






Copula二维最全代码,包括边缘分布的拟合寻优,联合分布的拟合寻优及蒙特卡洛数据模拟代码
案例包括4部分:
1-变量x1的边缘部分拟合,提供了正态分布、对数正态分布、伽马分布、威布尔分布、指数分布、瑞利分布等6种常见边缘分布(仅支持正数),6种分布的ks检验及寻优确定x1的最优边缘分布
2-变量x2的边缘部分拟合,其他同1
3-copula的拟合寻优,具体包括Gaussian、t、Frank、Gumbel、Clayton等5种常用copula函数,计算内容包括偏度、峰度,copula参数的拟合,5种copula的上下尾部相关系数,5种copula的AIC和BIC值,Kendall秩相关系数和Spearman秩相关系数,Copula的密度函数和分布函数图,根据平方欧氏距离求取最优copula
4-根据前3步得到的结果,进行蒙特卡洛模拟及等概率转换得到实际尺度下的数据结果
matlab代码,笔者根据大量顾客的各种需求总结而成,备注非常详细,根据自己需要修改案例数据即可
温馨提示:此单为最全2维copula代码,代码可以正常运行


Copula二维最全代码
随着数据分析和建模技术的不断深入和发展,各种分布和模型的应用越来越广泛,特别是在金融、保险、环境科学、物理学等领域,相关数据的分析和建模已经成为必不可少的工作。作为数据建模的基石之一,Copula函数已经成为了越来越多研究人员的关注点。Copula函数被广泛应用于数据融合、风险管理和模型构建等方面,以其灵活的建模形式和广泛的适用范围,成为了统计分析领域的重要研究内容之一。
本文介绍了一个完整的Copula二维代码,包括了边缘分布的拟合寻优、联合分布的拟合寻优及蒙特卡洛数据模拟等功能。其中,案例包括四个部分:变量x1的边缘部分拟合、变量x2的边缘部分拟合、Copula的拟合寻优和根据前三步得到的结果进行蒙特卡洛模拟及等概率转换得到实际尺度下的数据结果。本文代码基于Matlab编写,笔者根据大量顾客的各种需求总结而成,且使用非常方便,仅需要根据需要修改案例数据即可。
第一部分:变量x1的边缘部分拟合
在本部分中,我们提供了正态分布、对数正态分布、伽马分布、威布尔分布、指数分布、瑞利分布等六种常见边缘分布(仅支持正数),并提供了六种分布的Kolmogorov-Smirnov检验(KS检验),以及利用最小二乘法求取最优边缘分布。具体操作方法如下:
1.在Matlab环境中,打开Copula二维最全代码文件夹,找到CopulaTest1文件,双击打开。
2.修改案例数据:将data_x1变量赋值为需要进行分布拟合的数据集。
3.确定x1的分布类型:将x1_distribution变量赋值为需要拟合的分布类型,例如'lognormal'代表对数正态分布。
4.运行代码:点击MATLAB窗口中的运行按钮,等待代码运行完毕即可得到结果。
本部分的主要目的是对变量x1进行边缘分布的拟合,并确定最优分布类型。
