










编译 | AI科技大本营
参与 | 孙士洁
编辑 | 明 明
【AI科技大本营按】胶囊网络是什么?胶囊网络怎么能克服卷积神经网络的缺点和不足?机器学习顾问AurélienGéron发表了自己的看法。营长将文章内容翻译如下。
胶囊网络(Capsule networks, CapsNets)是一种热门的新型神经网络架构,它可能会对深度学习特别是计算机视觉领域产生深远的影响。等一下,难道计算机视觉问题还没有被很好地解决吗?卷积神经网络(Convolutional neural networks, CNNs)已在分类、定位、物体检测、语义分割或实例分割等各种计算机视觉任务中达到了超人类水平,难道我们所有人没有注意到这些难以置信的例子吗?(见图1)
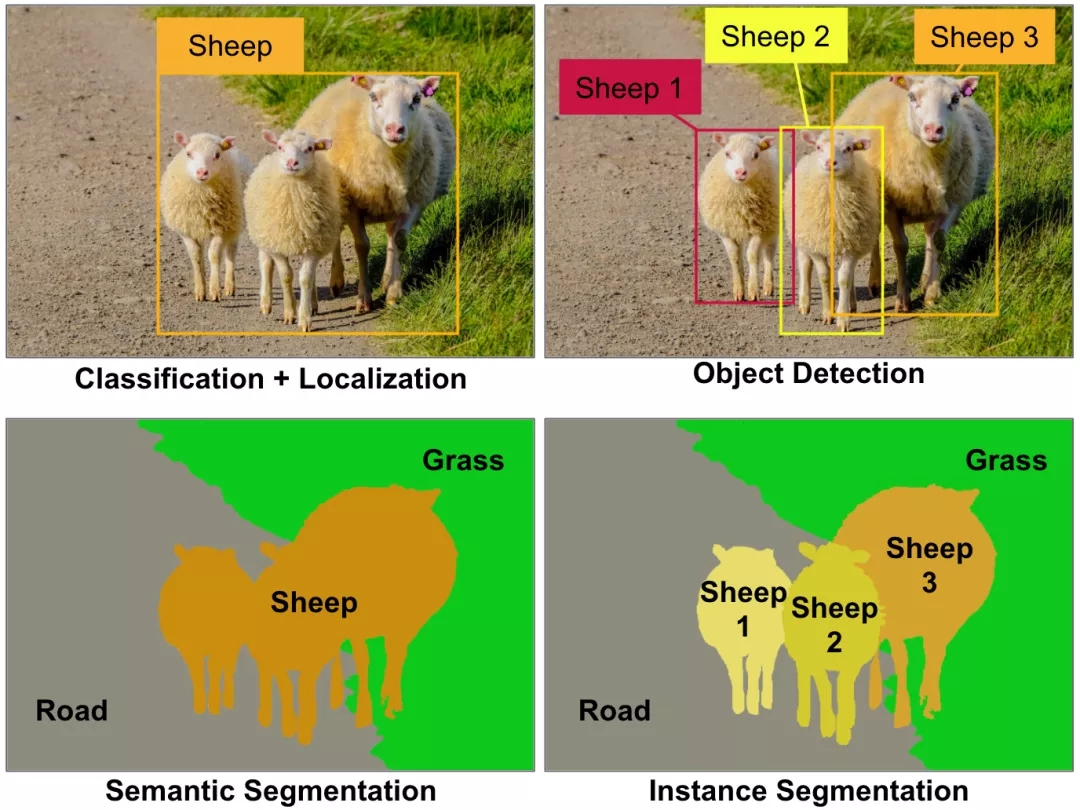
图1 一些主要的计算机视觉任务。现今,这些计算机视觉任务都需要不同的卷积神经网络架构,如用于分类的ResNet架构,用于目标检测的YOLO架构,用于语义分析的掩模R-CNN架构,等等。图像由AurélienGéron提供。
是的,我们已经看到了令人难以置信的CNNs,但是:
这些CNNs都接受了数量巨大图像的训练(或重复使用了部分已训练过的神经网络)。CapsNets能通过少得多的训练数据就可很好地完成网络训练。
CNNs不能很好地处理图像多义性表达。而胶囊网络可以很好处理这一问题,即使在拥挤的场景下也表现出色(尽管CapsNets现在仍与背景纠缠在一起)。
CNNs在池化层丢失大量信息。这些池化层降低了图像空间分辨率(见图2),为此,它们的输出对输入端的微小变化是保持不变的。当整个网络中细节信息必须被保留时,这就是一个问题,如在语义分割中。目前,解决这个问题主要是通过在CNNs周围构建复杂结构来恢复一些丢失的信息。运用CapsNets,详细的姿态信息(如精确的目标位置、旋转、厚度、歪斜、大小等等)在整个网络中都被保留,而不是丢失而后被恢复过来。输入的微小变化会导致输出的细微变化——信息却被保留。这就是所谓的“同变性(equivariance)”。所以,CapsNets对于不同的视觉任务可以使用相同的简单且一致的架构。
最后,CNNs需要额外的组件来实现自动识别一个部件归属于哪一个对象(如,这条腿属于这只羊)。而CapsNets则免费提供部件的层次结构。
