






主要记录与其他语言c++差异的部分和比较关键的语法部分
基础
1.基本语法
1.1注释
单行注释(行注释),通过ctrl+/ 进行注释,或者解除注释
• 示例代码如下:
print(“hello python”) # 输出 hello python
多行注释(块注释)
• 要在Python程序中使用多行注释,可以用一对连续的三个引号(单引号和双引号都可以)
• Python官方提供有一系列PEP(PythonEnhancementProposals)文档
• 其中第8篇文档专门针对Python的代码格式给出了建议,也就是俗称的PEP 8
• 文档地址:https://www.python.org/dev/peps/pep-0008/
• 谷歌有对应的中文文档:http://zh-googlestyleguide.readthedocs.io/en/latest/google-pythonstyleguide/python_style_rules/
1.2命名
1.2.1标识符
标示符就是程序员定义的变量名、函数名
• 标示符可以由字母、下划线和数字组成
• 不能以数字开头
• 不能与关键字重名
1.2.2关键字
关键字就是在Python内部已经使用的标识符
• 关键字具有特殊的功能和含义
• 开发者不允许定义和关键字相同的名字的标示符
命名规则可以被视为一种惯例,并无绝对与强制目的是为了增加代码的识别和可读性
注意Python中的标识符是区分大小写的(不区分大小写的语言是指关键字不区分

1.3.变量
1.3.1变量的类型
• 在Python中定义变量是不需要指定类型(在其他很多高级语言中都需要)
• 数据类型可以分为数字型和非数字型
数字型
整型(int)
数据范围
2.7:32 位:-231~231-1 64位:-263~263-1 溢出
3.5: 在3.5中int长度理论上是无限的(初始分配28个字节)
二进制 bin 八进制 oct 十六进制 hex
浮点型(float)
浮点数是用机器上浮点数的本机双精度(64bit)表示的。提供大约17位的精度和范围从-308到308的指数。和C语言里面的double类型相同。Python 不支持32bit 的单精度浮点数。如果程序需要精确控制区间和数字精度,可以考虑使用numpy扩展库。
Python 3.X 对于浮点数默认的是提供17位数字的精度。
有效数字– 布尔型(bool)
• 真True非 0 数——非零即真,首字母要大写
• 假False 0– 复数型(complex)
• 主要用于科学计算,例如:平面场问题、波动问题、电感电容等问题
非数字型
字符串– 列表– 元组– 字典– 集合
• 使用type函数可以查看一个变量的类型,type(name)
字符串中的转义字符
• \t在控制台输出一个制表符,协助在输出文本时垂直方向保持对齐
• \n在控制台输出一个换行符
制表符的功能是在不使用表格的情况下在垂直方向按列对齐文本
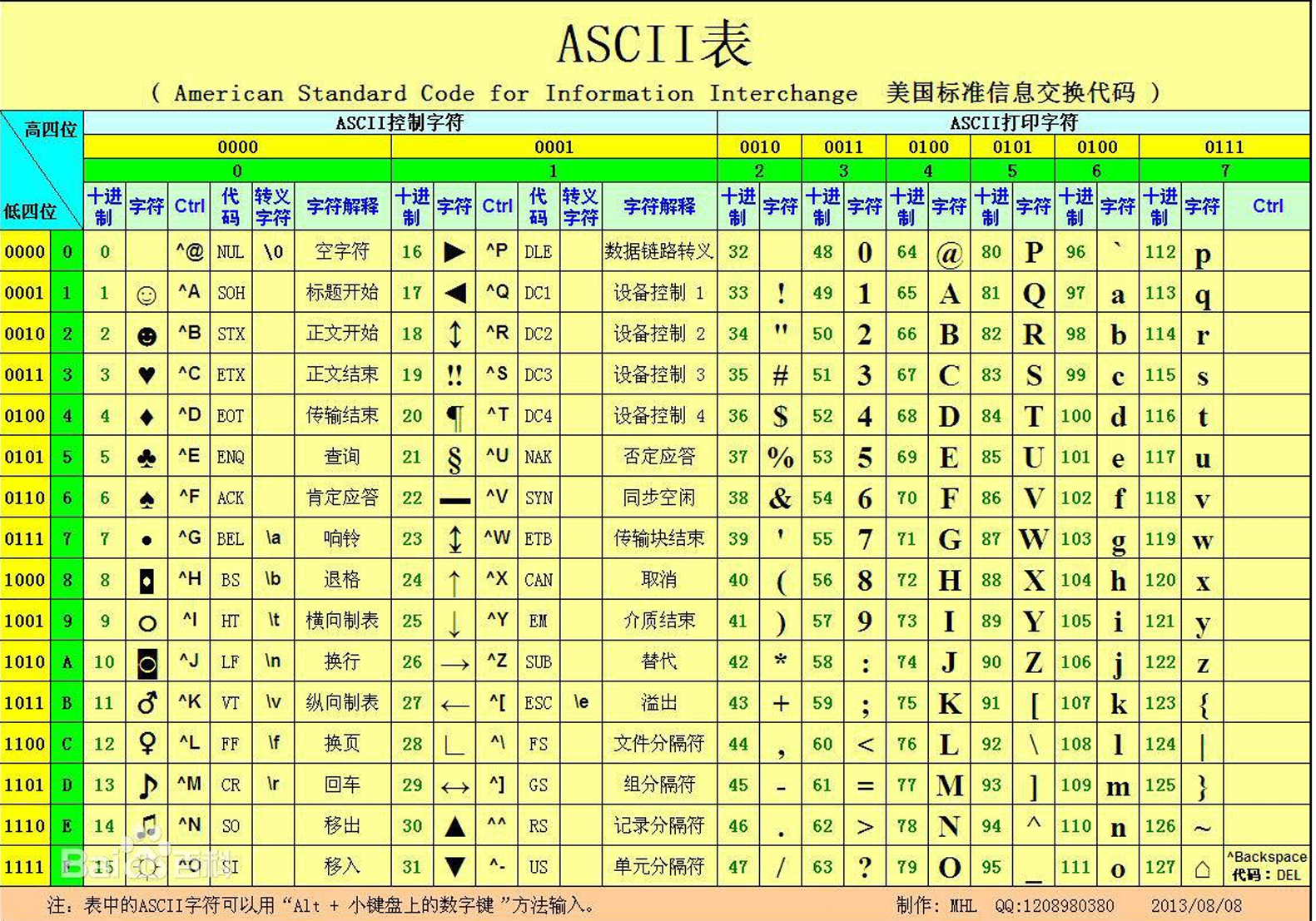
转义字符 描述
\反斜杠符号
\’单引号
\"双引号
\n换行
\t横向制表符
\r回到行首
查看一个字符的ASCII值 ord,要把一个整型转换为字符,就是chr
1.3.2不同类型变量之间的计算
- 数字型变量之间可以直接计算
- 字符串变量之间使用+拼接字符串
- 字符串变量可以和整数使用*重复拼接相同的字符串
- 数字型变量和字符串之间不能进行其他计算
1.3.4 变量的输入
- 关于函数
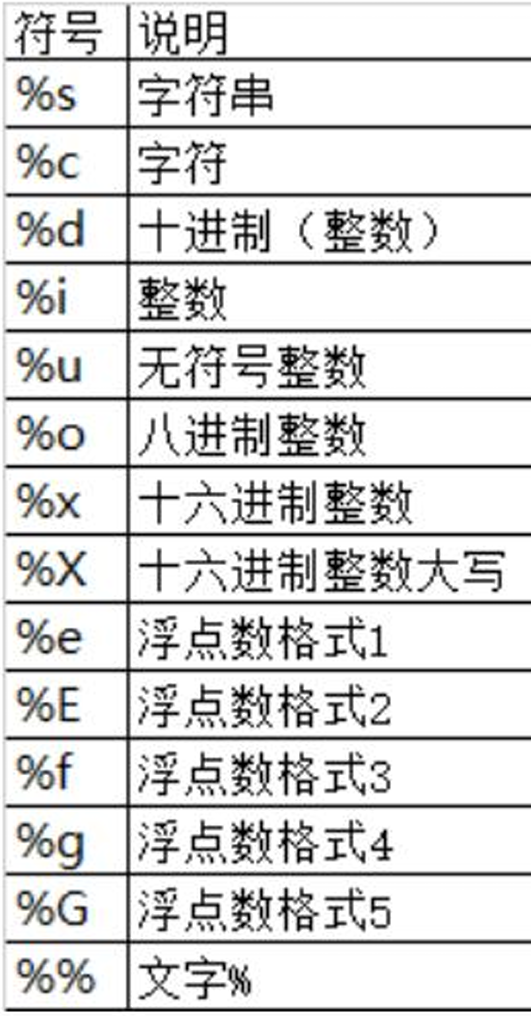
说明
print(x) 将x输出到控制台
type(x) 查看x的变量类型 - input 函数实现键盘输入
字符串变量 = input(“提示信息:”) - 类型转换函数
函数说明
int(x)将x转换为一个整数
float(x)将x转换到一个浮点数 - 变量的格式化输出

输出取整接口 round
https://www.cnblogs.com/qinchao0317/p/10699717.html
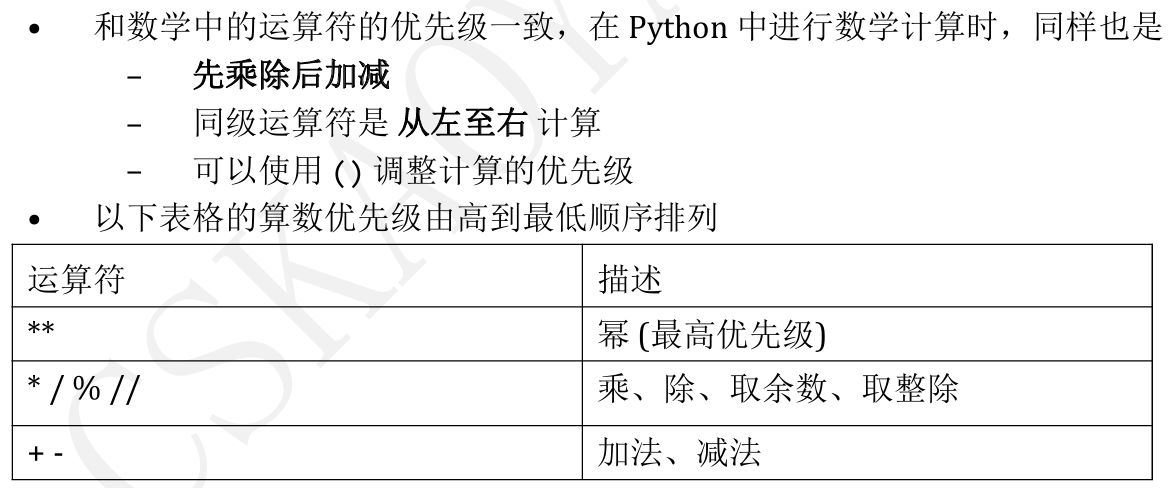
1.4运算符
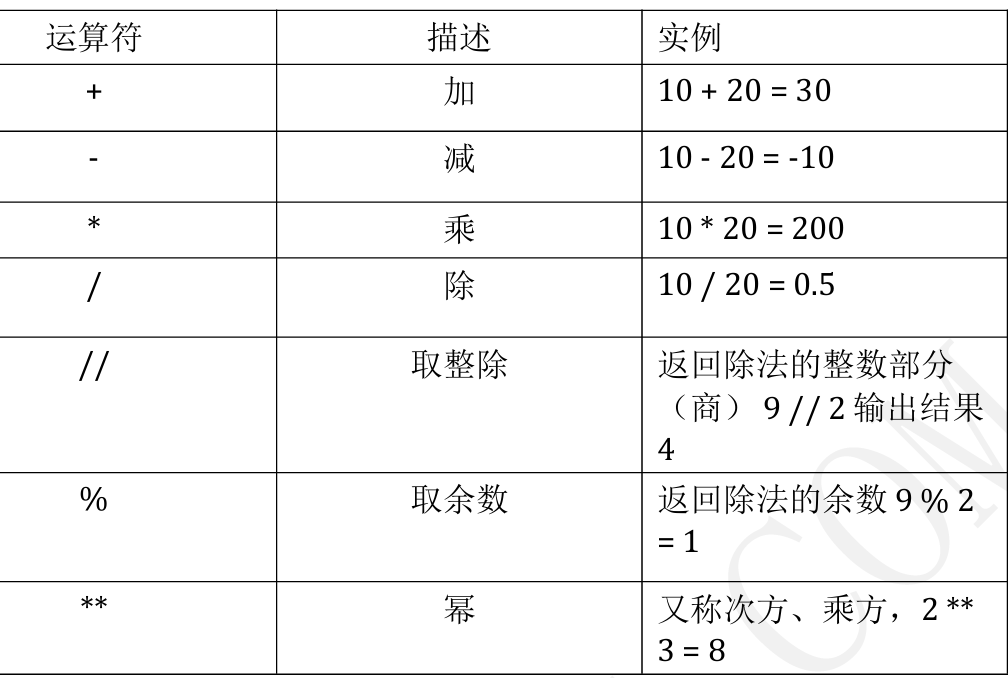
1.4.1优先级
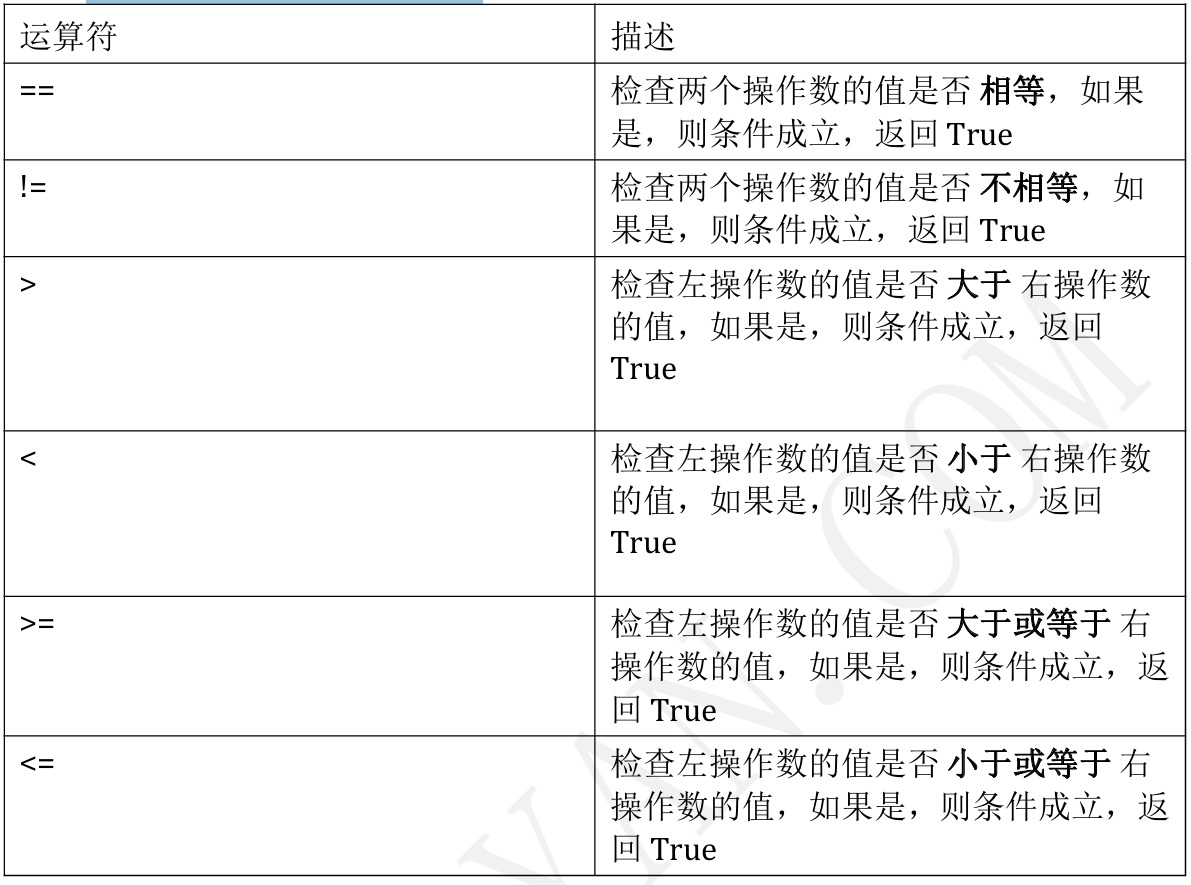
1.4.2比较(关系)运算符
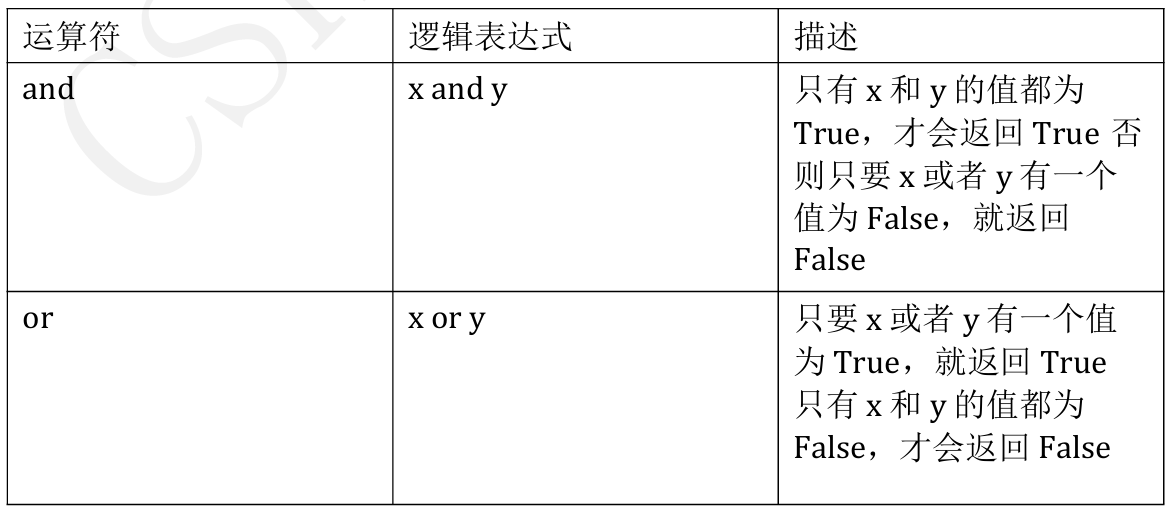
1.4.3逻辑运算符
and是遇假则假,都真返回后一个
or是遇真则真,否则返回前一个—后半句是变态的思考,没有太大作用

