







12月12日,由深度学习技术及应用国家工程实验室主办的WAVE SUMMIT+2021深度学习开发者峰会在上海召开。百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰公布飞桨最新成绩单:凝聚406万开发者、创建47.6万模型、服务15.7万企事业单位,中国深度学习平台综合市场份额第一。飞桨十大新发布引领AI技术和生态发展。
王海峰表示,飞桨秉承技术创新、开源开放的初心,坚定不移地在核心技术的积累和突破上下功夫,同时扎实稳健地推进生态建设,与广大开发者、产学研用各方共同探索和成长,赋能产业转型升级。
“深度学习推动人工智能进入工业大生产阶段。面向技术和产业发展需求的AI大生产平台可以让AI技术以标准化、自动化和模块化的方式输出给千行百业,实现规模化应用,同时以平台为基础促进融合创新、共同发展。飞桨产业级深度学习开源开放平台是典型的AI大生产平台,赋能广大开发者,有力支撑AI工业大生产,促进技术创新和产业智能化升级。”王海峰认为。

峰会上,飞桨发布十大最新技术和生态进展,包括飞桨新版全景图—产业级模型库新增文心大模型、业界首个产业实践范例库、飞桨“大航海”2.0共创计划、飞桨开源框架v2.2 体系化新增科学计算API、端到端自适应大规模分布式训练技术、文本任务全流程加速、多层次低成本的硬件适配方案、产业级开源模型库模型超过400个、企业版升级自动高效的模型部署功能,以及1分钟极速安装完成本地高效建模的飞桨EasyDL桌面版。

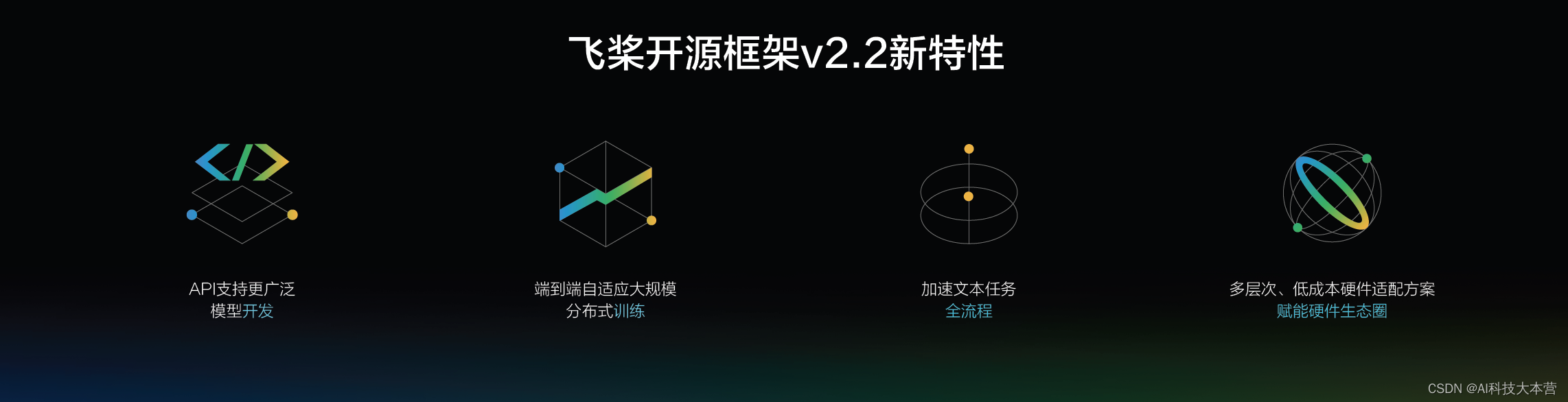
具体来说,技术层面,飞桨全新发布的开源框架v2.2,深度学习框架技术持续领先,具备四大特性:飞桨API更加丰富、高效、兼容,新增大量科学计算API;高效支持超大模型训练的端到端自适应大规模分布式训练技术;全流程加速文本任务,解决文本领域开发在性能和训推一体方面的痛点问题;多层次、低成本的硬件适配方案,极致降低框架与芯片的适配成本。飞桨产业级模型库新增百度最新发布的知识增强文心大模型,让大模型真正进入产业应用;官方支持的产业级开源算法模型超过400个,并发布13个PP系列模型,在精度和性能上达到平衡,将推理部署工具链彻底打通。
产业落地方面,飞桨推出业界首个产业实践范例库,从真实产业场景分析、完整代码实现,到详细过程解析,直达项目落地,覆盖数十个高频应用场景,推动AI落地可复制和规模化。面向产业场景提升开发效率和资源使用效能的飞桨企业版升级了自动高效的模型部署功能,同时推出1分钟极速安装完成本地高效建模的飞桨EasyDL桌面版。
生态方面,飞桨更进一步,全新发布“大航海”计划2.0,在启航、护航、领航三大航道基础上,新增“共创”计划,以飞桨平台为基座,社区开发者共创工具、模型、产业案例与实践经验;形成产业创新需求对接平台,共创产学研用正循环;与生态伙伴一起建设人工智能产业赋能中心,共创区域创新生态。

“建设飞桨需要抓住的关键点有三个,技术持续创新、功能体验以开发者的需求为首位,以及广泛地与生态共享、共创。”百度集团副总裁、深度学习技术及应用国家工程实验室副主任吴甜表示。
工作之余自学AI的铁路工人基于飞桨实现了铁路货运车号的自动识别,为所在铁路段节省数十万元成本;吉林大学的师生团队联合飞桨平台,打造了已在生产线上应用的自动化检测系统,并沉淀为教学课程,帮助更多师生学习AI技术和应用……飞桨的持续创新,让深度学习落地产业应用的门槛不断降低,实现共享共创,推动千行百业加速智能化升级。


















 3465
3465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