第二部分:变量x2的边缘部分拟合
本部分操作方法和第一部分类似,只需要在CopulaTest2文件中修改相应的变量,即可完成变量x2的边缘部分拟合。
第三部分:Copula的拟合寻优
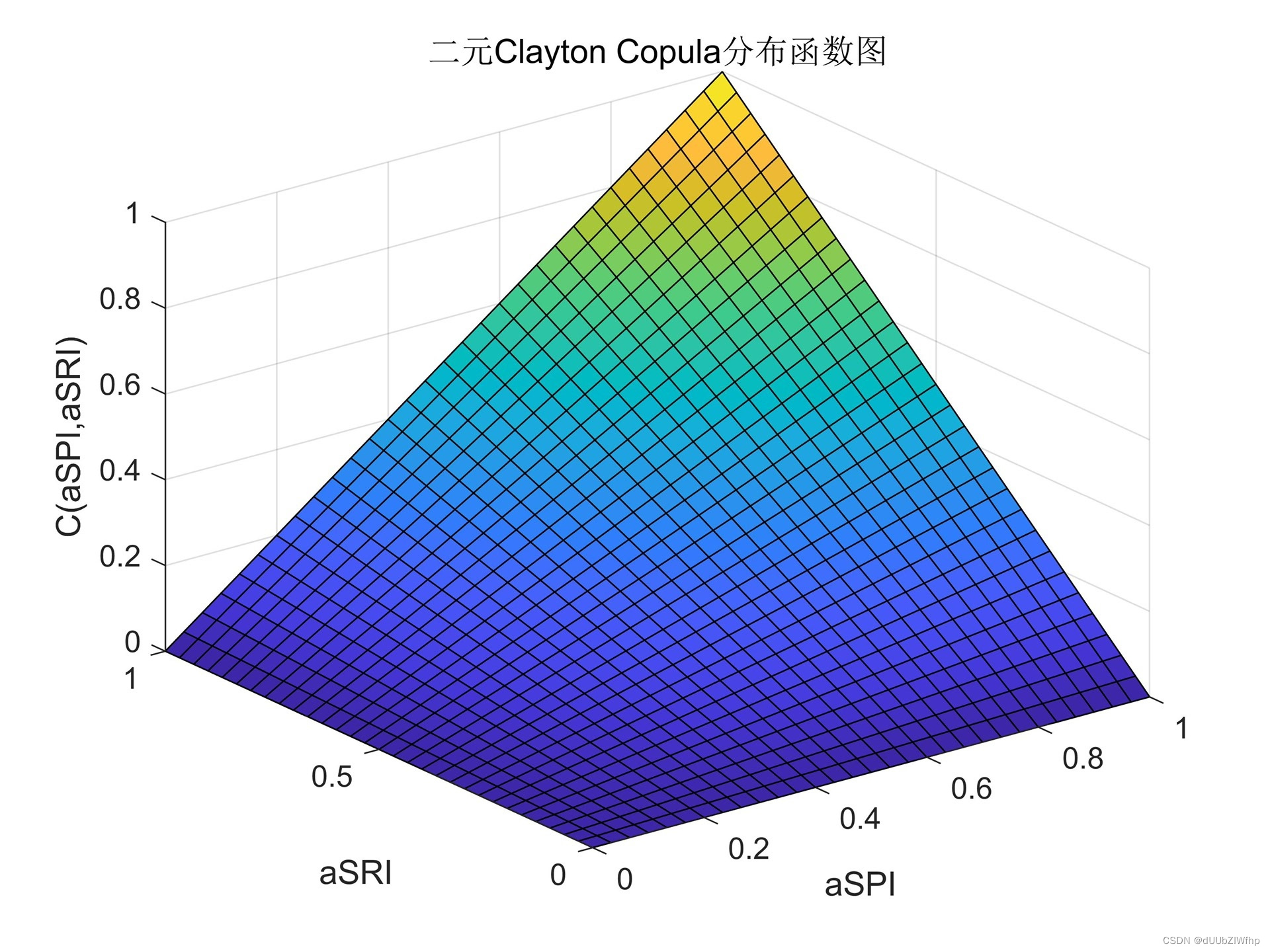
在本部分中,我们提供了Gaussian、t、Frank、Gumbel、Clayton等五种常用Copula函数。通过计算偏度、峰度,Copula参数的拟合以及五种Copula的上下尾部相关系数、AIC和BIC值、Kendall秩相关系数和Spearman秩相关系数、Copula的密度函数和分布函数图,最终求取最优Copula。
具体操作方法如下:
1.在Matlab环境中,找到CopulaTest3文件,双击打开。在文件中修改案例数据:将data_x1变量赋值为第一列数据,将data_x2变量赋值为第二列数据。
2.确定Copula分布类型:将copula_type变量赋值为需要拟合的Copula分布类型,例如'Clayton'代表Clayton Copula。
3.确定Copula参数:将copula_params变量赋值为需要拟合的Copula参数,例如[2]代表Clayton Copula参数为2。
4.运行代码:点击MATLAB窗口中的运行按钮,等待代码运行完毕即可得到结果。
第四部分:根据前三步得到的结果进行蒙特卡洛模拟及等概率转换得到实际尺度下的数据结果
在本部分中,我们基于前三步得到的结果,进行蒙特卡洛模拟及等概率转换得到实际尺度下的数据结果。具体操作方法如下:
1.在Matlab环境中,找到CopulaTest4文件,双击打开。在文件中修改案例数据:将copula_params变量赋值为第三部分中得到的Copula参数。
2.选择随机数种子:将rng_seed变量赋值为随机数种子,例如rng_seed=100。
3.选择需要生成的蒙特卡洛样本量:将nsim变量赋值为需要生成的样本量,例如nsim=1000。
4.确定数据转换的区间:将data_trans_min和data_trans_max变量分别赋值为数据转换区间的最小值和最大值。
5.运行代码:点击MATLAB窗口中的运行按钮,等待代码运行完毕即可得到结果。
总结
本文提供了一个完整的Copula二维代码,实现了边缘分布的拟合寻优、联合分布的拟合寻优及蒙特卡洛数据模拟等功能,对于需要进行Copula建模的数据分析师和研究人员,具有重要的参考价值。同时,在实践过程中,可以根据实际情况修改代码中的数据和参数,以适应各种不同的数据挖掘和分析需求。
相关代码,程序地址:http://lanzouw.top/704867972966.html















 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