1.4.4赋值运算符
在Python中,使用=可以给变量赋值
•在算术运算时,为了简化代码的编写,Python还提供了一系列的与算术运算符对应的赋值运算符
•注意:赋值运算符(和运算符组合的)中间不能使用空格

1.5判断(if)语句 ,循环
1.5.1语法

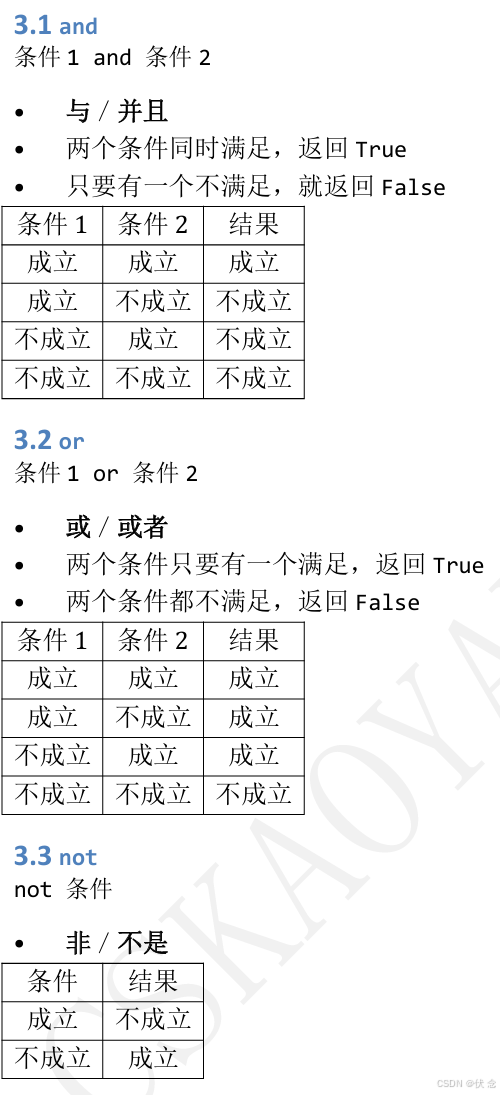
1.5.2逻辑运算
1.5.3if 语句进阶


1.5.4其它
随机数的处理

Python 中的计数方法
常见的计数方法有两种,可以分别称为:
• 自然计数法(从1开始)——更符合人类的习惯
• 程序计数法(从0开始)——几乎所有的程序语言都选择从0开始计数
因此,大家在编写程序时,应该尽量养成习惯:除非需求的特殊要求,否则循环的计数都从0开始
1.5.5循环



1.6函数
所谓函数,就是把具有独立功能的代码块组织为一个小模块,在需要的时候
调用
• 函数的使用包含两个步骤:
1.定义函数——封装独立的功能
2.调用函数——享受封装的成果
• 函数的作用,在开发程序时,使用函数可以提高编写的效率以及代码的重用
2.1 函数的定义
定义函数的格式如下:
def 函数名():
def 是英文define的缩写
函数名称应该能够表达函数封装代码的功能,方便后续的调用
函数名称的命名应该符合标识符的命名规则
– 可以由字母、下划线和数字组成– 不能以数字开头– 不能与关键字重
PyCharm 的调试工具
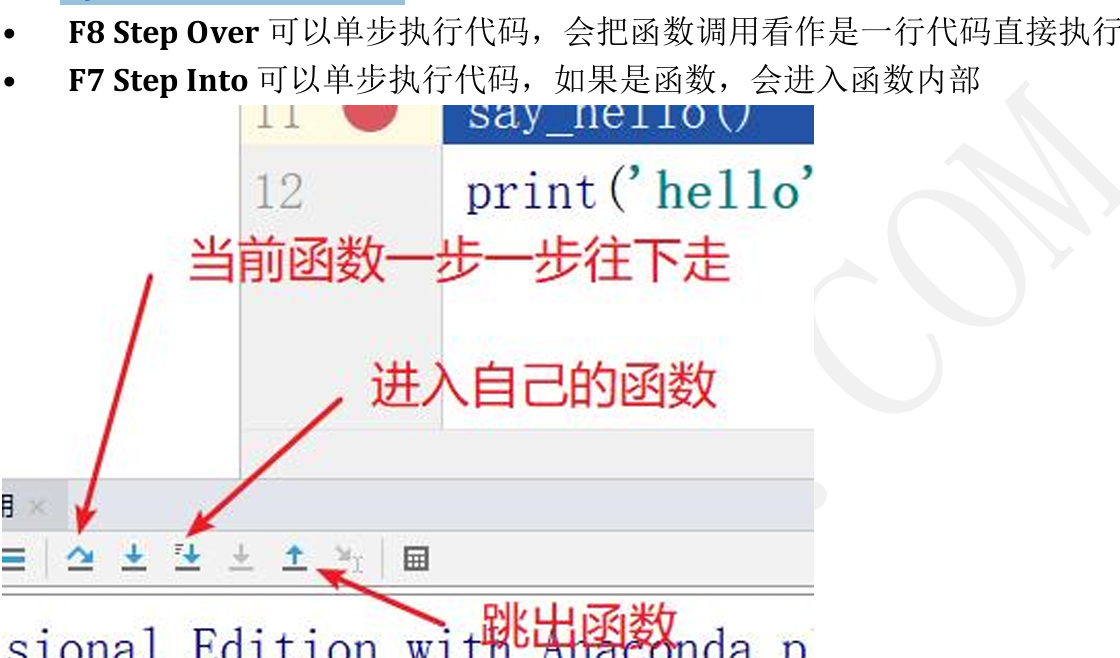

1.6.1 使用模块中的函数

1.6.2 模块名也是一个标识符
• 标示符可以由字母、下划线和数字组成
• 不能以数字开头
• 不能与关键字重名
注意:如果在给Python文件起名时,以数字开头是无法在PyCharm中通过导入这个模块的
1.6.3字节码
• Python在解释源程序时是分成两个步骤的
1.首先处理源代码,编译生成一个二进制字节码
2.再对字节码进行处理,才会生成CPU能够识别的机器码
• 有了模块的字节码文件之后,下一次运行程序时,如果在上次保存字节码之后没有修改过源代码,Python将会加载.pyc文件并跳过编译这个步骤
• 当Python重编译时,它会自动检查源文件和字节码文件的时间戳
• 如果你又修改了源代码,下次程序运行时,字节码将自动重新创建
提示:有关模块以及模块的其他导入方式,后续课程还会逐渐展开!
模块是Python程序架构的一个核心概念
• Python 什么情况下会生成pyc文件?
https://www.zhihu.com/question/30296617
2高级变量
2.1变量的引用
• 变量和数据都是保存在内存中的
• 在Python中函数的参数传递以及返回值都是靠引用传递的
在Python中
• 变量和数据是分开存储的
• 数据保存在内存中的一个位置
•变量中保存着数据在内存中的地址—这是重点
•变量中记录数据的地址,就叫做引用
•使用id()函数可以查看变量中保存数据所在的内存地址
注意:如果变量已经被定义,当给一个变量赋值的时候,本质上是修改了数据的引用
•变量不再对之前的数据引用
•变量改为对新赋值的数据引用
函数的参数和返回值的传递:在Python中,函数的实参/返回值都是是靠引用来传递来的
2.2 可变和不可变类型
不可变类型,内存中的数据不允许被修改:
– 数字类型int,bool,float,complex– 字符串str– 元组tuple
不可以实现在被调函数内去修改调用函数内的某个变量值
可变类型,内存中的数据可以被修改:
– 列表list– 字典dict– 集合set
通过接口改变的是数据所在的位置,变量的地址没变
2.3. 局部变量和全局变量
局部变量是在函数内部定义的变量,只能在函数内部使用
全局变量是在函数外部定义的变量(没有定义在某一个函数内),所有函数内部都可以使用这个变量
提示:在其他的开发语言中,大多不推荐使用全局变量——可变范围太大,导致程序不好维护!
局部变量
• 局部变量是在函数内部定义的变量,只能在函数内部使用
• 函数执行结束后,函数内部的局部变量,会被系统回收
• 不同的函数,可以定义相同的名字的局部变量,但是彼此之间不会产生影响局部变量的生命周期
• 所谓生命周期就是变量从被创建到被系统回收的过程
• 局部变量在函数执行时才会被创建
• 函数执行结束后局部变量被系统回收
• 局部变量在生命周期内,可以用来存储函数内部临时使用到的数据
全局变量
• 全局变量是在函数外部定义的变量,所有函数内部都可以使用这个变量
- 函数不能直接修改全局变量的引用
• 全局变量是在函数外部定义的变量(没有定义在某一个函数内),所有函数内部都可以使用这个变量
• 在函数内部,可以通过全局变量的引用获取对应的数据
• 但是,不允许直接修改全局变量的引用——使用赋值语句修改全局变量的值
注意:字典的key只能使用不可变类型的数据
注意
1.可变类型的数据变化,是通过方法来实现的
2.如果给一个可变类型的变量,赋值了一个新的数据,引用会修改
– 变量不再对之前的数据引用– 变量改为对新赋值的数据引用
在函数内部修改全局变量的值
• 如果在函数中需要修改全局变量,需要使用global进行声明
在__main__下的是全局变量
虽然是全局变量,但是对外(对其他模块)不可见
3高级变量类型
Python中数据类型可以分为数字型和非数字型
数字型
– 整型(int)
– 浮点型(float)
– 布尔型(bool)
• 真True非 0 数——非零即真
• 假False0
– 复数型(complex)
• 主要用于科学计算,例如:平面场问题、波动问题、电感电容等问题
非数字型(python的容器)
– 列表
– 元组
– 字典
– 字符串
– 集合
在Python中,所有非数字型变量都支持以下特点:
都是一个序列sequence,也可以理解为容器
取值[]
遍历 in for i in xx:
计算长度、最大/最小值、比较、删除
链接+和重复*
切片
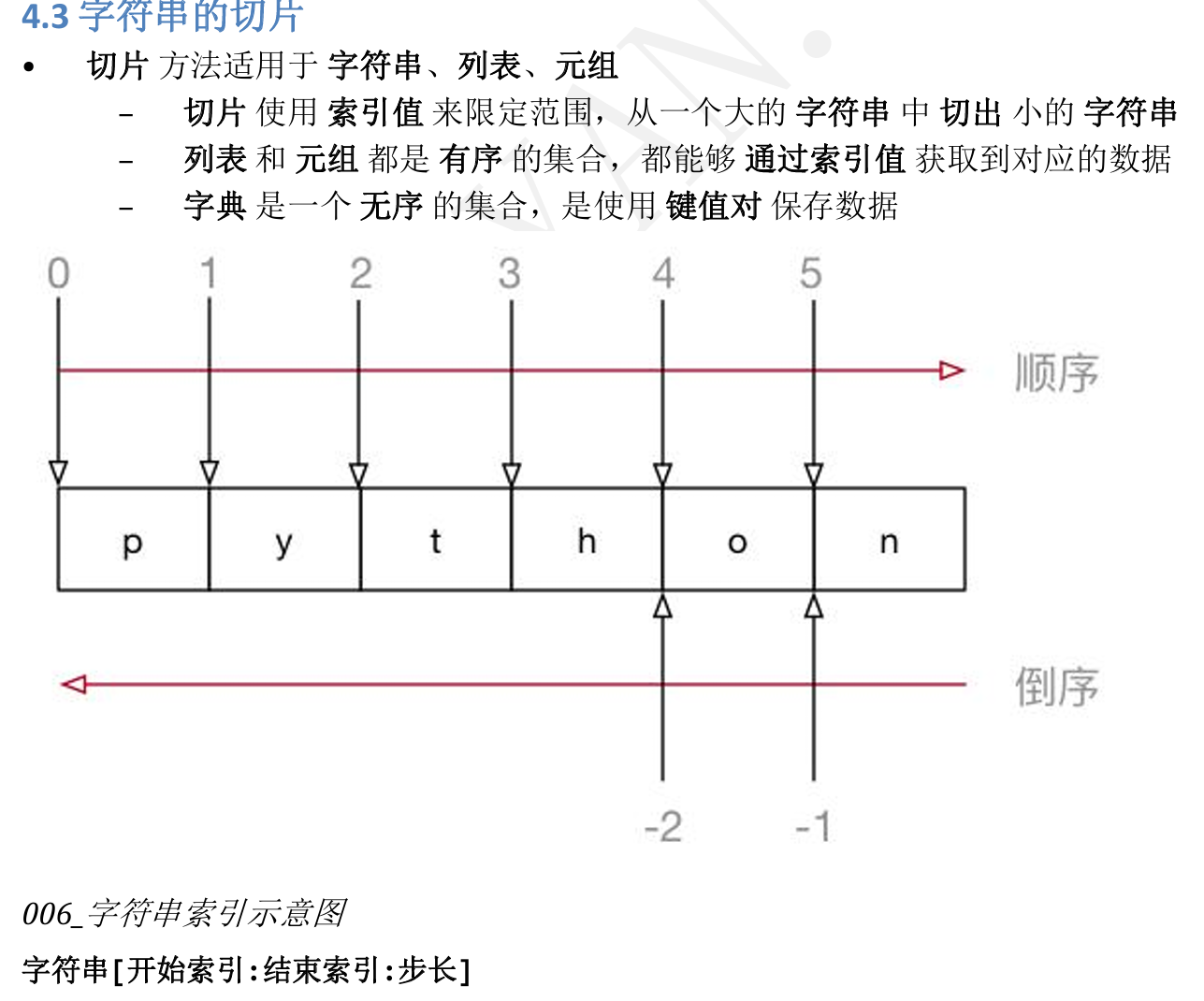
3.1列表
3.1.1列表的定义