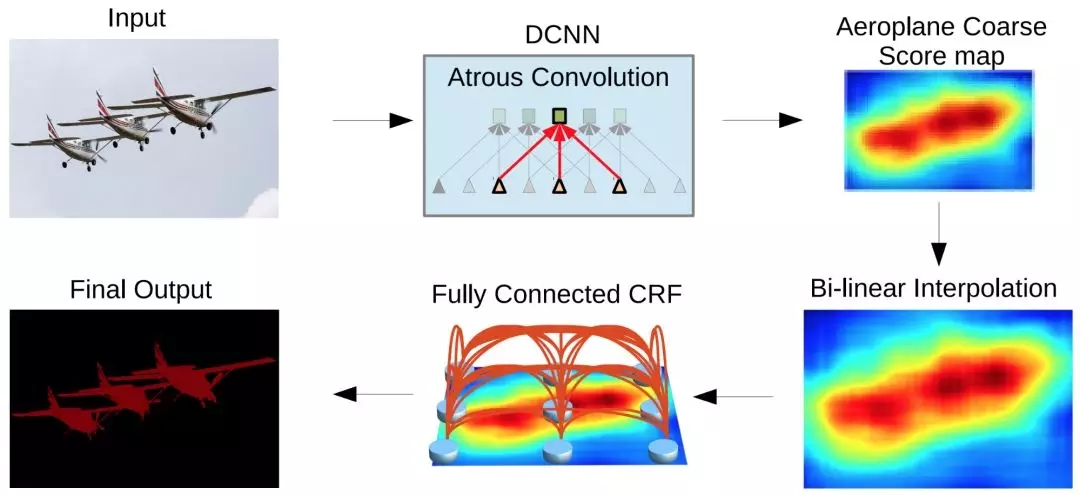
图2 DeepLab2图像分割流程,由Liang-Chieh Chen等提供:可以看到,CNN(右上)的输出结果是十分粗糙的,这使得通过增加额外步骤来恢复丢失的细节很有必要。该图来自Deeplab论文《Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution,and Fully Connected CRFs》,引用得到作者许可。想了解语义分割体系结构的多样性和复杂性可以看S. Chilamkurthy所做的这篇好文章。
CapsNets是由Geoffrey Hinton等人于2011年在一篇名为“转换自动编码器(Transforming Autoencoders)”论文中首次提出的。但仅在几个月前,也就是2017年11月,Sara Sabour, Nicholas Frosst和Geoffrey Hinton发表了一篇名为“胶囊间动态路由(Dynamic Routing between Capsules)”的论文,介绍了一个CapsNets结构,在MNIST(手写数字图像的著名数据集)上达到了最好性能,并在MultiMNIST(不同数字对重叠形成的变形手写数字图像数据集)上获得了比CNNs好得多的结果,见图3。

图3 MultiMNIST 图像(白色) 和CapsNets重构图像 (红色+绿色)。“R”代表重构 ,“L”代表标签. 如:这一个例子预测(左上)是正确的,重构图像也是正确的。但第5个例子预测是错的,(5,0)预测成了(5,7)。因此,5被正确重构,而0却没有。图形来自论文《Dynamic routing between capsules》, 引用得到作者许可。
尽管CapsNets具有很多有点,但它仍远不够完美。首先,现在CapsNets在如CIFAR10或ImageNet大规模图像测试集上的表现不如CNNs好。而且,CapsNets需要大量计算,不能检测出相互靠近的同类型的两个对象(这被称为“拥挤问题”,且已被证明人类也存在这个问题)。但CapsNets的主要思想还是非常有前途的,似乎只需要一些调整就可以发挥全部潜力。毕竟,现在的CNNs是在1998年发明的,经过一些调整后,就在2012年在ImageNet数据集上战胜了最新技术。
▌那么,CapsNets到底是什么?
