








论文来源:CIKM 2023
论文链接:[2308.04807] Parallel Knowledge Enhancement based Framework for Multi-behavior Recommendation
代码链接:https://github.com/MC-CV/PKEF.
1 动机
现有的多行为推荐框架通常包括融合和预测两个步骤,在融合阶段,使用神经网络建模用户不同行为之间的层次相关性,在预测阶段,利用多任务学习进行联合优化,然而:
1:数据不平衡问题:由于行为数据分布的不均衡(如“浏览”行为的交互量远大于“购买”行为),导致学习到的行为关系偏向高频行为,影响低频行为(如购买)的预测效果,如下图所示:
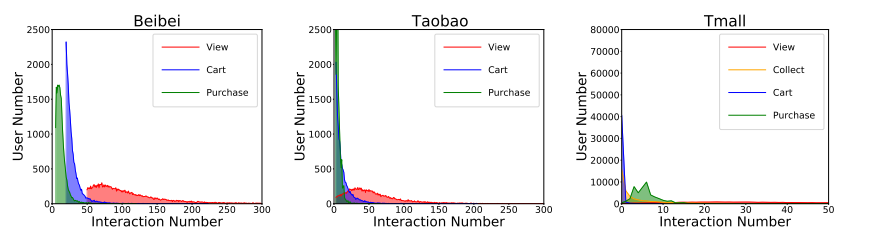
在级联行为建模中,这种不平衡问题进一步加剧。如下图所示,在级联方法中,与下游行为相比,上游行为具有更丰富的交互信息。因此,在行为传播过程中,学习到的关系以上游行为为主,导致模型学习到的关系偏向上游行为,干扰了下游行为预测。
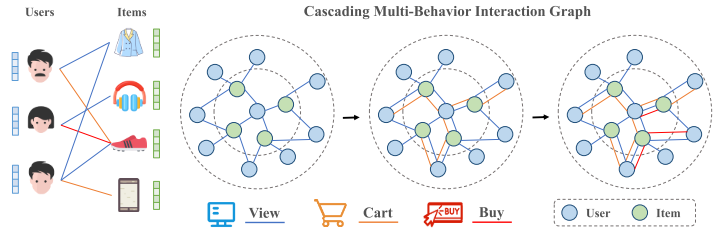
2:负迁移问题:当训练多个任务时,某些任务的性能可能会受到其他任务的负面影响或干扰,导致性能下降。在多任务学习中,尽管耦合输入可以共享来自不同行为的信息,但它们也可能引入潜在的梯度冲突问题。
2 贡献
首次在多行为推荐中系统性研究数据不平衡问题和负迁移问题,并提出 PKEF 框架。PKEF 由 并行知识融合(PKF) 和 投影解耦多专家网络(PME) 组成
1:PKF结合了级联和并行范式,利用并行知识自适应地增强不同行为的表征,同时学习分层关联信息来纠正不平衡行为交互造成的信息偏差。
2:PME将不同的行为视为独立的任务,为每个行为生成相应的专家信息,并使用可学习的权重来聚集来自不同行为的专家信息。不同行为的聚合可能会在特定行为任务的学习过程中引入噪声,通过投影机制在专家信息聚合时消除无用信息,减少负迁移问题。先将其他行为的专家信息分解为“共享部分”和“独特部分”,仅使用共享部分进行行为信息的聚合,防止负迁移影响模型学习。
3 多行为推荐中的梯度冲突问题
3.2.1 梯度冲突
现有的 MTL 方法通常采用耦合输入,即将不同行为的表示直接加权求和:
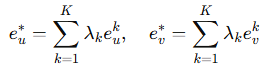
K 表示行为数量,这样的耦合表示作为输入,会导致梯度冲突,所有行为的梯度更新方向可能相互干扰,影响模型学习。MTL 优化目标是最小化所有行为的损失函数:
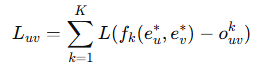
对输入求梯度,梯度的求和意味着所有行为的梯度都会作用在同一个向量
上,导致梯度冲突问题。
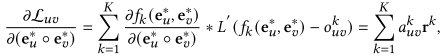
3.2.2 投影解耦专家网络
基于投影的解耦策略为每种行为单独生成专家信息,而不是所有行为共享同一个特征表示:
![]()
是第k种行为的用户-物品交互表示,
是行为 k 的专家门控的权重,由一个全连接层FC计算。此外,在聚合来自不同专家的信息的同时,门控机制同时引入来自其他专家的负面信息。因此,需要从其他专家那里提取对行为𝑘预测有用的信息。
![]()
是行为 k′对行为 k贡献的共享信息部分,
是投影系数,控制了行为 k′ 对行为 k的影响强度,避免了梯度冲突:
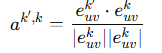 ,使用投影机制后,每种行为的梯度仅影响自己:
,使用投影机制后,每种行为的梯度仅影响自己:
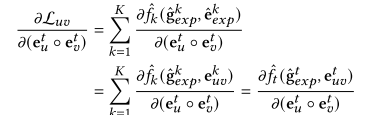
每个行为的梯度更新仅针对自身输入 ,不受其他行为梯度的干扰,避免了负迁移问题。
4 模型
多行为推荐框架(PKEF)由两部分组成:(1)并行知识融合(PKF);(2)投影解缠多专家网络(PME)。
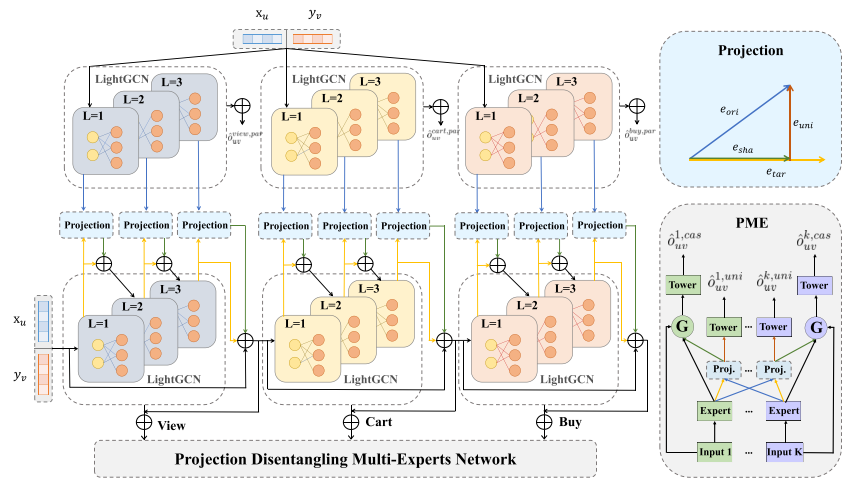
4.1 嵌入层
将用户和物品 ID 映射到低维向量空间,采用Embedding Lookup从嵌入矩阵中查找用户和物品的向量表示:
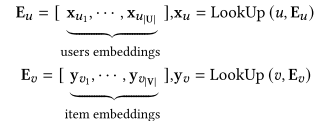
4.2 并行知识融合
在多行为推荐中,用户的交互数据通常遵循级联行为模式,浏览(View) → 加购物车(Cart) → 购买(Buy),但是由于数据高度不平衡(例如“浏览”远远多于“购买”),模型可能会过度依赖高频行为(如浏览)并影响低频行为(如购买)的预测。并行知识融合将级联+ 并行相结合,通过并行学习增强不同行为的表征,避免某个行为(特别是高频行为)主导其他行为的学习。
4.2.1 级联相关学习
级联相关学习来捕捉行为之间的层次依赖关系,将多个行为 k的交互矩阵转换成邻接矩阵
![]()
在每个行为𝑘中,应用消息传递来捕获高阶交互信息。利用LightGCN作为GCN聚合器来聚合每一层𝑙上的信息: ![]() ,并采用级联范式来学习不同行为的层次关联信息:
,并采用级联范式来学习不同行为的层次关联信息:![]() ,其中,应用残差连接来组合上游行为表示的第一层和最后一层,作为下游行为的输入。
,其中,应用残差连接来组合上游行为表示的第一层和最后一层,作为下游行为的输入。
4.2.2 并行交互增强
并行学习独立建模每个行为的表示,在每一层单独计算行为的表示,再通过投影机制进行融合,还是使用LightGCN作为GCN聚合器来聚合每一层𝑙上的信息![]() ,提出了两种方式来融合级联和 并行信息。
,提出了两种方式来融合级联和 并行信息。
投影增强知识融合:在每一层上,将并行表示投影到级联表示上,计算并行和级联表示的投影,得到,然后加到级联表示上。
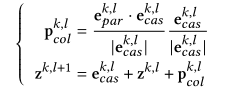
分别是并行流和级联流的表示。
Vanilla 知识融合:先计算行为权重,再结合多个信息(级联表示、并行表示、差值、逐元素乘积)进行加权融合