3.1.2列表常用操作
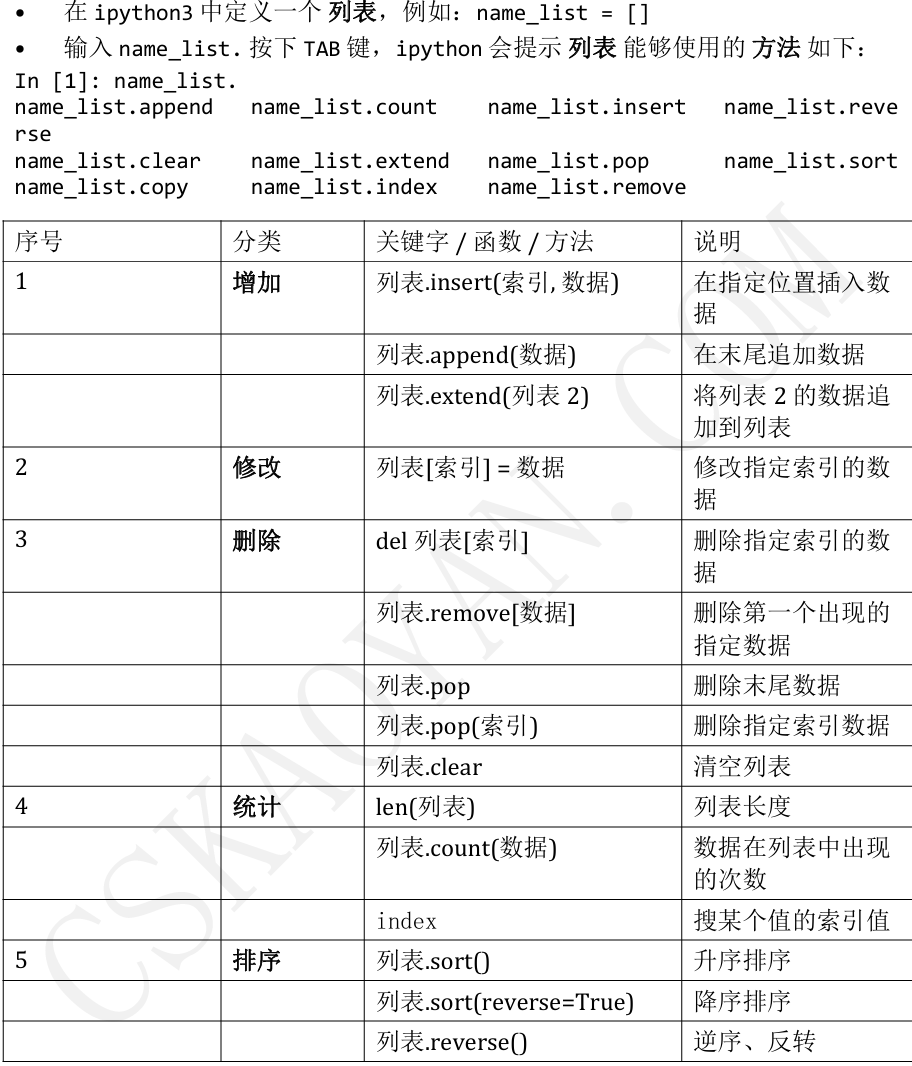


3.1.3循环遍历

3.1.4列表生成式

3.1.5列表内存存储及列表的算法效率
index() 取下标去拿某一个元素O(1)
pop() O(1)
pop(i) O(n)
insert(i,item) O(n)
del operator O(n)
iteration O(n)
contains(in) O(n)
get slice[x:y] O(k)
del slice O(n)
set slice O(n+k)
reverse O(n)
concatenate O(k)
sort O(nlogn) 归并排序
multiply O(nk)
3.2元组