简而言之,CapsNet由胶囊而不是神经元组成。胶囊是用于学习检测给定图像区域内特定对象(如矩形)的一小组神经元,它输出一个向量(如一个8维矢量),该向量的长度表示被检测对象存在的估计概率,而方向(如在8维空间中)对被检测对象的姿态参数(如精确的位置,旋转等)进行编码。如果被检测对象发生稍微改变(如移动、旋转、调整大小等),则胶囊将输出相同长度的矢量,但方向稍有不同。这样,胶囊是等变的。
就像常规的神经网络一样,一个CapsNet也是按多个层组织的(见图4)。最下层的胶囊被称为主胶囊:每个胶囊都接收图像的一个小区域作为输入(称其为接受场),尝试检测一个特定模式的存在和姿态,如矩形。更高层的胶囊称为路由胶囊,检测更大更复杂的对象,如船只。
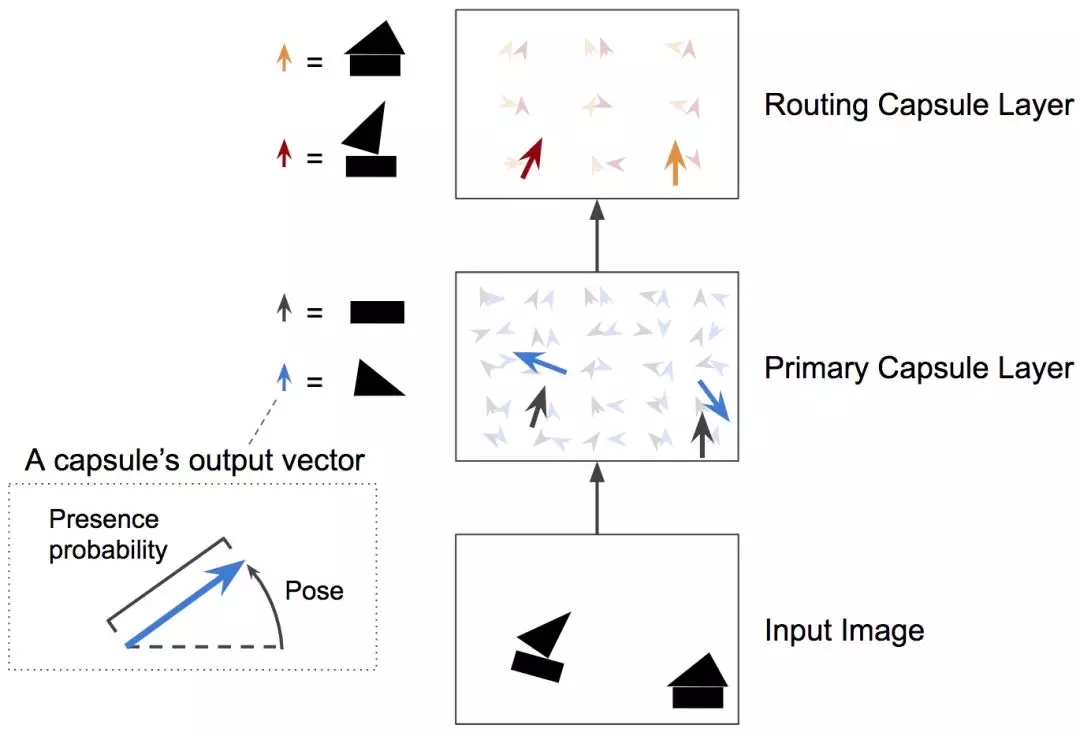
图4 两层胶囊网络。这个例子中,初始胶囊层有两个5×5映射,而第二个胶囊层有两个3×3映射。每个胶囊输出一个向量,每个箭头符号表示一个不同胶囊的输出,蓝色箭头符号表示一个尝试检测三角形的胶囊的输出,黑色箭头符号表示一个尝试检测矩形的胶囊的输出。图像由AurélienGéron提供。
主胶囊层采用几个常规的卷基层来实现。如本文使用两个卷基层输出256个包含标量的6×6特征映射,并将这个输出转变成32个包含8维矢量的6×6映射。最后,使用一个新颖的压缩函数来确保这些向量的长度在0到1之间(表示一个概率)。这样就给出了主胶囊的输出。