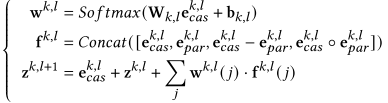
最终,每个行为的表示作为后续预测模型(PME)的输入,计算如下:
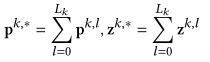
4.3 投影解耦多专家网络
现有 MTL 方法在多个行为间共享特征,但这可能导致梯度冲突和负迁移(不同任务的学习目标相互干扰,降低效果)。投影解耦多专家网络为每个行为独立生成专家信息,并在聚合时利用投影机制,消除无关信息,提高预测准确性。
首先为每个行为单独生成专家信息:![]() ,在传统MTL 方法中,这些专家信息会被直接加权聚合,为了缓解来自其他特定行为专家的负面信息传递,改进了门控机制,引入了表征投影机制。以行为𝑘为例:
,在传统MTL 方法中,这些专家信息会被直接加权聚合,为了缓解来自其他特定行为专家的负面信息传递,改进了门控机制,引入了表征投影机制。以行为𝑘为例:
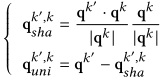
采用门控机制选择性地聚合专家信息:
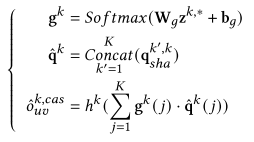
gk是行为 k的门控权重,控制不同行为的专家信息对当前行为的影响。然后使用投影分解后的共享信息进行专家信息聚合,最后,计算目标行为的预测分数。
4.4 联合优化
并行损失:优化并行流部分,使得每个行为的并行表示能够有效建模用户的兴趣:
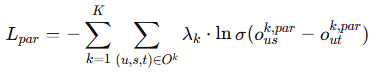
级联损失:优化级联部分,使得行为层次关系(如 浏览 → 购物车 → 购买)能够更好地被学习:
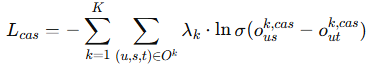
独特损失:优化去除无关信息后的独特信息表示,确保去掉的信息仍然能用于其他行为的学习:
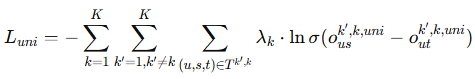
![]()
5 实验部分
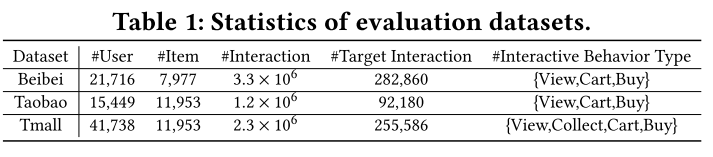
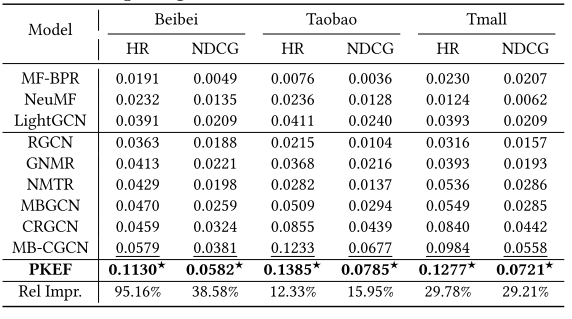
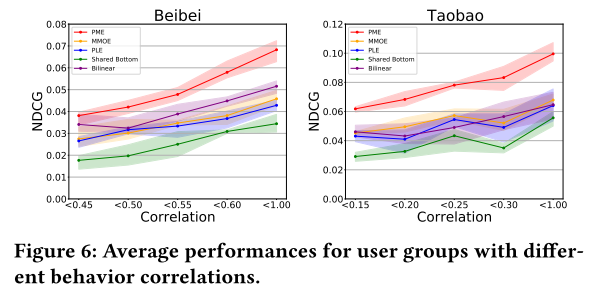
不同行为关联下的案例研究:通过实验验证了模型是否能够缓解潜在的梯度冲突。根据所有行为之间的平均皮尔逊相关性将测试用户分为五个用户组,并从每个用户组中选择子集。在贝贝和淘宝数据集上的实验结果如下图所示。在所有用户组中,PME的性能一致优于所有其他MTL方法,进一步证明了PME在MTL上的优越性。此外,随着皮尔逊相关性的增加,PME的性能比其他MTL方法增长得更快,而其他MTL方法甚至出现了波动和下降。一个可能的原因是当知识在不同的任务之间转移时,潜在的梯度冲突导致了负迁移。

















 8344
8344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