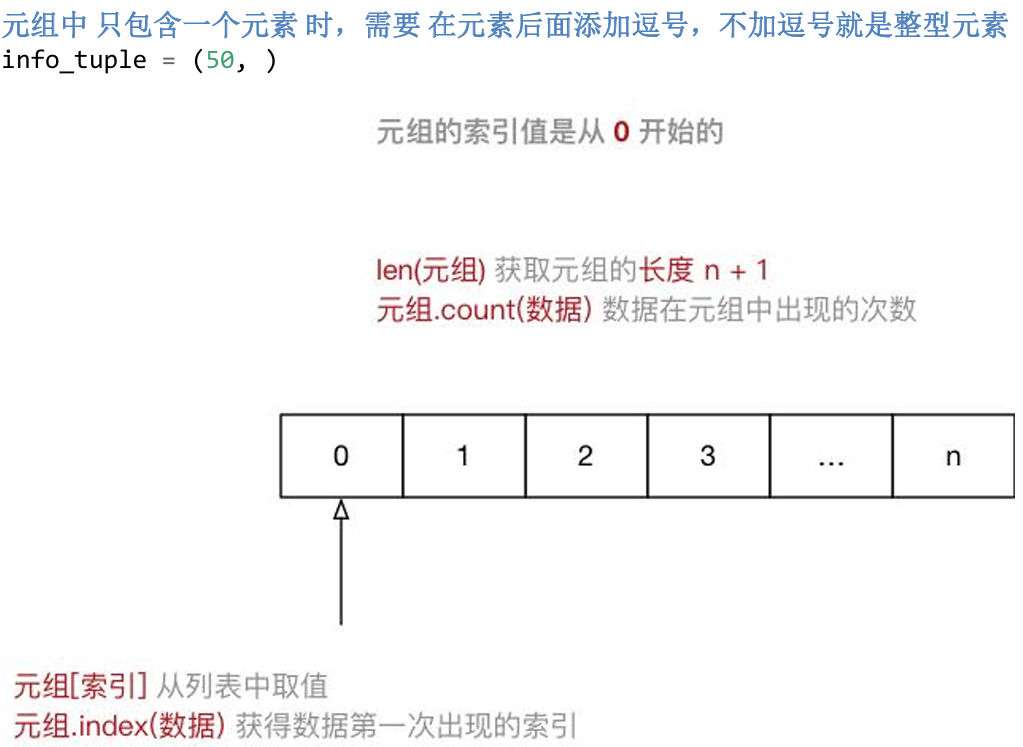

应用场景

3.3字典

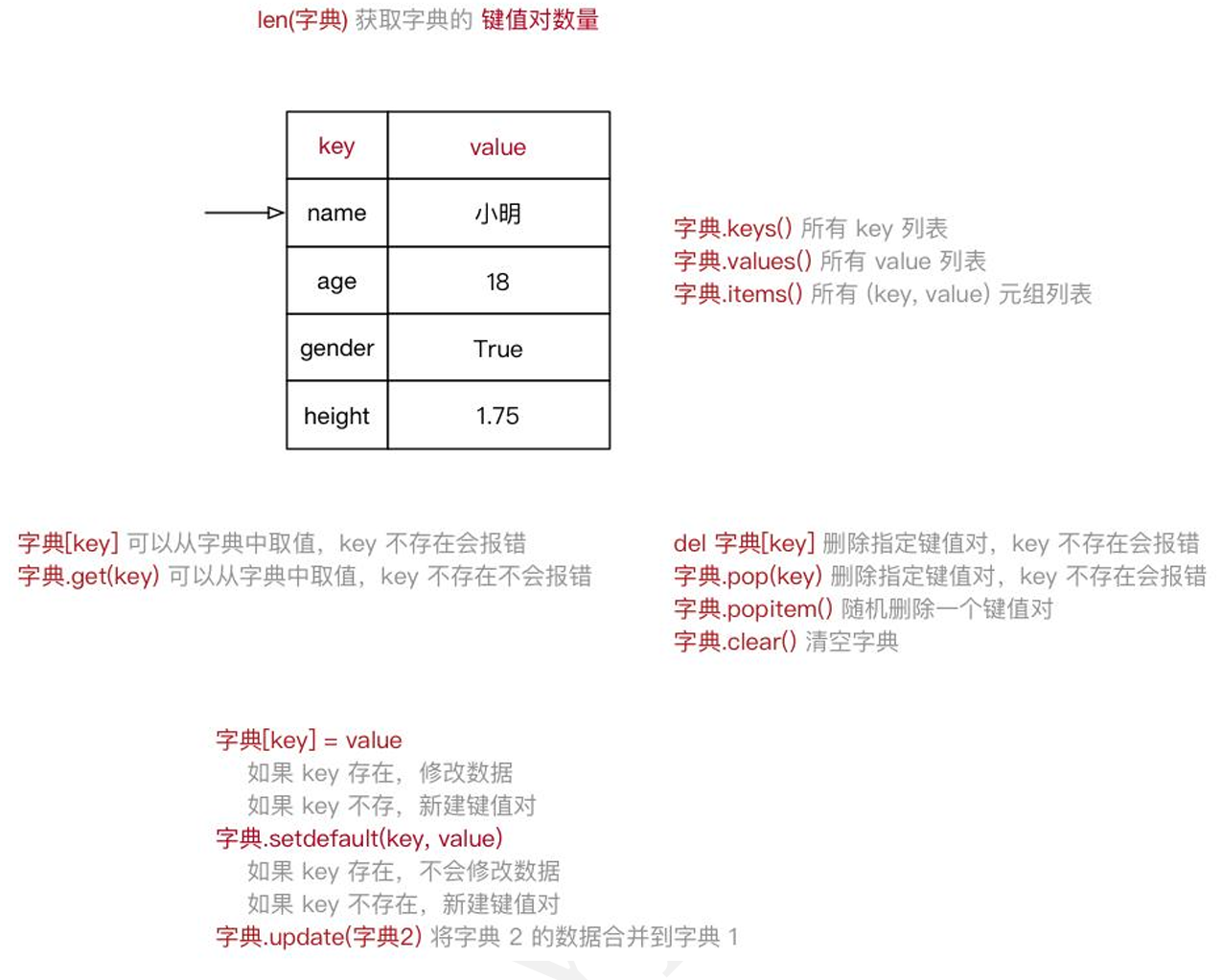

3.4字符串

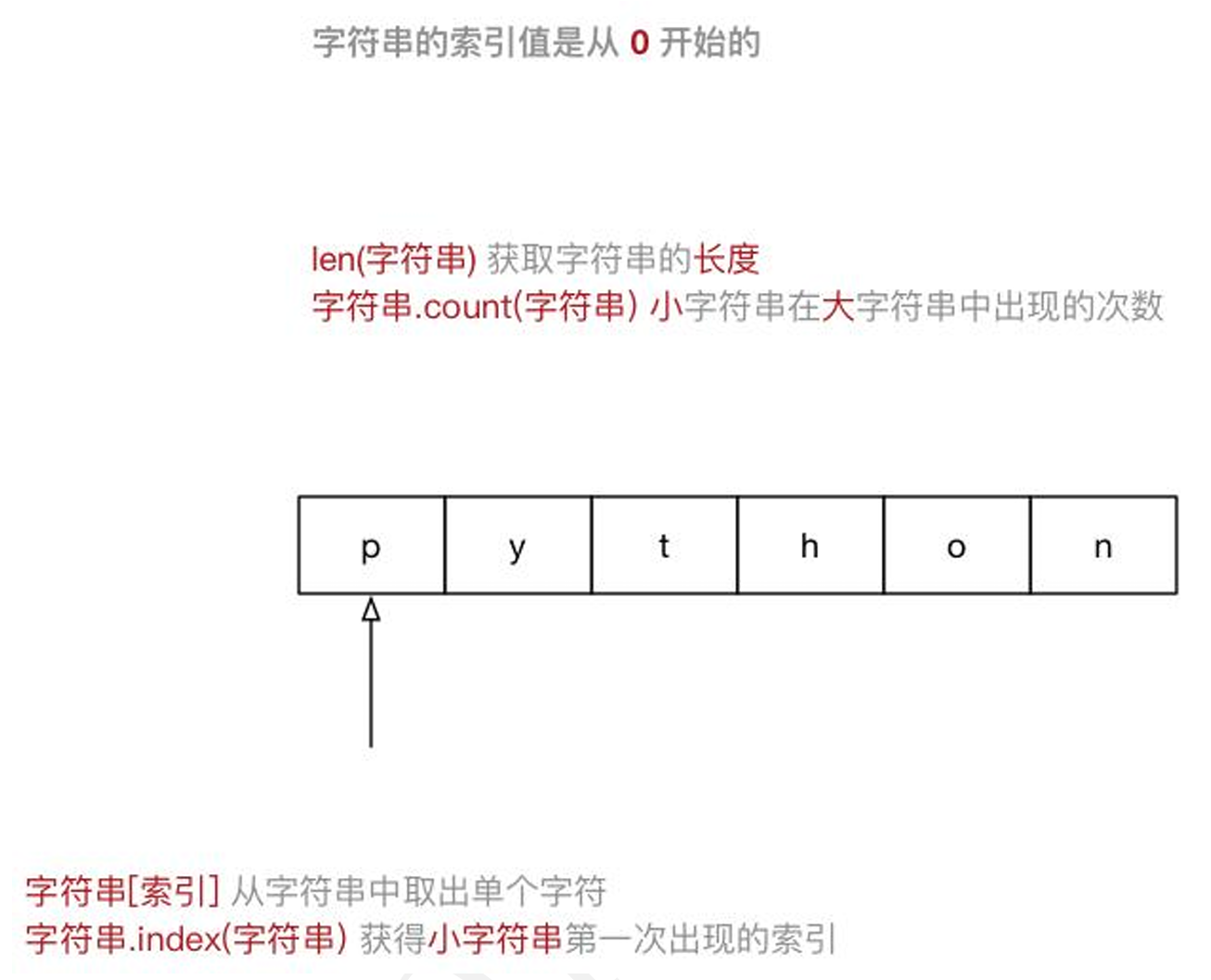

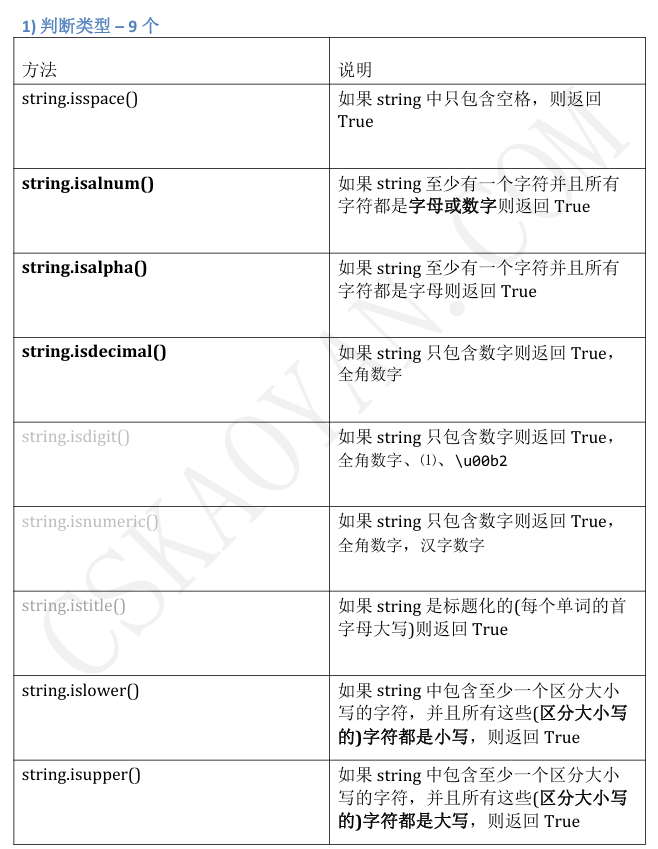

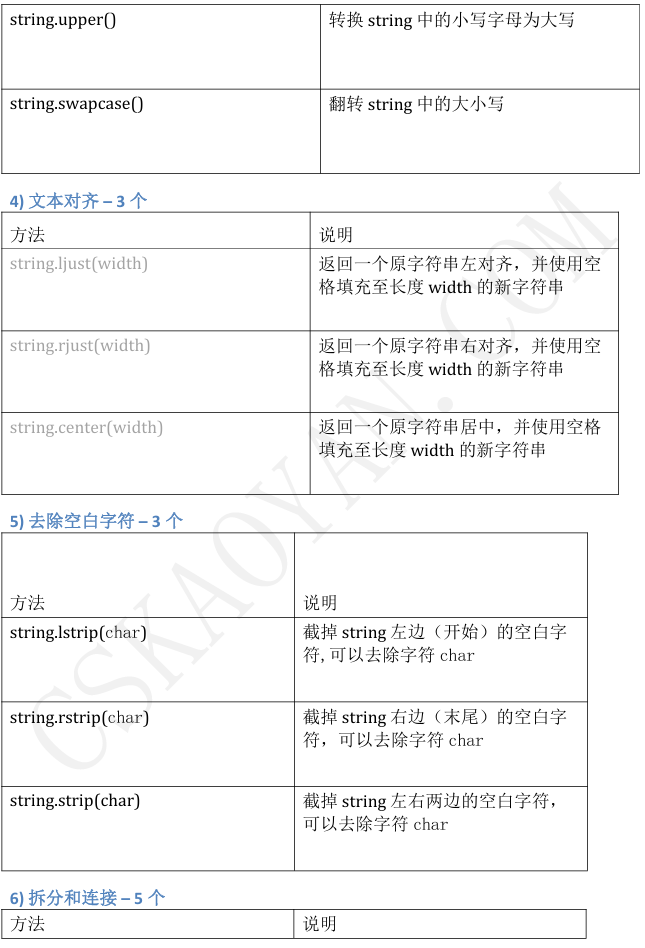
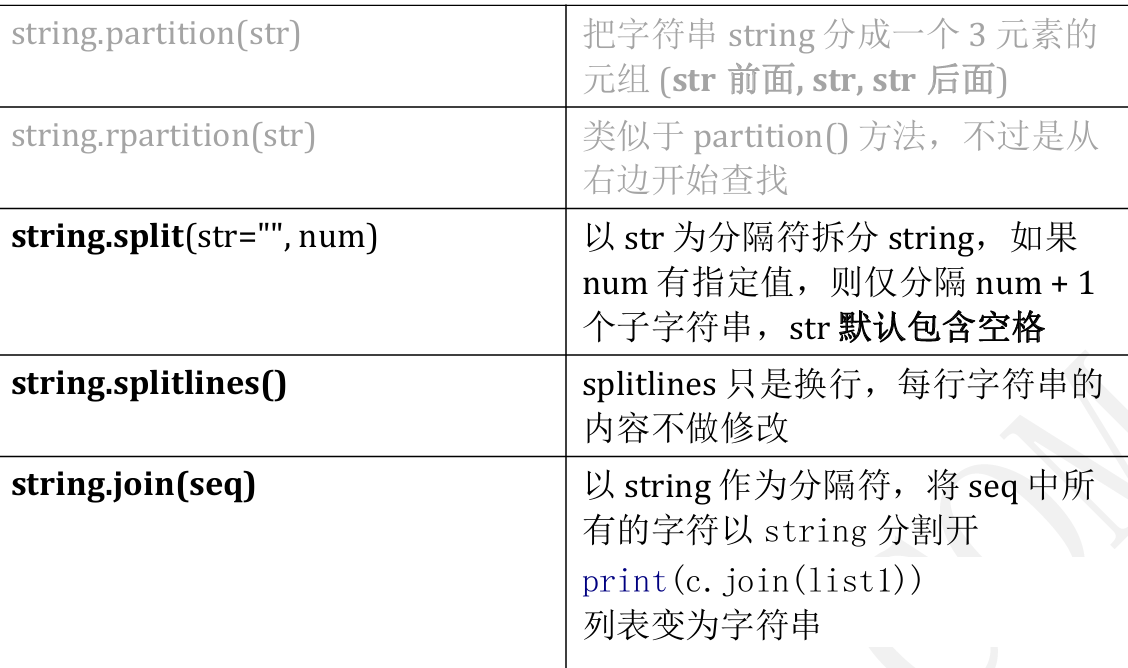

3.5集合

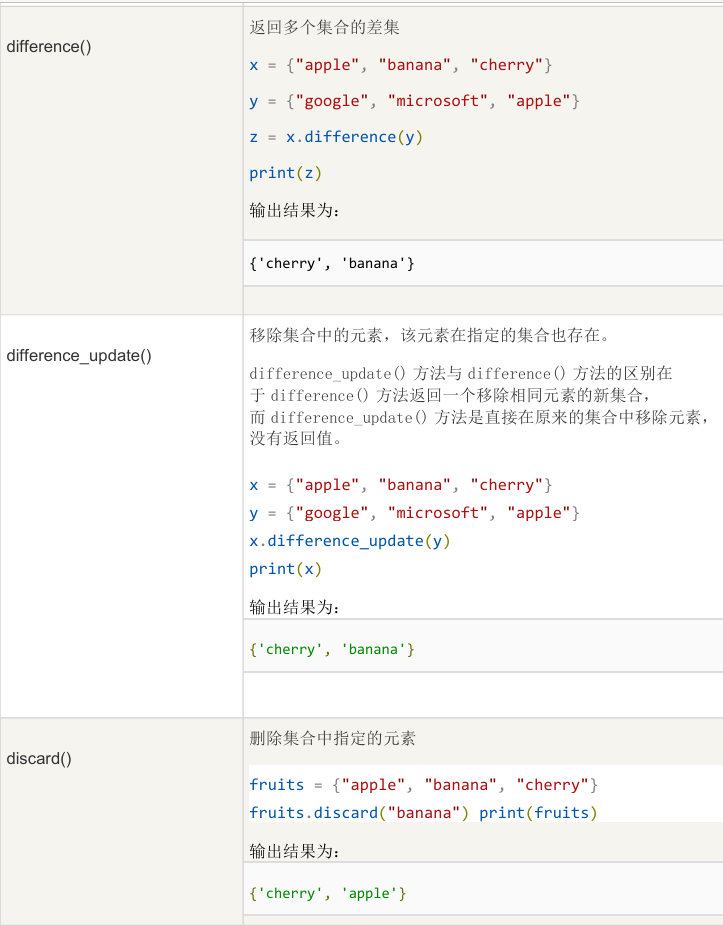
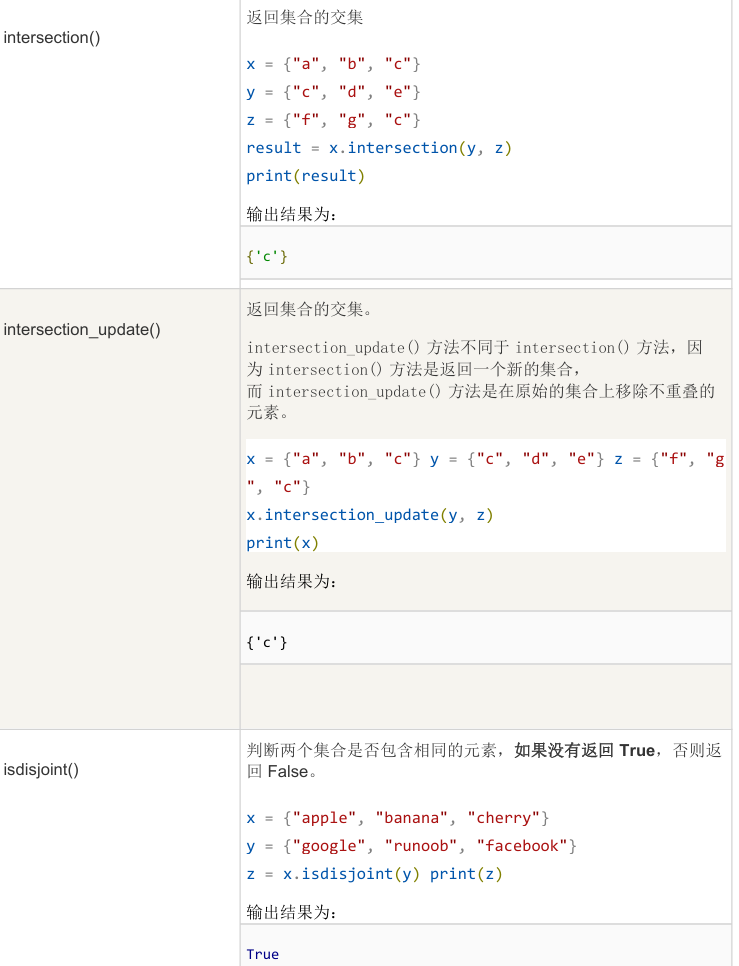
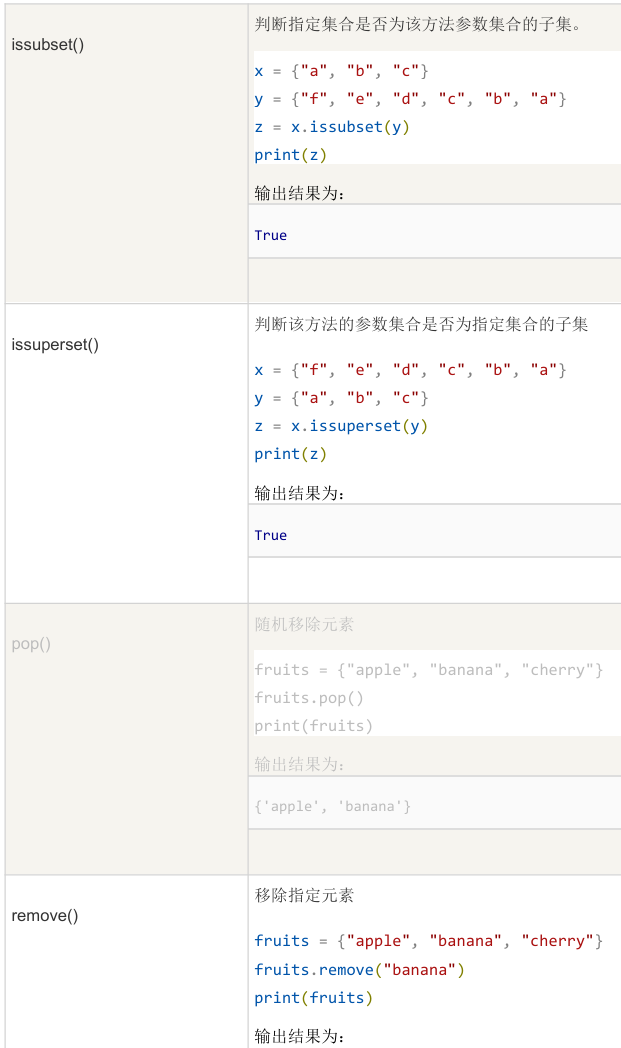
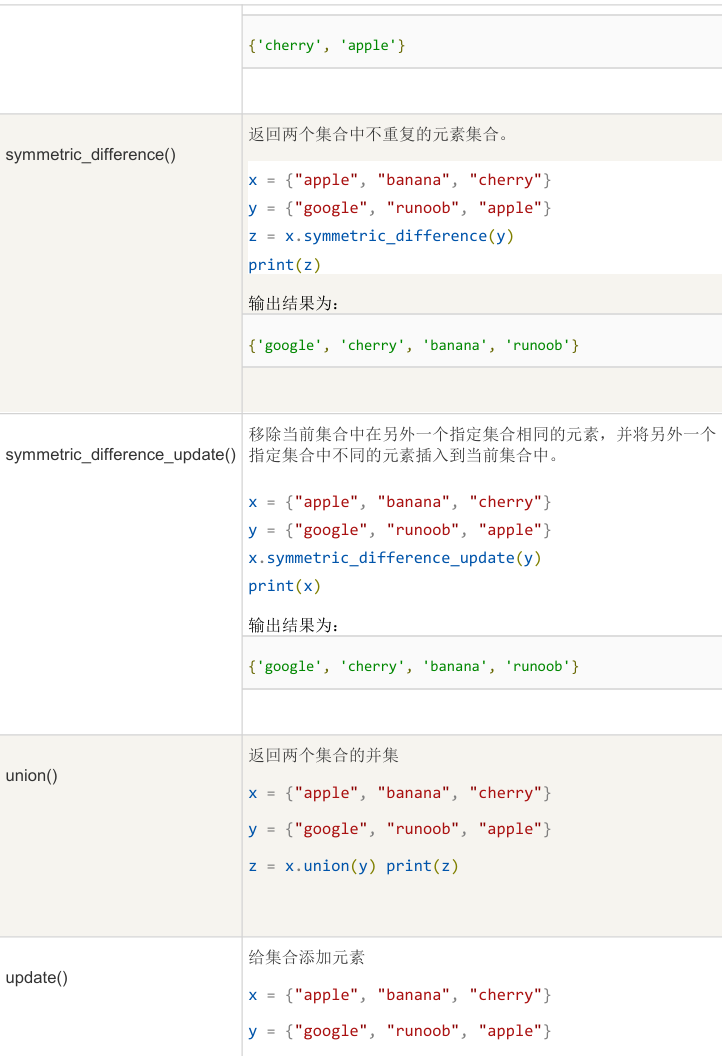

3.6公共方法
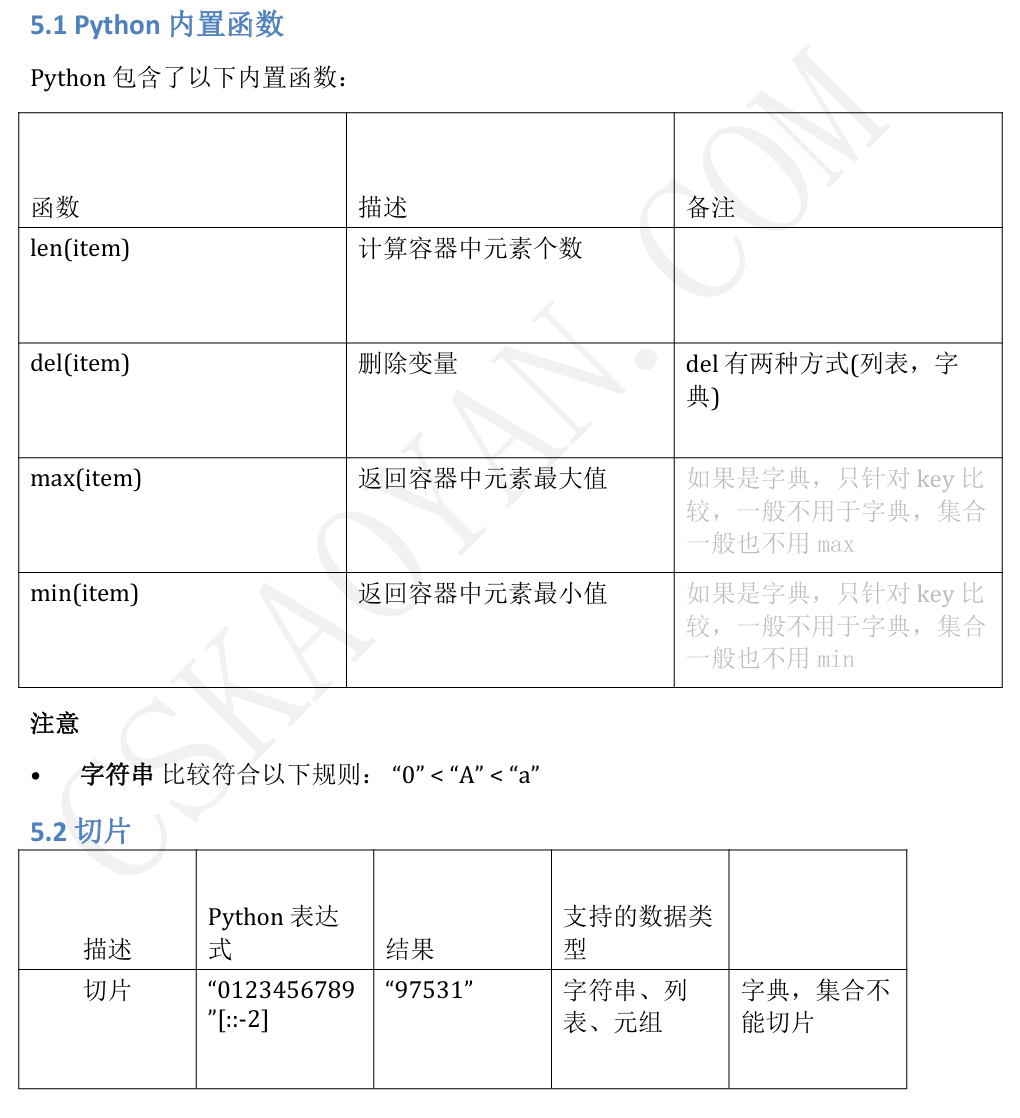
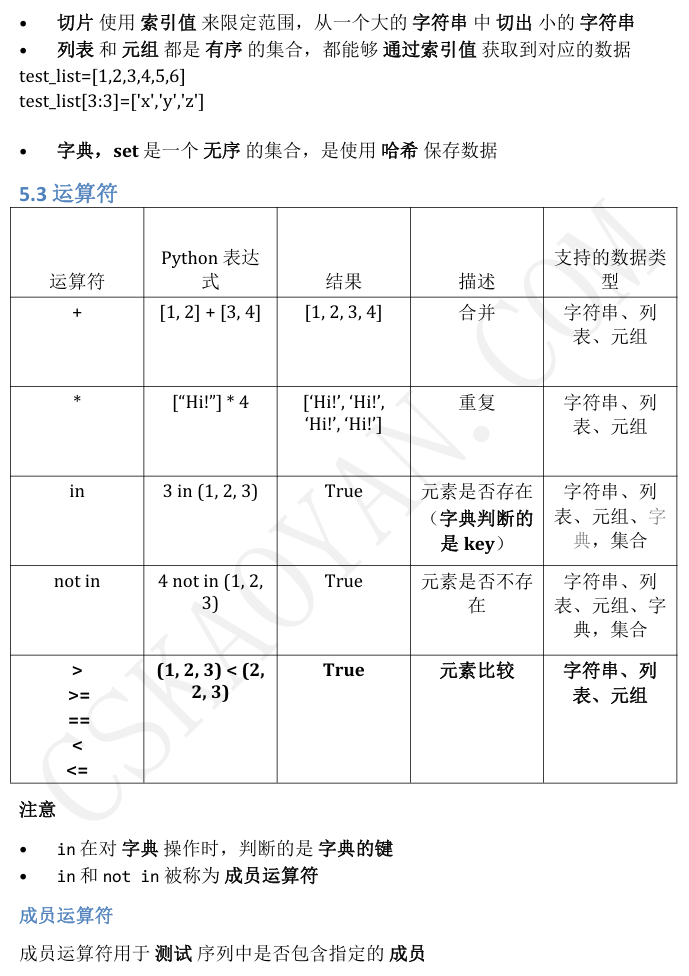
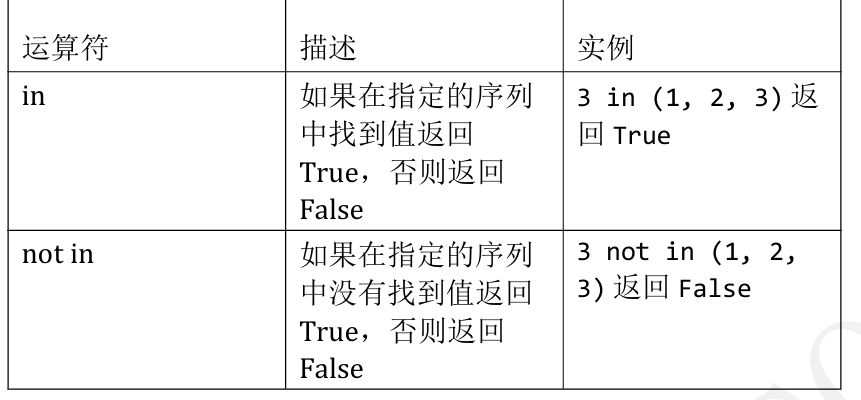
3.7针对内存存储结构
https://blog.csdn.net/xiongchengluo1129/article/details/78770177

