。此外,忽视辅助行为带来的嘈杂交互会夸大对某些交互的过度依赖。因此,我们引入了一种新的自监督学习范式,从行为间和行为内两个层面进行自我辨别对比学习
4.3.1 行为间自监督学习
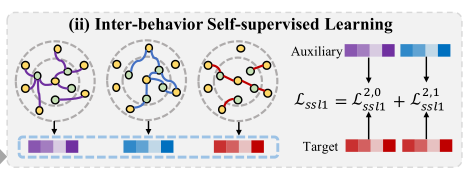
辅助行为中的监督信号比目标行为中的监督信号丰富得多,在辅助行为和目标行为之间进行选择性对比学习以实现知识转移,从而缓解数据稀疏性。每个辅助行为都会与目标行为做对比,以提供不同的语义。以往的做法是将是将同一节点的和不同节点的视图视为正对和负对,但相同的两个主题将具有一些共性(例如,用户共享相似的偏好或者项目具有相似的属性)在这种情况下,按照惯例构建的否定对很可能包括许多假否定(即高度相似的节点),这将丢弃真实的语义信息。因此,用swing算法基于计算的相似性得分来发现潜在关系,并在对比节点对时消除它们。在这里是以往多行为推荐很少用到的,值得学习。在单行为的子图中,用户的相关性得分计算如下:
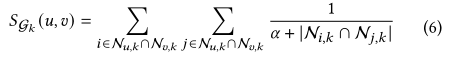
是平滑系数,使用了两个项目的邻居节点来计算。最终的相关性稀疏是每个子图的平均值。行为间对比损失定义如下:

K是目标行为,k是辅助行为,FN(u)是相关性系数,每个对比损失都是由用户和项目的损失相加![]() ,最后生成多行为的对比损失
,最后生成多行为的对比损失![]()
4.3.2 行为内自监督学习
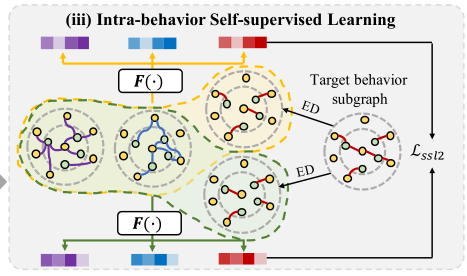
为了缓解不同行为间的数据分布偏差,行为间自监督学习鼓励目标行为和辅助行为下节点表示的相似性。然而,鉴于在辅助行为下更高比例的噪声交互,更多的噪声也将隐含地转移到目标行为中,使得学习到的表征被辅助信号支配,而失去了目标行为下的内在语义。因此,我们设计了一种行为内自我监督学习来生成和对比目标行为子图的结构增强视图,通过这种方式,我们巩固和放大了目标行为本身内监督信号的影响,以抵消向辅助行为中噪声分布的负迁移。具体来说,我们首先通过执行[32]中介绍的边缘丢失,从目标行为子图生成两个扩充视图![]() 。我们将
。我们将![]() 表示为目标行为子图,然后两个扩充视图被阐述为:
表示为目标行为子图,然后两个扩充视图被阐述为:
![]()
其中是控制保留边集的两个随机屏蔽向量。在将两个增强视图分别与辅助行为子图一起编码后,我们获得了增强视图的节点表示
![]() ,然后基于InfoNCE loss 设计了行为内的的损失:
,然后基于InfoNCE loss 设计了行为内的的损失:

正对是同一用户,负对是不同用户。最后将用户和项目的损失相加,得到了行为间的损失。
4.4自适应多行为优化
为了以有效和稳定的方式学习模型参数,我们利用最近提出的建议[6]的非采样目标,该目标已被证明优于传统的贝叶斯个性化排序(BPR)损失。对于特定一批用户b和整个项目集I,行为k下的非抽样推荐损失为:
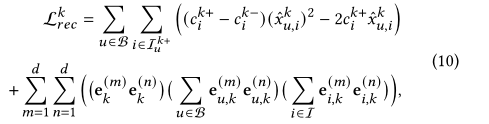
![]() 表示在行为k下,用户u与项目i交互的估计概率,主监督推荐任务的损失就是每种行为下推荐损失的加权和:
表示在行为k下,用户u与项目i交互的估计概率,主监督推荐任务的损失就是每种行为下推荐损失的加权和:
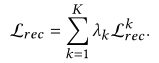
![]()
作为一种解决方案,我们致力于改变辅助梯度G的方向和大小,其包含比目标任务G更大的大小,从而将优化导向目标任务。对于具有较小幅度和冲突方向的辅助梯度,我们保持它们不变以防止过拟合。更具体地说,如果辅助梯度和目标梯度相互冲突,即它们的余弦相似性为负,我们首先通过将辅助梯度投影到目标梯度的法向平面来修改梯度方向。预测策略表述如下:
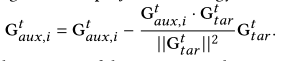
5 总结
作者最后将MBSSL与CML和S-MBRec进行了对比:
与CML对比:CML中的跨行为SSL在每个辅助和目标行为对之间执行,以捕获跨类型的行为依赖。具体来说,SSL范例遵循常规规则,即任何不同用户的视图都将被视为负对。然而,我们可以得出结论,基于丰富的语义和巨大的行为数据量,用户可能会共享相似的偏好,这意味着常见的做法可能会导致许多错误的否定对。因此,在我们的行为间SSL中,我们基于计算的结构节点相似度选择性地构建否定对,以促进辅助行为和目标行为之间的知识转移。
与S-MBRec对比:S-MBRec中的星型SSL通过基于目标行为下的数据寻找相似用户来构造额外的正样本。然而,数据是如此稀疏,以至于计算出的节点相似度是不可靠的。更糟糕的是,在当前鼓励不可靠阳性样本之间比对的SSL范式下,负迁移将被进一步放大。因此,我们的目标是充分利用所有行为下的数据来选择具有高置信度的潜在相似用户,并拒绝增加考虑到对交互噪声鲁棒性的正样本。
所有现有的工作仅仅依靠行为间SSL来处理数据稀疏问题,这是不够的。并且行为间SSL可能会引入来自辅助行为的噪声。作为一种解决方案,我们在目标行为本身中实施行为内SSL,目的是通过放大目标行为的影响来抵消辅助噪声。
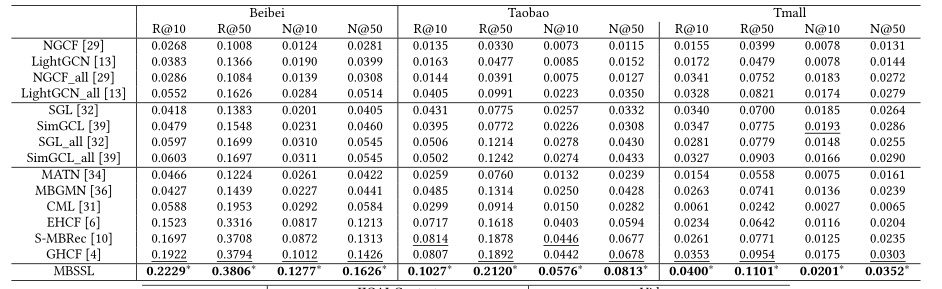
MBSSL首先在GNN聚合阶段,使用ATT加权聚合,同时并没有像大部分使用对比学习的多行为Rs一样将(浏览,收藏,加购物车)生成辅助行为嵌入,而是使用独立的单行为与目标行为一一进行对比学习,同时提出了两种对比学习范式(行为间,行为内)。在多行为推荐最流行的5个数据集中均获得了巨大的提升,在@=10时,比CML效果提升了六倍。。。太牛了。这是我第一次看到在多行为Rs中看到使用Inter和Intra的对比学习,尽管在最后没有太能看懂它基于梯度的混合操作方法,但行为内和行为间的对比学习就已经很值得学习的了。

















 1576
1576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









