







1.算法整体流程
输入:训练域为: S S S
初始化:模型参数 θ \theta θ,学习率: β , γ \beta,\gamma β,γ
for ite in iterations do
Split: S ˉ \bar{S} Sˉ and S ˇ \check{S} Sˇ → \rightarrow → S S S
Meta-train:
Gradients ∇ θ 1 = F θ ′ ( S ˉ ; θ ) \nabla_{\theta_1}=\mathcal{F^{'}_\theta}(\bar{S};\theta) ∇θ1=Fθ′(Sˉ;θ)
Updated parameters θ ′ = θ − β ∇ θ 1 \theta^{'}=\theta-\beta\nabla_{\theta_1} θ′=θ−β∇θ1
Meta-test:
Loss is G ( S ˇ ; θ ′ ) \mathcal{G}(\check{S};\theta^{'}) G(Sˇ;θ′)
Gradients Update
θ
:
\theta:
θ:
∇
θ
2
=
d
G
(
S
ˇ
;
θ
′
)
d
θ
=
d
G
(
S
ˇ
;
θ
−
β
∇
θ
1
)
d
θ
′
d
θ
′
d
θ
=
G
θ
′
′
(
S
ˇ
;
θ
−
β
∇
θ
1
)
d
(
θ
−
β
∇
θ
1
)
d
θ
=
G
θ
′
′
(
S
ˇ
;
θ
−
β
∇
θ
1
)
(
1
−
β
d
∇
θ
1
d
θ
)
\nabla_{\theta_2}=\frac{d\mathcal{G}(\check{S};\theta^{'})}{d\theta}=\frac{d\mathcal{G}(\check{S};\theta-\beta\nabla_{\theta_1})}{d\theta^{'}}\frac{d\theta^{'}}{d\theta}=\mathcal{G^{'}_{\theta^{'}}}(\check{S};\theta-\beta\nabla_{\theta_1})\frac{d(\theta-\beta\nabla_{\theta_1})}{d\theta}=\mathcal{G^{'}_{\theta^{'}}}(\check{S};\theta-\beta\nabla_{\theta_1})(1-\beta\frac{d\nabla_{\theta_1}}{d\theta})
∇θ2=dθdG(Sˇ;θ′)=dθ′dG(Sˇ;θ−β∇θ1)dθdθ′=Gθ′′(Sˇ;θ−β∇θ1)dθd(θ−β∇θ1)=Gθ′′(Sˇ;θ−β∇θ1)(1−βdθd∇θ1)
Meta-optimization: Update
θ
:
c
s
d
n
在线
m
a
r
k
d
n
o
w
的
l
a
t
e
x
不支持
b
e
g
i
n
{
a
l
i
g
n
}
标签,贴图如下
\theta:{\color{Red}csdn在线markdnow的latex不支持begin\{align\}标签,贴图如下}
θ:csdn在线markdnow的latex不支持begin{align}标签,贴图如下
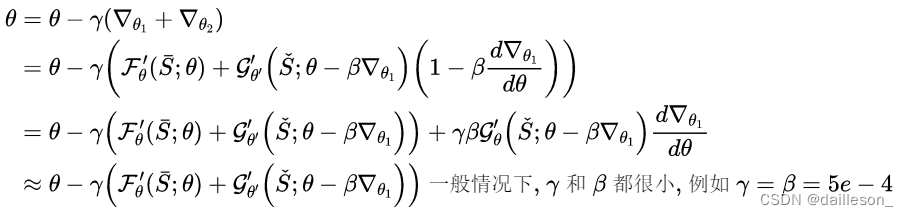
2.总结
MLDG是第一篇将meta learning引入domain generalization的论文。在这篇论文中, G ( ; ) = F ( ; ) = C r o s s E n t r o p y \mathcal{G}(;)=\mathcal{F}(;)=CrossEntropy G(;)=F(;)=CrossEntropy,二阶导几乎不起作用,训练模型的时候可以将代码中二阶导计算关掉(没用还很耗时)。
loss.backward(retain_graph=True, create_graph=True)
->改为
loss.backward(retain_graph=True, create_graph=False)
楼主跑过这篇文章的代码,性能与普通训练方式差不太多,即先在 S ˉ \bar{S} Sˉ训练更新,然后再在 S ˇ \check{S} Sˇ上训练更新。个人认为他的insight在于启发了后续的meta-dg方法,后续方法重新设计能够约束特征空间的 G ( ; ) \mathcal{G}(;) G(;),后续方法是否有效等楼主验证后再更新。














 2260
2260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