4函数进阶
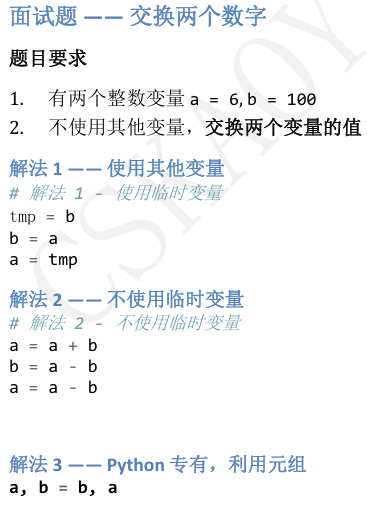
4.1函数的参数进阶

在python中,列表变量调用+=本质上是在执行列表变量的extend方法,不会修改变量的引用,就是变量的id值没变
4.2缺省参数


4.3多值参数

4.4 eval函数
eval() 函数十分强大——将字符串当成有效的表达式来求值并返回计算结果

面向对象
5面向对象基础语法

5.1dir内置函数
• 在Python中对象几乎是无所不在的,我们之前学习的变量、数据、函数都是对象
在Python中可以使用以下两个方法验证:
1 在标识符/数据后输入一个.,然后按下TAB键,iPython会提示该对象能够调用的方法列表
2 使用内置函数dir传入标识符/数据,可以查看对象内的所有属性及方法
提示__方法名__格式的方法是Python提供的内置方法/属性
一些常用的内置方法/属性

5.2定义简单的类(只包含方法)
面向对象是更大的封装,在一个类中封装多个方法,这样通过这个类创建出来的对象,就可以直接调用这些方法了

方法的定义格式和之前学习过的函数几乎一样
• 区别在于第一个参数必须是self
注意:类名的命名规则要符合大驼峰命名法

引用概念的强调
在面向对象开发中,引用的概念是同样适用的!
• 在Python中使用类创建对象之后,tom变量中仍然记录的是对象在内存中的地址
• 也就是tom变量引用了新建的猫对象
• 使用print输出对象变量,默认情况下,是能够输出这个变量引用的对象是由哪一个类创建的对象,以及在内存中的地址(十六进制表示)
5.3方法中的self参数
在Python中,要给对象设置属性,非常的容易,但是不推荐使用,因为对象属性的封装应该封装在类的内部
• 只需要在类的外部的代码中直接通过.设置一个属性即可
注意:这种方式虽然简单,但是不推荐使用!
在类的外部,通过变量名.访问对象的属性和方法。在类封装的方法中,通过self.访问对象的属性和方法
5.4初始化方法
在日常开发中,不推荐在类的外部给对象增加属性–
如果在运行时,没有找到属性,程序会报错AttributeError: ‘Dog’ object has no attribute ‘cute’
对象应该包含有哪些属性,应该封装在类的内部!


5.5内置方法和属性
del 方法 对象被从内存中销毁前,会被自动调用
str 方法 返回对象的描述信息,print函数输出使用


5.6None与身份运算符


5.7私有属性和私有方法
应用场景及定义方式

伪私有属性和私有方法(科普)

6封装,继承与多态
6.1封装
为啥要封装
好处
1.在使用面向过程编程时,当需要对数据处理时,需要考虑用哪个模块中哪个函数来进行操作,但是当用面向对象编程时,因为已经将数据存储到了这个独立的空间中,这个独立的空间(即对象)中通过一个特殊的变量(class)能够获取到类(模板),而且这个类中的方法是有一定数量的,与此类无关的将不会出现在本类中,因此需要对数据处理时,可以很快速的定位到需要的方法是谁这样更方便
2.全局变量是只能有1份的,多很多个函数需要多个备份时,往往需要利用其它的变量来进行储存;而通过封装会将用来存储数据的这个变量变为了对象中的一个“全局”变量,只要对象不一样那么这个变量就可以再有1份,所以这样更方便
3.代码划分更清晰
6.2单继承
6.2.1基础
为啥要继承
1.能够提升代码的重用率,即开发一个类,可以在多个子功能中直接使用
2.继承能够有效的进行代码的管理,当某个类有问题只要修改这个类就行,而其继承这个类的子类往往不需要就修改
继承的概念:子类拥有父类的所有方法和属性






6.2.2单继承super
1.super().__init__相对于类名.init,在单继承上用法基本无差
2.但在多继承上有区别,super方法能保证每个父类的方法只会执行一次,而使用类名的方法会导致方法被执行多次(尽量避免使用类名方法调用)
3.多继承时,使用super方法,对父类的传参数,应该是由于python中super的算法导致的原因,必须把参数全部传递,否则会报错
4.单继承时,使用super方法,则不能全部传递,只能传父类方法所需的参数,否则会报错
5.多继承时,相对于使用类名.__init__方法,要把每个父类全部写一遍, 而使用super 方法,只需写一句话便执行了全部父类的方法,这也是为何多继承需要全部传参的一个原因
6.2.3面试题
class Parent(object):
x = 1
class Child1(Parent):
pass
class Child2(Parent):
pass
print(Parent.x, Child1.x, Child2.x)
Child1.x = 2
print(Parent.x, Child1.x, Child2.x)
Parent.x = 3
print(Parent.x, Child1.x, Child2.x)
答案, 以上代码的输出是:
1 1 1
1 2 1
3 2 3
使你困惑或是惊奇的是关于最后一行的输出是 323 而不是 321。为什么改变了Parent.x 的值还会改变 Child2.x 的值,但是同时 Child1.x 值却没有改变?
这个答案的关键是,在 Python 中,类变量在内部是作为字典处理的。如果一个变量的名字没有在当前类的字典中发现,将搜索祖先类(比如父类)直到被引用的变量名被找到(如果这个被引用的变量名既没有在自己所在的类又没有在祖先类中找到,会引发一个 AttributeError 异常 )。
因此,在父类中设置 x=1 会使得类变量 x 在引用该类和其任何子类中的值为1。这就是因为第一个 print 语句的输出是 111。
随后,如果任何它的子类重写了该值(例如,我们执行语句 Child1.x=2),然后,该值仅仅在子类中被改变。这就是为什么第二个 print 语句的输出是 121。
最后,如果该值在父类中被改变(例如,我们执行语句 Parent.x=3),这个改变会影响到任何未重写该值的子类当中的值(在这个示例中被影响的子类是Child2)。这就是为什么第三个 print 输出是 323。
思考
思考题:
如果打印要求是下面的样子,请问输出结果是多少呢?
c1=Child1()
c2=Child2()
p=Parent()
print(c1.x,c2.x,p.x) #111
c1.x=2
print(c1.x,c2.x,p.x) #211
p.x=3
print(c1.x,c2.x,p.x) #213
6.3多继承
6.3.1基础
子类可以拥有多个父类,并且具有所有父类的属性和方法
class 子类名(父类名1, 父类名2…)
pass


6.3.2菱形继承
单独调用父类的方法


多继承中super调用有所父类的被重写的方法


注意:
1.以上2个代码执行的结果不同
2.如果2个子类中都继承了父类,当在子类中通过父类名调用时,parent被执行了2次,这种方式弊大于利(1.1中的实例)
3.如果2个子类中都继承了父类,当在子类中通过super调用时,parent被执行了1次
4.Python 里我们只讲重写,不讲重载(C++里讲重载,相同方法名字根据形参类型不同,调用不同函数),Python里不能出现相同的函数名,子类中覆盖父类中相同函数
6.4多态
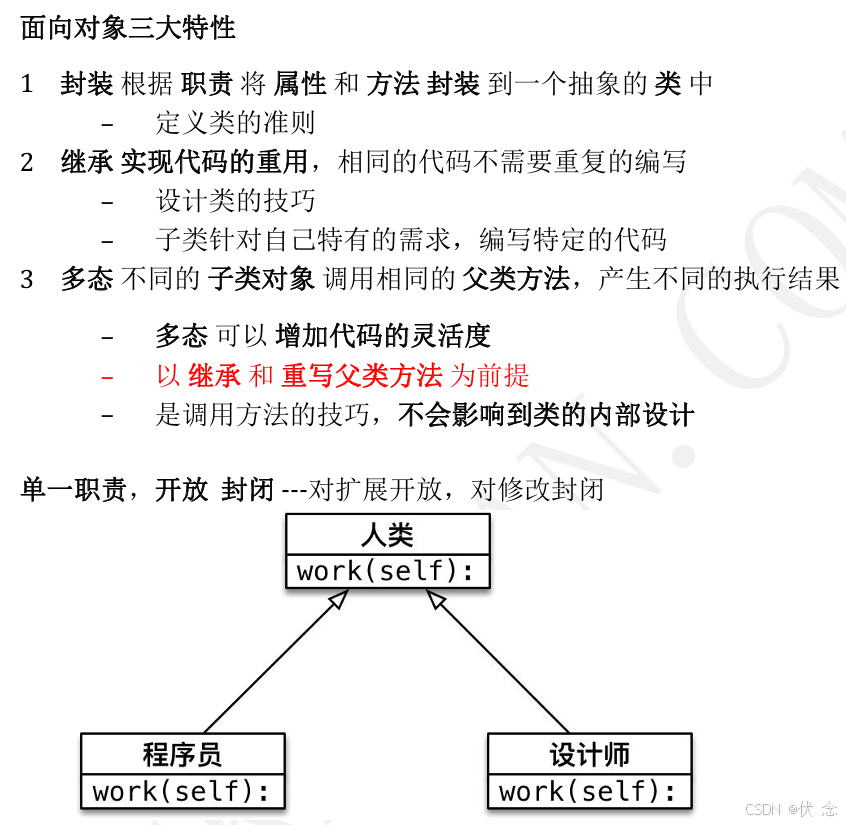
7 类属性和类方法
7.1类的结构
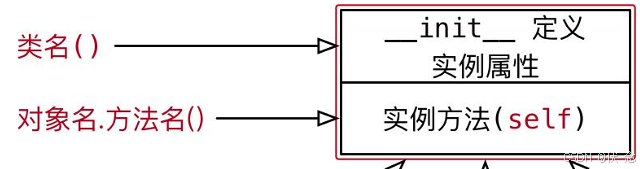

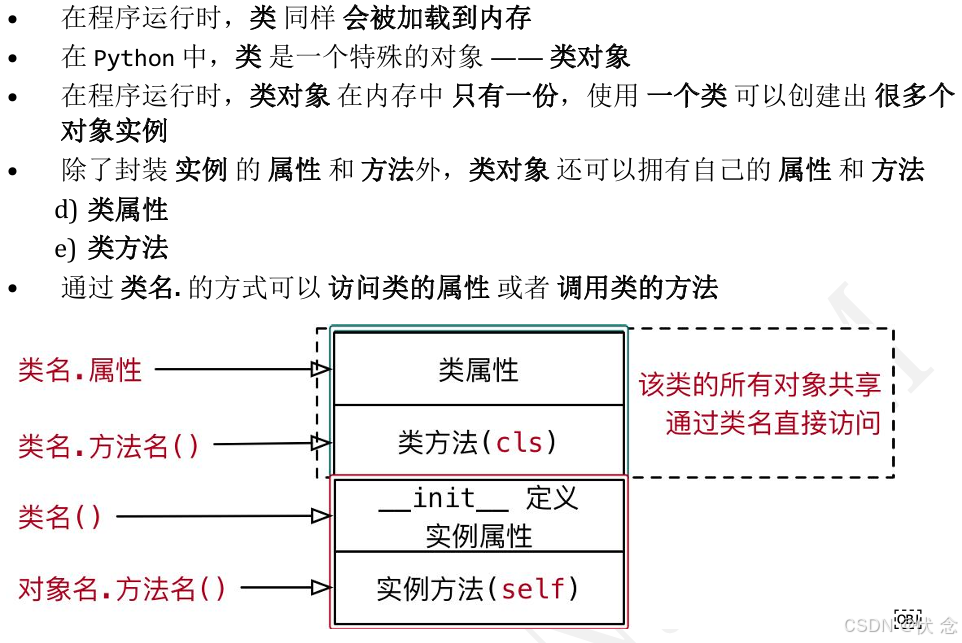
7.2类属性和实例属性


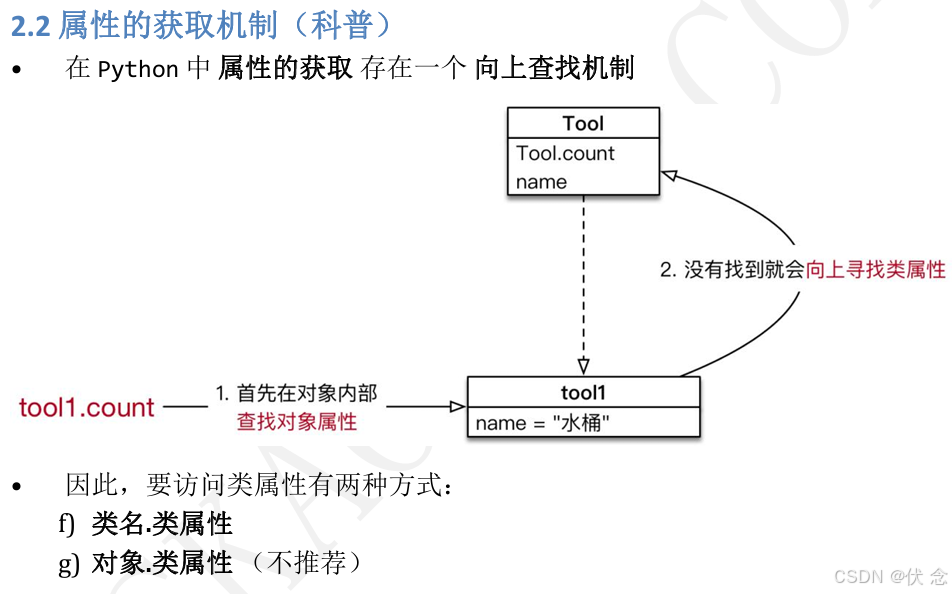
7.3类方法和静态方法(使用不频繁)
实例方法:由对象调用;至少一个self参数;执行实例方法时,自动将调用该方法的对象赋值给self;
类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类赋值给cls;
静态方法:由类调用;无默认参数;
相同点:对于所有的方法而言,均属于类,所以在内存中也只保存一份
不同点:方法调用者不同、调用方法时自动传入的参数不同。