下几层胶囊也尝试检测对象及其姿态,但工作方式非常不同,即使用按协议路由算法。这就是胶囊网络的最大魔力所在。我们来看一个例子。
假设只有两个主胶囊:一个长方形胶囊和一个三角胶囊,假设它们都检测到正在寻找的东西。矩形和三角形都可能是房子或船的一部分(见图5)。由于长方形的姿态是略微向右旋转的,房子和船也得是稍微向右旋转。考虑到三角形的姿态,房子就得几乎是颠倒的,而船会稍微向右旋转。注意,形状和整体/部分关系都是在训练期间学习的。现在注意长方形和三角形对船的姿态达成一致,而对房子的姿态强烈不一致。所以,矩形和三角形很可能是同一条船的一部分,并没有房子的存在。
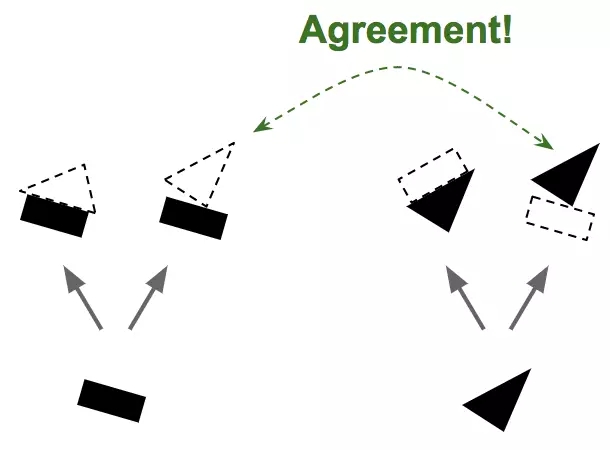
图5 按协议路由,第1步—基于存在的部分对象及其姿态去预测对象及其姿态,而后在预测结果之间寻求一致性。图像由AurélienGéron提供。
既然现在确信长方形和三角形是船的一部分,那么将长方形和三角形胶囊的输出结果更多地发送给船胶囊,而更少发送给房子胶囊,将更有意义:这样,船胶囊将接收更有用的输入信号,而房子胶囊将会收到较少的噪声。对于每个连接而言,按协议路由算法包含一个路由权重(见图6):达成一致时,增大路由权重;出现分歧时,减少路由权重。
