







论文来源:SIGIR 2021
论文链接:https://arxiv.org/abs/2109.05261
代码链接:https://github.com/gzy-rgb/CauseRec

动机:
-
噪声问题:来自推荐系统的隐式反馈的噪声问题使得用户点击行为和实际兴趣之间存在不一致。噪声可能来自于标题偏见、位置偏见、销售促销等多种因素,这导致了推荐系统的不稳定和脆弱性 。
-
数据稀疏性
创新:
-
反事实数据建模:通过确定用户偏好中不可或缺和可有可无(噪声)的概念。在项目级和兴趣级用户概念序列上执行反事实替换,将可有可无的概念替换为反事实的用户表示(对比学习正对),通过替换不可缺少的概念为当前批次随机选择的部分从而获得反事实的用户表示(对比学习负对),以应对推荐系统中的数据稀疏性问题。
-
对比学习:通过对观测到的行为序列进行反事实变换,生成反事实的正/负用户序列(正负样本对),通过采样进行用户表征的对比学习,提升用户表征的鲁棒性 ,如下图所示。
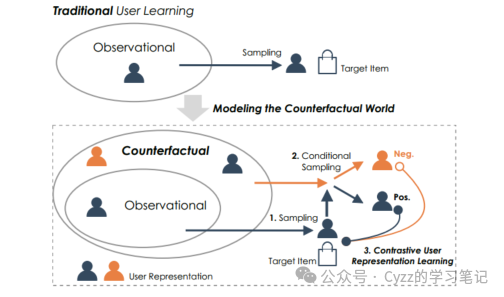