8 设计模式
8.1单例模式
目的
让类创建的对象,在系统中只有唯一的一个实例
每一次执行类名()返回的对象,内存地址是相同
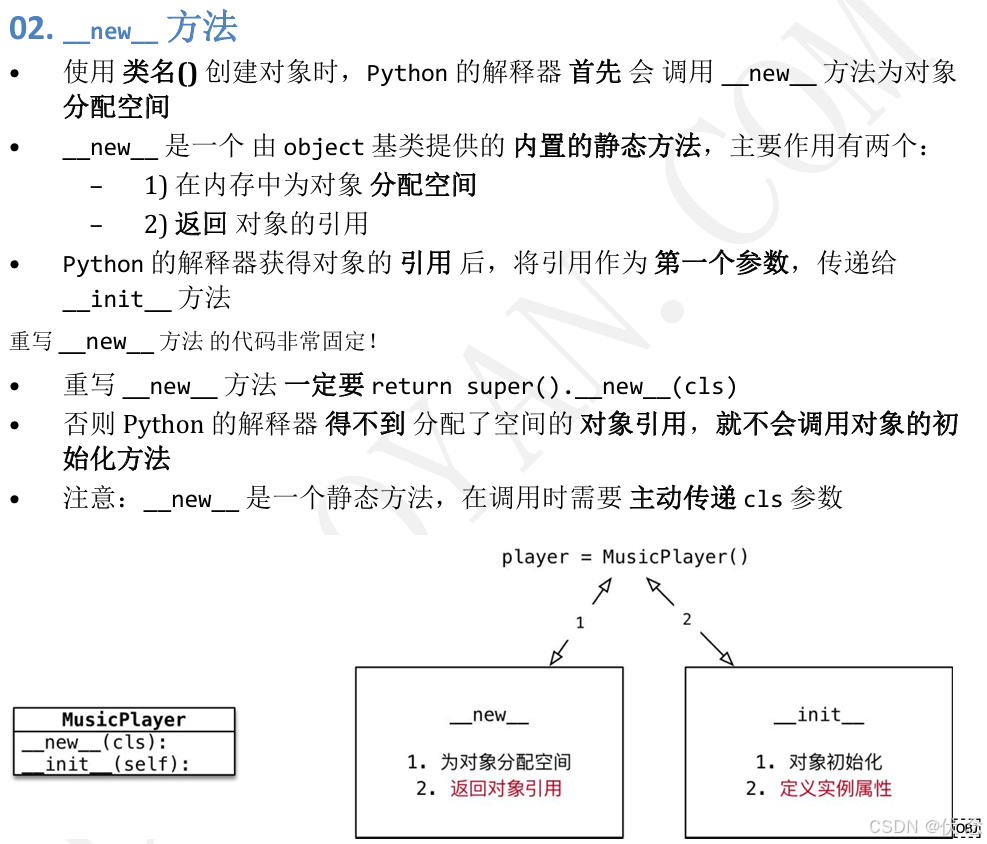
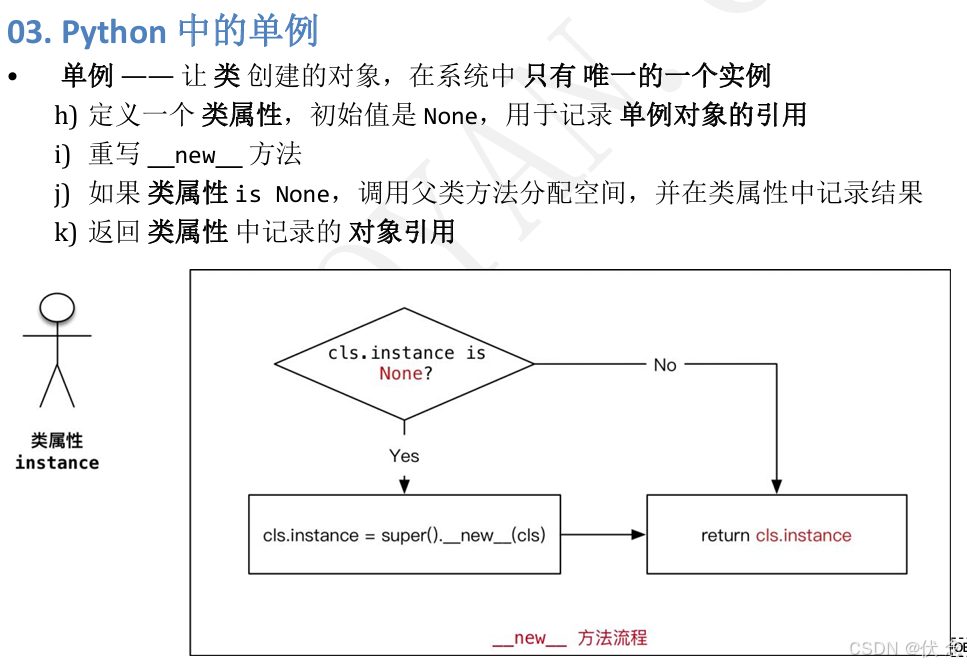
class MusicPlayer(object):
# 定义类属性记录单例对象引用
instance = None
def __new__(cls, *args, **kwargs):
# 1. 判断类属性是否已经被赋值
if cls.instance is None:
cls.instance = super().__new__(cls)
# 2. 返回类属性的单例引用
return cls.instance

class MusicPlayer(object):
# 记录第一个被创建对象的引用
instance = None
# 记录是否执行过初始化动作
init_flag = False
def __new__(cls, *args, **kwargs):
# 1. 判断类属性是否是空对象
if cls.instance is None:
# 2. 调用父类的方法,为第一个对象分配空间
cls.instance = super().__new__(cls)
# 3. 返回类属性保存的对象引用
return cls.instance
def __init__(self):
if not MusicPlayer.init_flag:
print("初始化音乐播放器")
MusicPlayer.init_flag = True
# 创建多个对象
player1 = MusicPlayer()
print(player1)
player2 = MusicPlayer()
print(player2)
初始化播放器
<__main__.MusicPlayer object at 0x0000019FB46CDB70>
<__main__.MusicPlayer object at 0x0000019FB46CDB70>
8.2工厂模式
9异常
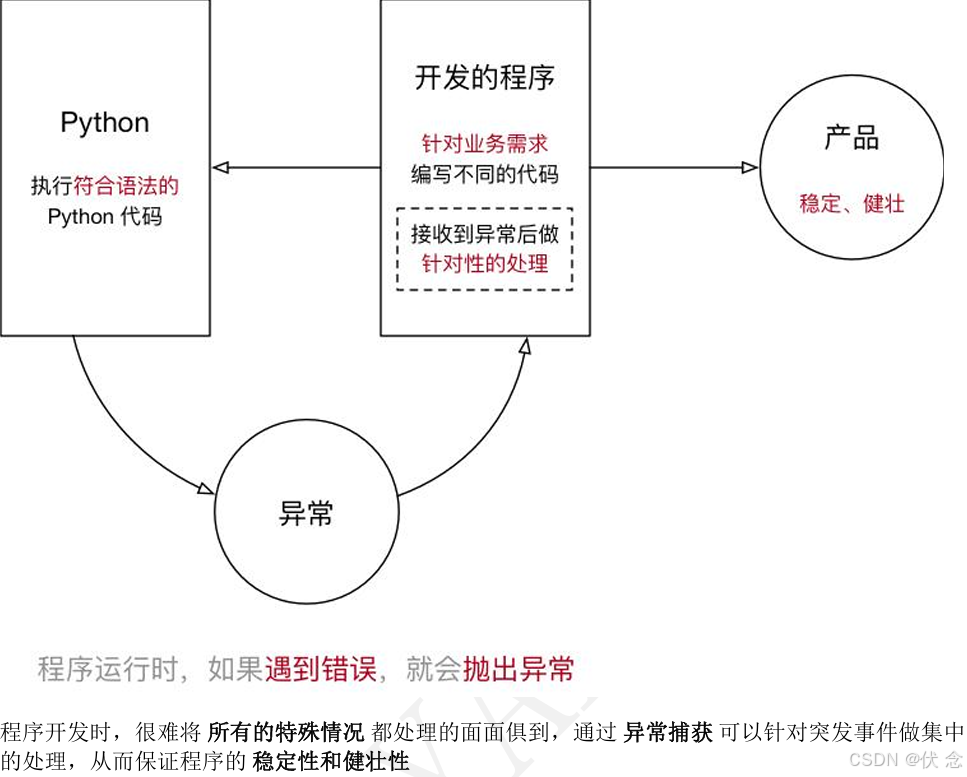
9.1异常的概念
程序在运行时,如果Python 解释器遇到到一个错误,会停止进程的执行,并且提示一些错误信息,这就是异常
程序停止执行并且提示错误信息这个动作,我们通常称之为:抛出(raise)异常
9.2捕获异常



捕获异常完整语法


9.3异常的传递

9.4 抛出raise异常


让自定义异常像通用异常一样使用
https://python3-cookbook.readthedocs.io/zh_CN/latest/c14/p08_creating_custom_exceptions.html
9.5常见异常汇总

10模块和包
10.1模块
10.1.1模块的概念
模块是Python程序架构的一个核心概念
• 每一个以扩展名py结尾的Python源代码文件都是一个模块
• 模块名同样也是一个标识符,需要符合标识符的命名规则
• 在模块中定义的全局变量、函数、类都是提供给外界直接使用的工具
• 模块就好比是工具包,要想使用这个工具包中的工具,就需要先导入这个模块
10.1.2模块的两种导入方式
1)import 导入
import 模块名1, 模块名2
提示:在导入模块时,每个导入应该独占一行
import 模块名1
import 模块名2
导入之后– 通过模块名.使用模块提供的工具——全局变量、函数、类
使用as指定模块的别名
import 模块名1 as 模块别名
如果模块的名字太长,可以使用as指定模块的名称,以方便在代码中的使用
注意:模块别名应该符合大驼峰命名法
2)from…import 导入
• 如果希望从某一个模块中,导入部分工具,就可以使用from … import的方式
• import 模块名是一次性把模块中所有工具全部导入,并且通过模块名/别名访问
从 模块 导入 某一个工具
from 模块名1 import 工具名
• 导入之后不需要通过模块名.
可以直接使用模块提供的工具——全局变量、函数、类
注意
如果两个模块,存在同名的函数,那么后导入模块的函数,会覆盖掉先导入的函数
• 开发时import代码应该统一写在代码的顶部,更容易及时发现冲突
• 一旦发现冲突,可以使用as关键字给其中一个工具起一个别名
from…import *(知道)
从 模块 导入 所有工具
from 模块名1 import *
注意 这种方式不推荐使用,因为函数重名并没有任何的提示,出现问题不好排查
10.1.3模块的搜索顺序[扩展]
Python 的解释器在导入模块时,会:
1 搜索当前目录指定模块名的文件,如果有就直接导入
2 如果没有,再搜索系统目录
在开发时,给文件起名,不要和系统的模块文件重名
Python 中每一个模块都有一个内置属性__file__可以查看模块的完整路径
10.1.4 原则——每一个文件都应该是可以被导入的
• 一个独立的Python文件就是一个模块
• 在导入文件时,文件中所有没有任何缩进的代码都会被执行一遍!
实际开发场景
• 在实际开发中,每一个模块都是独立开发的,大多都有专人负责
• 开发人员通常会在模块下方增加一些测试代码– 仅在模块内使用,而被导入到其他文件中不需要执行

10.2包(Package)
概念
• 目录下有一个特殊的文件__init__.py
• 包是一个包含多个模块的特殊目录
• 包名的命名方式和变量名一致,小写字母+_
好处
• 使用import 包名可以一次性导入包中所有的模块

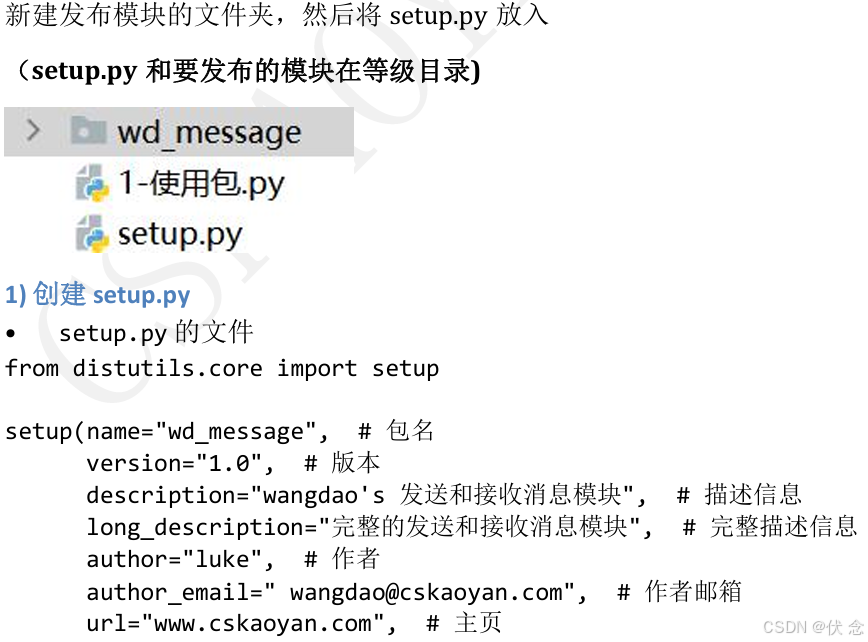
10.3 发布模块(知道
如果希望自己开发的模块,分享给其他人,可以按照以下步骤操作
10.3.1 制作发布压缩包步骤

