







翻译 | 张建军
编辑 | 阿司匹林
出品 | AI科技大本营
【AI科技大本营导读】机器学习中的所有算法都依赖于最小化或最大化某一个函数,我们称之为“目标函数”。最小化的这组函数被称为“损失函数”。损失函数是衡量预测模型预测期望结果表现的指标。寻找函数最小值的最常用方法是“梯度下降”。把损失函数想象成起伏的山脉,梯度下降就像从山顶滑下,目的是到达山脉的最低点。
没有一个损失函数可以适用于所有类型的数据。损失函数的选择取决于许多因素,包括是否有离群点,机器学习算法的选择,运行梯度下降的时间效率,是否易于找到函数的导数,以及预测结果的置信度。这个博客的目的是帮助你了解不同的损失函数。
损失函数可以大致分为两类:分类损失(Classification Loss)和回归损失(Regression Loss)。下面这篇博文,就将重点介绍5种回归损失。

回归函数预测实数值,分类函数预测标签
▌回归损失
1、均方误差,二次损失,L2损失(Mean Square Error, Quadratic Loss, L2 Loss)
均方误差(MSE)是最常用的回归损失函数。MSE是目标变量与预测值之间距离平方之和。

下面是一个MSE函数的图,其中真实目标值为100,预测值在-10,000至10,000之间。预测值(X轴)= 100时,MSE损失(Y轴)达到其最小值。损失范围为0至∞。
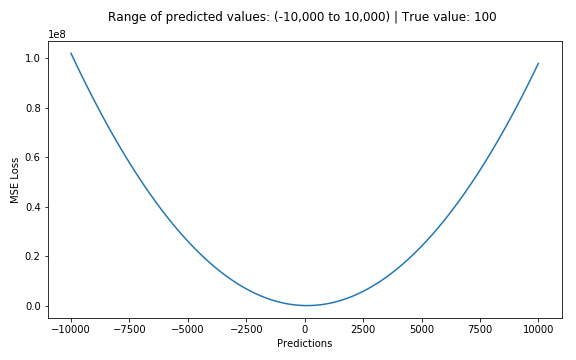
MSE损失(Y轴)与预测值(X轴)关系图
2、平均绝对误差,L1损失(Mean Absolute Error, L1 Loss)
平均绝对误差(MAE)是另一种用于回归模型的损失函数。MAE是目标变量和预测变量之间差异绝对值之和。因此,它在一组预测中衡量误差的平均大小,而不考虑误差的方向。(如果我们也考虑方向,那将被称为平均偏差(Mean Bias Error, MBE),它是残差或误差之和)。损失范围也是0到∞。


MAE损失(Y轴)与预测值(X轴)关系图
3、MSE vs MAE (L2损失 vs L1损失)
简而言之, 使用平方误差更容易求解,但使用绝对误差对离群点更加鲁棒。但是,知其然更要知其所以然!
每当我们训练机器学习模型时,我们的目标就是找到最小化损失函数的点。当然,当预测值正好等于真实值时,这两个损失函数都达到最小值。
下面让我们快速过一遍两个损失函数的Python代码。我们可以编写自己的函数或使用sklearn的内置度量函数:
#true:真正的目标变量数组
#pred:预测数组
def mse(true, pred):
return np.sum(((true – pred)**2))
def mae(true, pred):
return np.sum(np.abs(true – pred))
#也可以在sklearn中使用
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
让我们来看看两个例子的MAE值和RMSE值(RMSE,Root Mean Square Error,均方根误差,它只是MSE的平方根,使其与MAE的数值范围相同)。在第一个例子中,预测值接近真实值,观测值之间误差的方差较小。第二个例子中,有一个异常观测值,误差很高。

左:误差彼此接近 右:有一个误差和其他误差相差很远
我们从中观察到什么?我们该如何选择使用哪种损失函数?
由于MSE对误差(e)进行平方操作(y - y_predicted = e),如果e> 1,误差的值会增加很多。如果我们的数据中有一个离群点,e的值将会很高,将会远远大于|e|。这将使得和以MAE为损失的模型相比,以MSE为损失的模型会赋予更高的权重给离群点。在上面的第二个例子中,以RMSE为损失的模型将被调整以最小化这个离群数据点,但是却是以牺牲其他正常数据点的预测效果为代价,这最终会降低模型的整体性能。
MAE损失适用于训练数据被离群点损坏的时候(即,在训练数据而非测试数据中,我们错误地获得了不切实际的过大正值或负值)。
直观来说,我们可以像这样考虑:对所有的观测数据,如果我们只给一个预测结果来最小化MSE,那么该预测值应该是所有目标值的均值。但是如果我们试图最小化MAE,那么这个预测就是所有目标值的中位数。我们知道中位数对于离群点比平均值更鲁棒,这使得MAE比MSE更加鲁棒。
使用MAE损失(特别是对于神经网络)的一个大问题是它的梯度始终是相同的,这意味着即使对于小的损失值,其梯度也是大的。这对模型的学习可不好。为了解决这个问题,我们可以使用随着接近最小值而减小的动态学习率。MSE在这种情况下的表现很好,即使采用固定的学习率也会收敛。MSE损失的梯度在损失值较高时会比较大,随着损失接近0时而下降,从而使其在训练结束时更加精确(参见下图)。

决定使用哪种损失函数?
如果离群点是会影响业务、而且是应该被检测到的异常值,那么我们应该使用MSE。另一方面,如果我们认为离群点仅仅代表数据损坏,那么我们应该选择MAE作为损失。
我建议阅读下面这篇文章,其中有一项很好的研究,比较了在存在和不存在离群点的情况下使用L1损失和L2损失的回归模型的性能。请记住,L1和L2损失分别是MAE和MSE的另一个名称而已。
地址:
http://rishy.github.io/ml/2015/07/28/l1-vs-l2-loss/
L1损失对异常值更加稳健,但其导数并不连续,因此求解效率很低。L2损失对异常值敏感,但给出了更稳定的闭式解(closed form solution)(通过将其导数设置为0)
两种损失函数的问题:可能会出现这样的情况,即任何一种损失函数都不能给出理想的预测。例如,如果我们数据中90%的观测数据的真实目标值是150,其余10%的真实目标值在0-30之间。那么,一个以MAE为损失的模型可能对所有观测数据都预测为150,而忽略10%的离群情况,因为它会尝试去接近中值。同样地,以MSE为损失的模型会给出许多范围在0到30的预测,因为它被离群点弄糊涂了。这两种结果在许多业务中都是不可取的。
在这种情况下怎么做?一个简单的解决办法是转换目标变量。另一种方法是尝试不同的损失函数。这是我们的第三个损失函数——Huber Loss——被提出的动机。
3、Huber Loss,平滑的平均绝对误差
Huber Loss对数据离群点的敏感度低于平方误差损失。它在0处也可导。基本上它是绝对误差,当误差很小时,误差是二次形式的。误差何时需要变成二次形式取决于一个超参数,(delta),该超参数可以进行微调。当















 5268
5268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