模型部分
2.1基本匹配模型
推荐系统中包含匹配阶段和排序阶段。匹配阶段为每个用户检索出前N个候选物品,而排序阶段则进一步对这N个候选物品进行排序。
在匹配模型中,通常包括用户编码器和物品编码器。用户编码器fθ(x)以用户的历史行为序列为输入,使用均值池化对历史交互项的嵌入进行聚合,然后使用多层感知器将聚合的嵌入转换为与项目嵌入相同的嵌入空间。
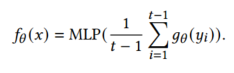
物品编码器gθ(y)应用查找嵌入矩阵将每个物品都被表示为一个向量。用户行为序列
x将被转换为一个向量表示fθ(x),并检索出与之匹配得分最高的前N个物品。匹配得分通过内积计算。学习过程可以表述为以下最大似然估计:
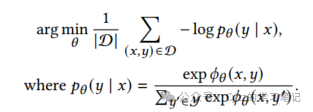
2.2 模型部分
CauseRec的本质是回答回顾问题,“如果我们干预观察到的行为序列,用户表示将是什么?”CauseRec中的反事实转换与对观察到的行为序列的干预有关。为了回答“用户表示将是什么”,引入了一个重要的归纳偏差,使干预工作如预期的那样。具体来说,首先识别历史行为序列中不可或缺/可有可无的概念。一个不可或缺的概念表示一个行为序列的子集,它可以共同表示用户兴趣的一个有意义的方面。可有可无的概念指的是一个嘈杂的子集,它在表示感兴趣的方面方面意义不重要。
通过替换原始用户序列中可有可无的概念构建的反事实序列应该具有与原始用户序列相似的用户偏好。因此,替换原始用户序列中不可缺少的概念会导致从结果用户表示到原始用户表示的偏好偏差。
CauseRec模型如下图所示
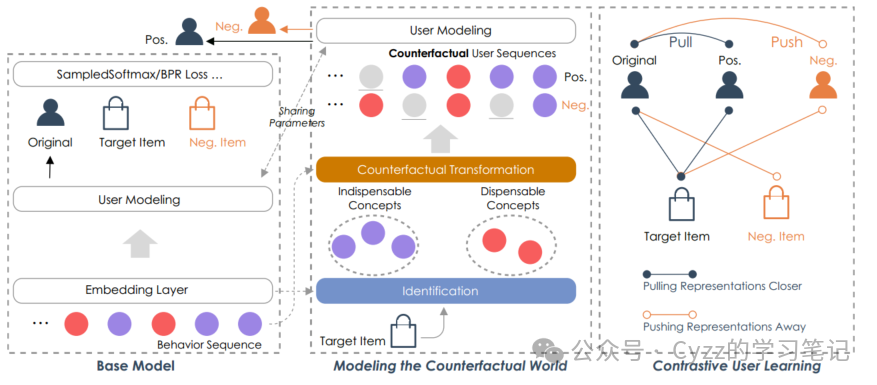
2.2.1概念识别
这一节是对可有可无/不可或缺的概念进行识别,作者将其分为了项目级别和兴趣级别的概念。
项目级别:因为每个项目都有其独特的细粒度特征,因此行为序列中的每个项目视为一个单独的概念:
![]()
概念分数表明这些概念在多大程度上代表了用户的兴趣。由于一个用户的真实兴趣不存在基础真理,定义一个概念分数:
![]()
其中y是目标项目的表征,𝜃为相似度函数
兴趣级别:一些项目可能共享类似的语义,并且可能会降低对项目之间高阶关系建模的能力,因此引入了兴趣级概念,利用注意力机制提取兴趣级概念:
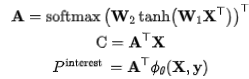
利用注意力机制得到权重,并与原始行为序列的向量表示X加权后得到概念 ,在与目标商品表征进行相似度求解得到兴趣级别的概念分数。对于项目级概念和兴趣级概念,将得分最高的前一半概念视为不可或缺的概念,其余一半概念视为可有可无的概念。这一策略主要是为了防止不可缺少或可有可无的概念数量过少。
2.2.2反事实转换
替换原始用户序列(item序列或interest序列)中一部分概念来构建反事实序列。反事实序列中又分为对比学习中的正对和负对,负对是替换/删除必不可少的概念(因为本质对比学习是在同一嵌入空间中推远样本,因此负对必须基于必不可少的概念),而正对是替换/删除可有可无的概念(正对是在是在同一嵌入空间中拉近样本)
替换的具体步骤
1 根据概念评分公式计算每个概念的分数,识别用户历史行为序列中的可有可无和必不可少概念。
2 根据评分结果,按照一定比例替换这些概念来构建反事实用户序列,使用先进先出队列作为概念存储器,并使用当前小批量中提取的概念作为替换(随机抽样,以确保替换过程的多样性和随机性。)
3 进而生成反事实的正负序列(对比学习的正负样本),正样本为替换可有可无的部分,负样本为必不可少的部分
2.2.3学习目标
反事实和真实序列的对比学习:鲁棒的用户嵌入表示应对可有可无的概念不敏感。因此,从反事实转换了必不可少概念的反事实序列中学习的用户嵌入表示应被推离原始用户嵌入表示。同样,从转换了可有可无概念的反事实序列中学习的用户表示应被拉近原始用户嵌入表示。使用三元组边际损失来衡量样本间的相对相似性:
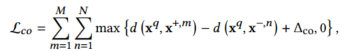
兴趣级别与项目级别之间的对比:为了增强用户嵌入表示的学习,并防止用户编码器为反事实用户序列学习到无效表示。给定目标物品的 L2 归一化表示和用户表示,进行对比学习:
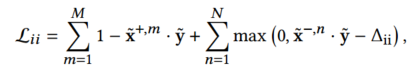
正样本部分确保用户表示与目标物品的内积接近 1(方向尽可能一致,从而拉近它们之间的距离),负样本部分确保用户表示与目标物品的内积尽可能小,使它们之间的距离尽可能远。
最终的损失:经过上述两个损失加权后与主推荐损失相加
![]()