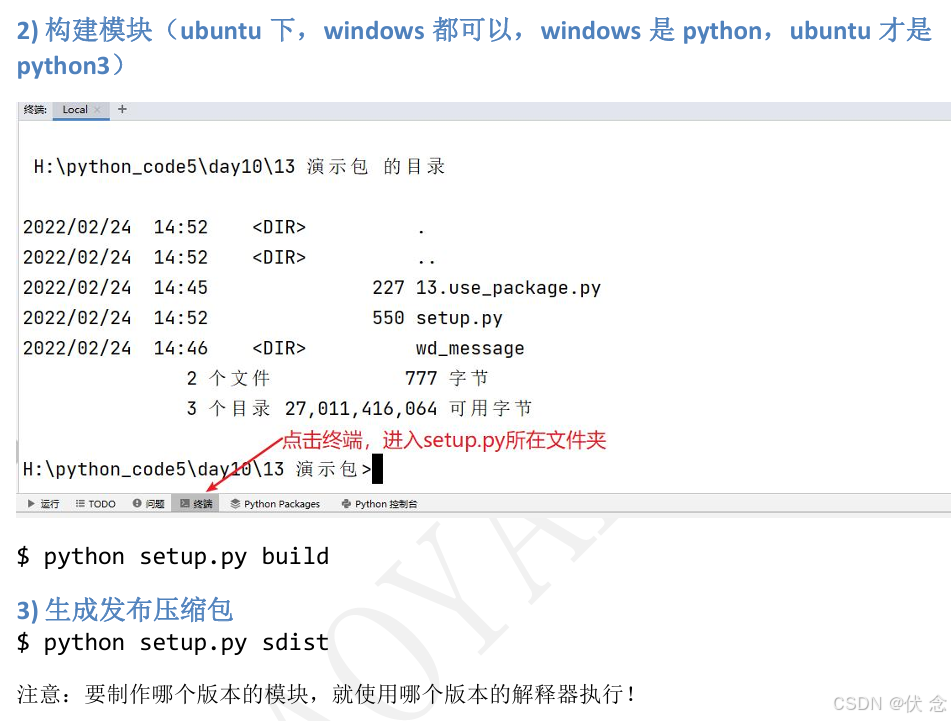

11文件
11.1 操作文件的函数/方法
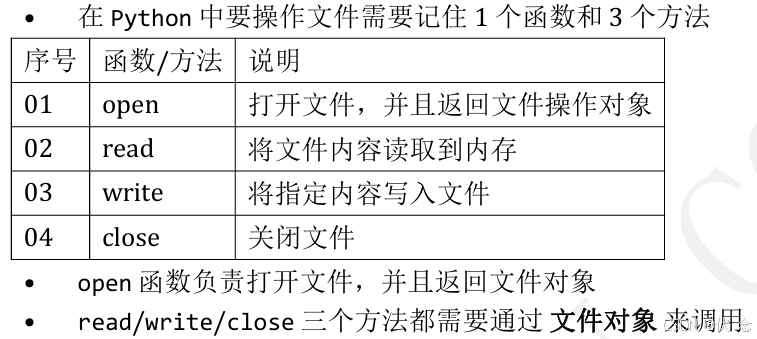
11.2 read 方法——读取文件

在开发中,通常会先编写打开和关闭的代码,再编写中间针对文件的读/写操作!file.read(size),size 参数代表要读取的文件内容大小

11.3打开文件的方式

提示
• 频繁的移动文件指针,会影响文件的读写效率,开发中更多的时候会以只读、只写的方式来操作文件
11.4按行读取文件内容

注:readline(limit) limit 参数代表要读取的文件内容大小
11.5 采用w和wb模式(wb是二进制模式)差异 ---- seek 的使用

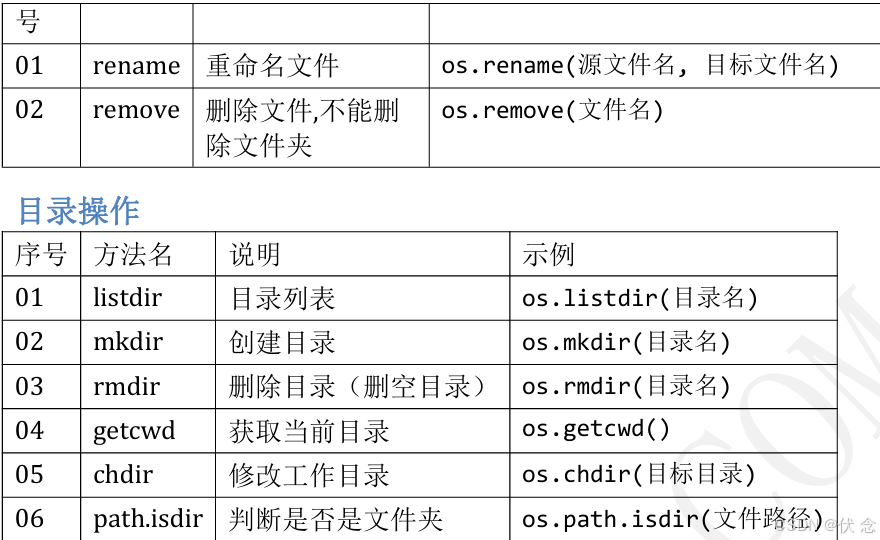
11.6 文件/目录的常用管理操作
在终端/文件浏览器、中可以执行常规的文件/目录管理操作,例如:– 创建、重命名、删除、改变路径、查看目录内容、……
• 在Python中,如果希望通过程序实现上述功能,需要导入os模块
Python 如何传递参数
11.7文本文件的编码格式(科普)
文本文件存储的内容是基于字符编码的文件,常见的编码有ASCII编码,UNICODE 编码等
Python 3.x 默认使用UTF-8编码格式(ubuntu打开文件默认是utf8,windows打开默认是GBK)
ASCII 编码
• 计算机中只有256个ASCII字符
• 一个ASCII在内存中占用1个字节的空间– 8个0/1的排列组合方式一共有256种,也就是2 ** 8
UTF-8 编码格式
• 大多数汉字会使用3个字节表示
• 计算机中使用1~6个字节来表示一个UTF-8字符,涵盖了地球上几乎所有地区的文字
• UTF-8是UNICODE编码的一种编码格式
高级
12网络与网络编程
12.1udp,tcp较简单
12.2epoll

13进程
13.1进程
创建-multiprocessing

获取进程pid
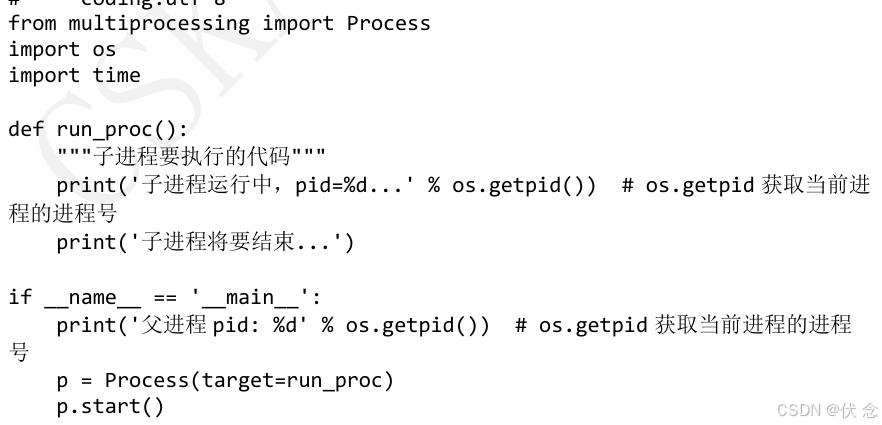
Process 语法结构

13.2进程间通信-Queue
Process 之间有时需要通信,操作系统提供了很多机制来实现进程间的通信。–还有管道,共享内存,信号量(pv)
Queue 的使用
from multiprocessing import Process, Queue
可以使用multiprocessing 模块的Queue 实现多进程之间的数据传递,Queue 本身是一个消息列队程序,

13.3 进程池Pool
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing 模块提供的Pool 方法。
初始化Pool 时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务
from multiprocessing.pool import Pool

进程池中的Queue
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
from multiprocessing import Manager,Pool
通过进程池来来实现百度网盘apply_async派发的任务必须是一个纯函数,不能是对象里的方法!
13.4管道通信(不重要,使用起来不方便,直接跳过)

14线程
14.1创建
python 的 thread 模块是比较底层的模块,python的threading 模块是对 thread 做了一些包装的,可以更加方便的被使用
t = threading.Thread(target=saySorry)
t.start() #启动线程,即让线程开始执行
说明
1.可以明显看出使用了多线程并发(GIL锁)的操作,花费时间要短很多
2.当调用start()时,才会真正的创建线程,并且开始执行
查看线程数量
length = len(threading.enumerate())
print(threading.active_count())
优点:启动速度快,上下文切换的速度快
缺点:线程任何一个挂掉,整个进程都会结束(Python一个线程崩溃,其他的线程是正常的)
14.2 GIL锁(全局解释器锁)

GIL 面试题如下
描述Python GIL 的概念,以及它对python多线程的影响?编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因。
Guido 的声明:
http://www.artima.com/forums/flat.jsp?forum=106&thread=214235
he language doesn’t require the GIL-- it’s only the CPython virtual machine that has
historically been unable to shed it.
参考答案:
1.Python 语言和GIL 没有半毛钱关系。仅仅是由于历史原因在Cpython虚拟机(解释器),难以移除GIL。
2.GIL:全局解释器锁。每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程可以执行代码。
3.线程释放GIL锁的情况:在IO操作等可能会引起阻塞的system call之前,可以暂时释放GIL,但在执行完毕后,必须重新获取GILPython3.x使用计时器(执行时间达到阈值后,当前线程释放GIL)或 Python2.x,tickets 计数达到 100
4.Python 使用多进程是可以利用多核的CPU资源的。
5.多线程爬取比单线程性能有提升,因为遇到IO阻塞会自动释放GIL锁
14.3 线程执行代码的封装
通过使用threading模块能完成多任务的程序开发,为了让每个线程的封装性更完美,所以使用threading模块时,往往会定义一个新的子类class,只要继承threading.Thread就可以了,然后重写run方法
#coding=utf-8
import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm "+self.name+' @ '+str(i) #name属性中保存的是当前线程的名字
print(msg)
if __name__ == '__main__':
t = MyThread()
t.start()
python的threading.Thread 类有一个run方法,用于定义线程的功能函数,可以在自己的线程类中覆盖该方法。而创建自己的线程实例后,通过Thread类的start方法,可以启动该线程,交给python虚拟机进行调度,当该线程获得执行的机会时,就会调用run方法执行线程。
多线程程序的执行顺序是不确定的。
总结
1.每个线程默认有一个名字,尽管上面的例子中没有指定线程对象的name,但是python 会自动为线程指定一个名字。
2.当线程的run()方法结束时该线程完成。
3.无法控制线程调度程序,但可以通过别的方式来影响线程调度的方式。
14.4 多线程问题、同步、互斥、死锁
14.4.1多线程共享全局变量
在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据
• 缺点就是,线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程非安全)
如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确
14.4.2同步
同步就是协同步调,按预定的先后次序进行运行。
如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B执行,再将结果给A;A再继续操作。
14.4.3互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。

总结
锁的好处:
• 确保了某段关键代码只能由一个线程从头到尾完整地执行
锁的坏处:
• 阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了
• 由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁
14.4.4死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
避免死锁
• 程序设计时要尽量避免(银行家算法)
• 添加超时时间等
15协程
15.1迭代器
迭代是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
迭代器只能往前不会后退。
15.1.1可迭代对象
我们已经知道可以对list、tuple、str 等类型的数据使用for .in .的循环语法从其中依次拿到数据进行使用,我们把这样的过程称为遍历,也叫迭代。
但是,是否所有的数据类型都可以放到for…in…的语句中,然后让for…in…每次从中取出一条数据供我们使用,即供我们迭代吗?
我们自定义了一个容器类型MyList,在将一个存放了多个数据的MyList对象放到for .in .的语句中,发现for .in .并不能从中依次取出一条数据返回给我们,也就说我们随便封装了一个可以存放多条数据的类型却并不能被迭代使用。
我们把可以通过for…in…这类语句迭代读取一条数据供我们使用的对象称之为可迭代对象(Iterable)
15.1.2如何判断一个对象是否可以迭代
可以使用isinstance()判断一个对象是否是Iterable对象:
In [50]: from collections.abc import Iterable
In [51]: isinstance([], Iterable)
Out[51]: True
In [52]: isinstance({}, Iterable)
Out[52]: True
In [53]: isinstance('abc', Iterable)
Out[53]: True
In [54]: isinstance(mylist, Iterable)
Out[54]: False
In [55]: isinstance(100, Iterable)
Out[55]: False
15.1.3可迭代对象的本质
我们分析对可迭代对象进行迭代使用的过程,发现每迭代一次(即在for .in .中每循环一次)都会返回对象中的下一条数据,一直向后读取数据直到迭代了所有数据后结束。那么,在这个过程中就应该有一个“人”去记录每次访问到了第几条数据,以便每次迭代都可以返回下一条数据。我们把这个能帮助我们进行数据迭代的“人”称为迭代器(Iterator)。
可迭代对象的本质就是可以向我们提供一个这样的中间“人”即迭代器帮助我们对其进行迭代遍历使用。
可迭代对象通过__iter__方法向我们提供一个迭代器,我们在迭代一个可迭代对象的时候,实际上就是先获取该对象提供的一个迭代器,然后通过这个迭代器来依次获取对象中的每一个数据.
那么也就是说,一个具备了__iter__方法的对象,就是一个可迭代对象。
15.1.4 iter()函数与 next()函数
list、tuple 等都是可迭代对象,我们可以通过iter()函数获取这些可迭代对象的迭代器。然后我们可以对获取到的迭代器不断使用next()函数来获取下一条数据。
iter()函数实际上就是调用了可迭代对象的__iter__方法。

15.1.5 如何判断一个对象是否是迭代器
可以使用isinstance()判断一个对象是否是Iterator对象:
In [56]: from collections import Iterator
In [57]: isinstance([], Iterator)
Out[57]: False
In [58]: isinstance(iter([]), Iterator)
Out[58]: True
In [59]: isinstance(iter("abc"), Iterator)
Out[59]: True
15.1.6 迭代器Iterator
通过上面的分析,我们已经知道,迭代器是用来帮助我们记录每次迭代访问到的位置,当我们对迭代器使用next()函数的时候,迭代器会向我们返回它所记录位置的下一个位置的数据。实际上,在使用next()函数的时候,调用的就是迭代器对象的__next__方法(Python3 中是对象的__next__方法)。
所以,我们要想构造一个迭代器,就要实现它的__next__方法。但这还不够,python要求迭代器本身也是可迭代的,所以我们还要为迭代器实现__iter__方法,而__iter__方法要返回一个迭代器,迭代器自身正是一个迭代器,所以迭代器的__iter__方法返回自身即可。
一个实现了__iter__方法和__next__方法的对象,就是迭代器。
#coding=utf-8
from collections.abc import Iterator
class MyList(object):
"""自定义的一个可迭代对象"""
def __init__(self):
self.items = []
def add(self, val):
self.items.append(val)
def __iter__(self):
myiterator = MyIterator(self)
return myiterator
class MyIterator(object):
"""自定义的供上面可迭代对象使用的一个迭代器"""
def __init__(self, mylist):
self.mylist = mylist
# current 用来记录当前访问到的位置
self.current = 0
def __next__(self):
if self.current < len(self.mylist.items):
item = self.mylist.items[self.current]
self.current += 1
return item
else:
raise StopIteration
def __iter__(self):
return self
if __name__ == '__main__':
mylist = MyList()
print(isinstance(mylist, Iterator))
mylist.add(1)
mylist.add(2)
mylist.add(3)
mylist.add(4)
mylist.add(5)
# print(next(mylist)) #为啥不行
for num in mylist:
print(num)
myIterator = MyIterator(mylist)
print(isinstance(myIterator, Iterator))
print(next(myIterator)) #打印结果是多少
# 输出
False
1
2
3
4
5
True
1
15.1.7 for…in…循环的本质
for item in Iterable 循环的本质就是先通过iter()函数获取可迭代对象Iterable 的迭代器,然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item,当遇到StopIteration 的异常后循环结束。
15.1.8 迭代器的应用场景
我们发现迭代器最核心的功能就是可以通过next()函数的调用来返回下一个数据值。如果每次返回的数据值不是在一个已有的数据集合中读取的,而是通过程序按照一定的规律计算生成的,那么也就意味着可以不用再依赖一个已有的数据集合,也就是说不用再将所有要迭代的数据都一次性缓存下来供后续依次读取,这样可以节省大量的存储(内存)空间。
举个例子,比如,数学中有个著名的斐波拉契数列(Fibonacci),数列中第一个数为0,第二个数为1,其后的每一个数都可由前两个数相加得到:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, .
现在我们想要通过for .in .循环来遍历迭代斐波那契数列中的前n个数。那么这个斐波那契数列我们就可以用迭代器来实现,每次迭代都通过数学计算来生成下一个数。