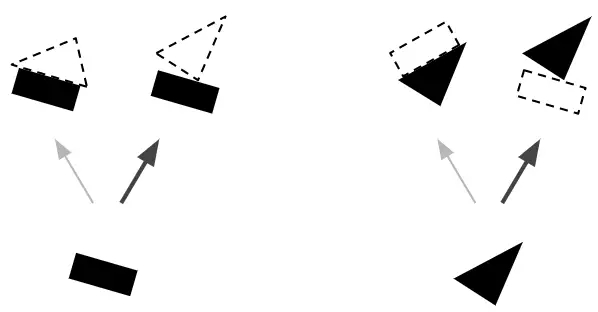
图6 按协议路由,第2步—更新路由权重。图像由AurélienGéron提供。
按协议路由算法包括协议检测+路由更新的一些迭代(注意,每次预测这都会发生,不只是一次且也不仅是在训练时间)。这在拥挤的场景中特别有用:如图7中,场景是存在歧义的,因为你从中间看到的可能是倒置的房子,但是这会使底部的矩形和顶部的三角形无法解释。协议算法很可能会给出更好的解释:底部是一只船,顶部是一个房子。这种模棱两可的说法被认为是“可解释过去的”:下面的矩形最好用船的存在来解释,这也解释了下面的三角形,一旦这两个部分被解释清楚,剩下的部分就很容易被解释为一个房子。
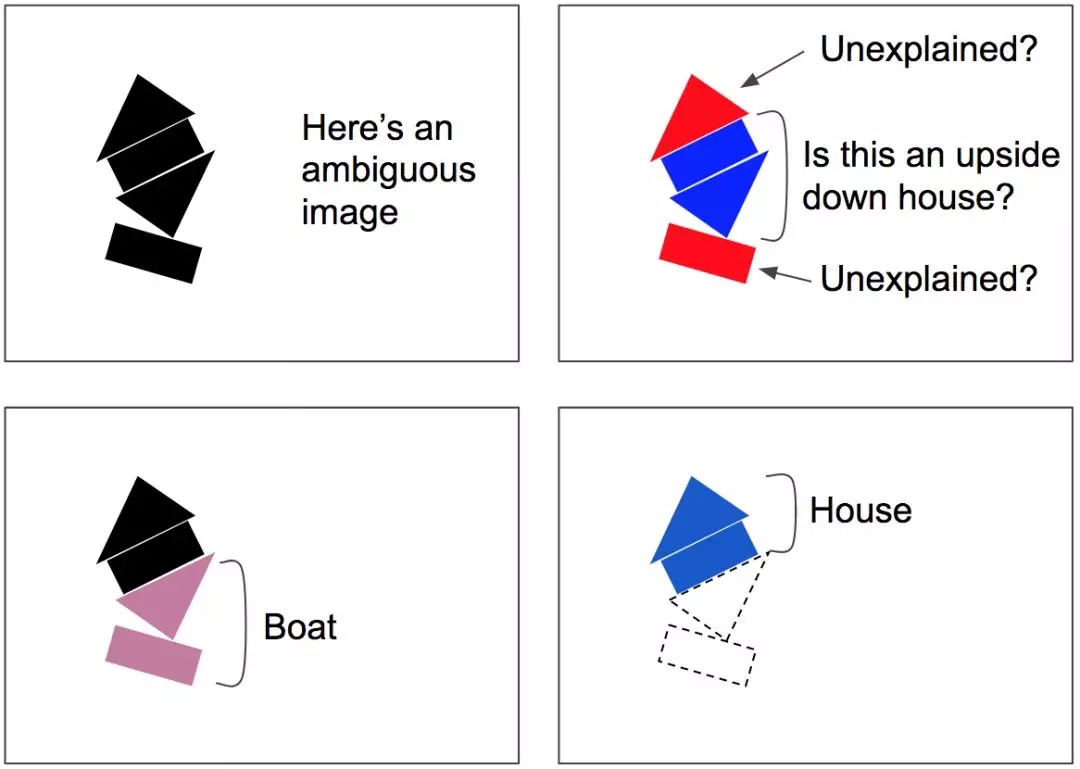
图7按协议路由能解析拥挤场景,如可被误解为颠倒的房子而其他部分无法解释的存在歧义的图像。但底部矩形路由给船,同时底部三角形将也路由给船。一旦船被解释清楚,那么很容易将顶部解释为房子。图像由AurélienGéron提供。
作者| AurélienGéron
原文链接


















 3461
3461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