实验部分
3.1数据集
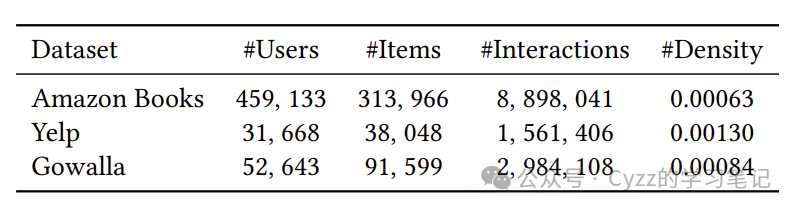
三个数据集都是常用的数据集
3.2性能比较
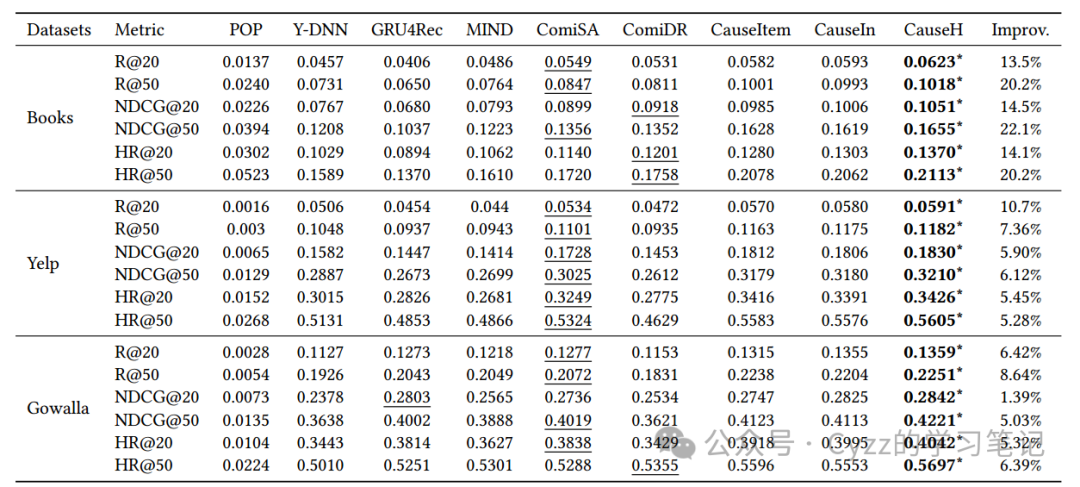
3.3 消融实验
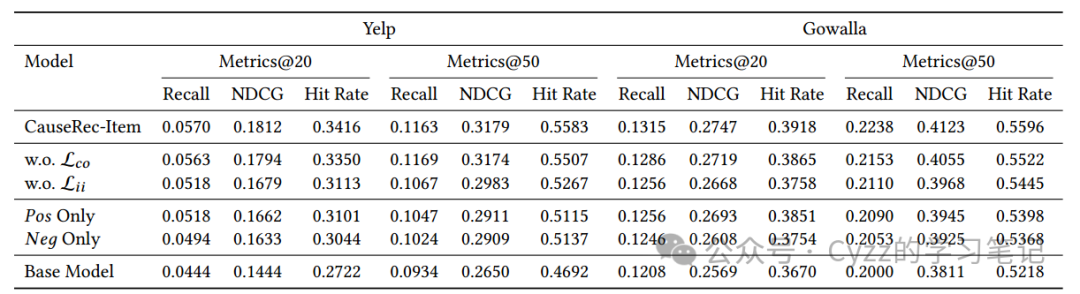
其中分别去除了反事实和真实序列的对比学习和兴趣级别与项目级别之间的对比,以及在可有可无的项目上只有反事实变换和在不可缺少的项上只有反事实变换。

总结
CauseRec 提供了一种通过反事实数据建模和对比学习来增强推荐系统鲁棒性的方法:通过识别可有可无/不可或缺的概念(分为了项目级和兴趣级),并在序列中针对可有可无的概念使用反事实数据进行替换,并设计了两种对比学习策略,解决了噪声和数据稀疏性问题,还显著提升了用户表示的准确性和推荐系统的整体性能。代码阅读正在路上
最后,很长一段时间没有更新内容了,在忙申博的事,现在有时间啦,并且我开始在微信公众号发表一些内容了,感兴趣的各位还请关注我的公众号


















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