15.1.9 并不是只有for循环能接收可迭代对象
除了for 循环能接收可迭代对象,list、tuple 等也能接收。
li = list(FibIterator(15))
print(li)
tp = tuple(FibIterator(6))
print(tp)
15.2 生成器
利用迭代器,我们可以在每次迭代获取数据(通过next()方法)时按照特定的规律进行生成。但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一个数据。为了达到记录当前状态,并配合next()函数进行迭代使用,我们可以采用更简便的语法,即生成器(generator)。
生成器是一类特殊的迭代器。
15.2.1创建生成器方法1
要创建一个生成器,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成()
In [15]: L = [ x*2 for x in range(5)]
In [16]: L
Out[16]: [0, 2, 4, 6, 8]
In [17]: G = ( x*2 for x in range(5))
In [18]: G
Out[18]: <generator object <genexpr> at 0x7f626c132db0>
In [19]:
创建L和G的区别仅在于最外层的[]和(),L是一个列表,而G是一个生成器。
我们可以直接打印出列表L的每一个元素,而对于生成器G,我们可以按照迭代器的使用方法来使用,即可以通过next()函数、for循环、list()等方法使用。
15.2.2创建生成器方法2
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
我们仍然用上一节提到的斐波那契数列来举例,回想我们在上一节用迭代器的实现方式:
注意,在用迭代器实现的方式中,我们要借助几个变量(n、current、num1、num2)来保存迭代的状态。现在我们用生成器来实现一下。

在使用生成器实现的方式中,我们将原本在迭代器__next__方法中实现的基本逻辑放到一个函数中来实现,但是将每次迭代返回数值的return换成了yield,此时新定义的函数便不再是函数,而是一个生成器了。
简单来说:只要在def中有yield关键字的就称为生成器
此时按照调用函数的方式(案例中为F=fib(5))使用生成器就不再是执行函数体了,而是会返回一个生成器对象(案例中为F),然后就可以按照使用迭代器的方式来使用生成器了。

但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:

总结
• 使用了yield关键字的函数不再是函数,而是生成器。(使用了yield的函数就是生成器)
• yield 关键字有两点作用:
– 保存当前运行状态(断点),然后暂停执行,即将生成器(函数)挂起
– 将yield关键字后面表达式的值作为返回值返回,此时可以理解为起到了return 的作用
• 可以使用next()函数让生成器从断点处继续执行,即唤醒生成器(函数)
• Python3 中的生成器可以使用return 返回最终运行的返回值。
15.2.3使用send 唤醒
我们除了可以使用next()函数来唤醒生成器继续执行外,还可以使用send()函数来唤醒执行。使用send()函数的一个好处是可以在唤醒的同时向断点处传入一个附加数据。

15.2.4使用__next__()方法(不常使用)
In [18]: f = gen()
In [19]: f.__next__()
Out[19]: 0
In [20]: f.__next__()
None
Out[20]: 1
In [21]: f.__next__()
None
Out[21]: 2
In [22]: f.__next__()
None
Out[22]: 3
In [23]: f.__next__()
None
Out[23]: 4
15.3协程
15.3.1什么是协程
协程,又称微线程,纤程。英文名Coroutine。
协程是python 个中另外一种实现多任务的方式,只不过比线程更小占用更小执行单元(理解为需要的资源)。为啥说它是一个执行单元,因为它自带CPU上下文。这样只要在合适的时机,我们可以把一个协程切换到另一个协程。只要这个过程中保存或恢复CPU上下文那么程序还是可以运行的。
通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定
15.3.2协程和线程差异
在实现多任务时,线程切换从系统(内核)层面远不止保存和恢复CPU上下文这么简单。操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。所以线程的切换非常耗性能。但是协
程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
简单实现协程
import time
def work1():
while True:
print("----work1---")
yield
time.sleep(0.5)
def work2():
while True:
print("----work2---")
yield
time.sleep(0.5)
def main():
w1 = work1()
w2 = work2()
while True:
next(w1)
next(w2)
运行结果:
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
...省略...
配置pip.ini 文件
https://blog.csdn.net/sunyllove/article/details/81627281
C:\Users\Administrator\AppData\Roaming\pip
Win+r 快速打开运行窗口
输入%APPDATA%
升级pip
python -m pip install --upgrade pip
安装包的时候不要开启梯子,否则会造成超时
15.4 greenlet
为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单
windows 下安装
pip install greenlet
验证是否安装成功
pip list|grep greenlet
Ubuntu 下使用如下命令安装greenlet 模块:
#coding=utf-8
pip3 install greenlet

15.5 gevent
greenlet 已经实现了协程,但是这个还的人工切换,是不是觉得太麻烦了,不要捉急,python 还有一个比greenlet 更强大的并且能够自动切换任务的模块gevent
其原理是当一个greenlet 遇到IO(指的是inputoutput输入输出,比如网络、文件操作等)操作时,比如访问网络阻塞,就自动切换到其他的协程,等到IO操作完成,再在适当的时候切换回来继续执行。
由于I/O 操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有协程在运行,而不是等待I/O
15.5.1安装
在Linux(ubuntu)
pip3 install gevent
在Windows 的Pycharm 输入了importgevent 后,直接点击红色小灯泡进行安装即可
pip install gevent
15.5.2 gevent 的使用方法
gevent.spawn 接口使用方法,gevent.spawn(函数名,传参)
import gevent
import time
def f(n):
for i in range(n):
print(gevent.getcurrent(), i)
#用来模拟耗时操作
gevent.sleep(0.5)
g1 = gevent.spawn(f, 5)
g2 = gevent.spawn(f, 5)
g3 = gevent.spawn(f, 5)
g1.join()
g2.join()
g3.join()
运行结果
<Greenlet at 0x237af48b880: f(5)> 0
<Greenlet at 0x237d0aadbc0: f(5)> 0
<Greenlet at 0x237d0934180: f(5)> 0
<Greenlet at 0x237af48b880: f(5)> 1
<Greenlet at 0x237d0aadbc0: f(5)> 1
<Greenlet at 0x237d0934180: f(5)> 1
<Greenlet at 0x237af48b880: f(5)> 2
<Greenlet at 0x237d0aadbc0: f(5)> 2
<Greenlet at 0x237d0934180: f(5)> 2
<Greenlet at 0x237af48b880: f(5)> 3
<Greenlet at 0x237d0aadbc0: f(5)> 3
<Greenlet at 0x237d0934180: f(5)> 3
<Greenlet at 0x237af48b880: f(5)> 4
<Greenlet at 0x237d0aadbc0: f(5)> 4
<Greenlet at 0x237d0934180: f(5)> 4
15.5.3 给程序打补丁


猴子补丁作用
monkey patch 指的是在执行时动态替换,通常是在startup的时候.
用过gevent就会知道,会在最开头的地方gevent.monkey.patch_all();把标准库中的thread/socket等给替换掉.这样我们在后面使用socket的时候能够跟寻常一样使用,不论什么代码无需改动,可是它变成非堵塞的了.
之前做的一个游戏server,非常多地方用的import json,后来发现ujson 比自带json快了N倍,于是问题来了,难道几十个文件要一个个把import json 改成import ujson as json吗?
事实上仅仅须要在进程startup的地方monkey patch即可了.是影响整个进程空间的.
直接参考以下实例,采用协程访问三个网站
由于IO操作非常耗时,程序经常会处于等待状态
比如请求多个网页有时候需要等待,gevent可以自动切换协程
遇到阻塞自动切换协程,程序启动时执行monkey.patch_all()解决
15.6 进程、线程、协程对比
请仔细理解如下的通俗描述
有一个老板想要开个工厂进行生产某件商品(例如剪子),他需要花一些财力物力制作一条生产线,这个生产线上有很多的器件以及材料这些所有的为了能够生产剪子而准备的资源称之为:进程
• 只有生产线是不能够进行生产的,所以老板的找个工人来进行生产,这个工人能够利用这些材料最终一步步的将剪子做出来,这个来做事情的工人称之为:线程
• 这个老板为了提高生产率,想到3种办法:
a.在这条生产线上多招些工人,一起来做剪子,这样效率是成倍増长,即单进程多线程方式
b.老板发现这条生产线上的工人不是越多越好,因为一条生产线的资源以及材料毕竟有限,所以老板又花了些财力物力购置了另外一条生产线,然后再招些工人这样效率又再一步提高了,即多进程多线程方式
c.老板发现,现在已经有了很多条生产线,并且每条生产线上已经有很多工人了(即程序是多进程的,每个进程中又有多个线程),为了再次提高效率,老板想了个损招,规定:如果某个员工在上班时临时没事或者再等待某些条件(比如等待另一个工人生产完谋道工序之后他才能再次工作),那么这个员工就利用这个时间去做其它的事情,那么也就是说:如果一个线程等待某些条件,可以充分利用这个时间去做其它事情,其实这就是:协程方式
简单总结
1.进程是资源分配的单位
2.线程是操作系统内核调度的基本单位
3.进程切换需要的资源很最大,效率很低(getcwd)
4.线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
5.协程切换任务资源很小,效率高
6.多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中,所以是并发
gevent常用方法:
gevent.spawn() 创建一个普通的Greenlet对象并切换
gevent.spawn_later(seconds=3) 延时创建一个普通的Greenlet对象并切换
gevent.spawn_raw() 创建的协程对象属于一个组
gevent.getcurrent() 返回当前正在执行的greenlet
gevent.joinall(jobs) 将协程任务添加到事件循环,接收一个任务列表
gevent.wait() 可以替代join函数等待循环结束,也可以传入协程对象列表
gevent.kill() 杀死一个协程
gevent.killall() 杀死一个协程列表里的所有协程
monkey.patch_all() 非常重要,会自动将python的一些标准模块替换成gevent框架
https://blog.csdn.net/biheyu828/article/details/86593413
python 最新接口
异步IO
在官网中直接搜索asyncio 异步IO(了解,商业化目前还不流行)
https://blog.csdn.net/weixin_42146296/article/details/92166245
15.7 并发下载器
from gevent import monkey
import gevent
import requests #(默认自带的爬虫库)
# 有耗时操作时需要
monkey.patch_all()
def my_downLoad(url):
print('GET: %s' % url)
response = requests.get(url)
data = response.text
print('%d bytes received from %s.' % (len(data), url))
if __name__ == '__main__':
gevent.joinall([
gevent.spawn(my_downLoad, 'http://www.baidu.com/'),
gevent.spawn(my_downLoad, 'http://www.cskaoyan.com/'),
gevent.spawn(my_downLoad, 'http://www.lgwenda.com/'),
])
运行结果
GET: http://www.baidu.com/
GET: http://www.cskaoyan.com/
GET: http://www.lgwenda.com/
507534 bytes received from http://www.baidu.com/.
45570 bytes received from http://www.cskaoyan.com/.
2765 bytes received from http://www.lgwenda.com/.
15.8 最新Python 自带的协程
示例:使用 asyncio 的异步 I/O 操作


15.9 asyncio 与 gevent 对比
asyncio 和 gevent 都是用于异步编程的库,但它们在设计和实现上有一些显著的不同,这影响了它们在不同场景中的效率和适用性。以下是对asyncio和gevent的详细比较,以帮助理解它们在不同环境中的效率和适用性。
asyncio
优点:
- 标准库支持:
asyncio是Python标准库的一部分,从Python3.4开始可用,因此无需额外安装第三方库。 - 丰富的生态系统:许多现代Python框架和库(如
aiohttp、Sanic、FastAPI等)都基于asyncio,提供了广泛的支持和集成。 - 跨平台支持:
asyncio在所有支持Python的平台上都能正常工作,包括Windows、Linux和macOS。 - 多样化的调度器:在Python3.7及以上版本中,
asyncio提供了多种调度器(如ProactorEventLoop和SelectorEventLoop),可以在不同操作系统上进行优化。
缺点: - 学习曲线:
asyncio的编程模型(基于协程和事件循环)对一些开发者来说可能比较复杂。 - 性能开销:在某些情况下,
asyncio的性能可能不如gevent,特别是在处理非常大量的小型任务时。
gevent
优点: - 绿色线程(微线程):
gevent使用绿色线程(基于libev或libuv),可以高效地调度大量小任务。 - 简单的并发模型:
gevent通过猴子补丁(monkeypatching)将同步代码转换为异步代码,使得编写和理解代码更加简单直观。 - 高效的I/O操作:对于I/O密集型任务,
gevent通常表现出色,因为它的绿色线程切换成本低。
缺点: - 依赖猴子补丁:
gevent依赖于猴子补丁,这可能导致与其他库的兼容性问题。 - 非标准库:需要额外安装,并且一些Python环境可能不完全支持(如某些特定的嵌入式系统)。
- 跨平台限制:虽然
gevent支持多个操作系统,但在某些平台上的支持可能不如asyncio那么全面。
性能对比
具体性能对比取决于具体的应用场景和任务类型。以下是一些常见场景中的对比: - I/O 密集型任务:- gevent 通常在处理大量I/O密集型任务时表现更好,特别是当这些任务都是相对小的网络请求或文件读取操作。- asyncio 也非常适合处理I/O密集型任务,但在一些基准测试中,
gevent的性能略胜一筹。 - CPU 密集型任务:- gevent 和 asyncio 都不适合直接处理CPU密集型任务,因为它们都是协作式调度的异步模型,无法有效利用多核CPU。对于CPU密集型任务,应该使用多进程或多线程模型。-
asyncio可以与concurrent.futures结合使用,通过ThreadPoolExecutor或ProcessPoolExecutor来处理 CPU 密集型任务。 - 任务数量和切换开销:- gevent 的绿色线程切换开销通常较低,适合处理大量小任务。- asyncio 在处理非常大量的小任务时,任务调度和上下文切换的开销可能略高。
结论
- 如果需要与其他现代Python异步库和框架进行集成,或者希望使用标准库并获得跨平台支持,
asyncio是一个更好的选择。- 如果需要处理大量小型I/O任务,并且希望简化代码编写,gevent可能会更高效。
具体选择应根据项目的需求和环境来决定。
16正则表达式
16.1re 模块操作
在Python 中需要通过正则表达式对字符串进行匹配的时候,可以使用一个模块,名字为re
re 模块的使用过程

re.match()能够匹配出以xxx 开头的字符串
16.2匹配格式
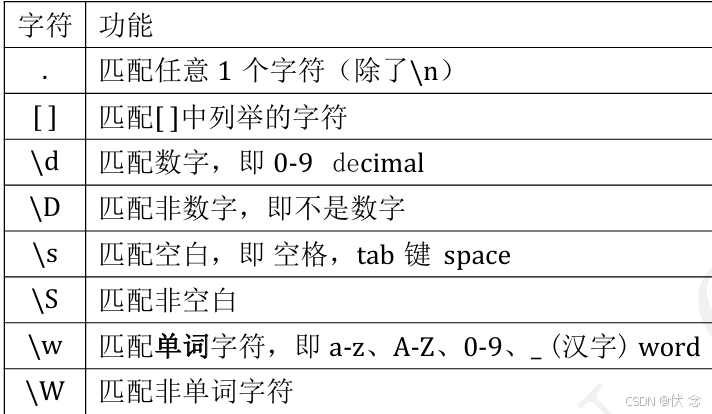
匹配单个字符
匹配多个字符

匹配开头结尾

匹配分组

16.3 re 模块的高级用法
search(只能搜第一个)

findall

sub 将匹配到的数据进行替换


split 根据匹配进行切割字符串,并返回一个列表

16.4 python 贪婪和非贪婪
Python 里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;
非贪婪则相反,总是尝试匹配尽可能少的字符。在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。

16.5 r 的作用

Python 中字符串前面加上 r 表示原生字符串,与大多数编程语言相同,正则表达式里使用"“作为转义字符,这就可能造成反斜杠
困扰。假如你需要匹配文本中的字符”",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python 里的原生字符串很好地解决了这个问题,有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
r 只服务于\,不对其他进行转义
16.6 正则的选项
re.A 不让\w 匹配汉字
re.I 是否区分大小写
re.S re.S 可以匹配
16.7 练手网站
https://regexone.com/
https://regexlearn.com/zh-cn/learn
17高级
17.1深拷贝、浅拷贝
浅拷贝是对于一个对象的顶层拷贝
通俗的理解是:拷贝了引用,并没有拷贝内容(浅copy不是直接赋值)
深拷贝是对于一个对象所有层次的拷贝(递归)
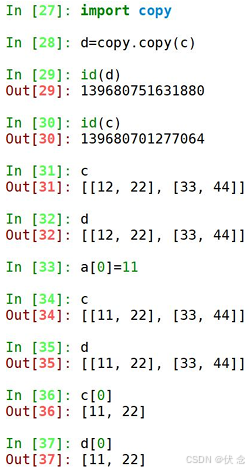
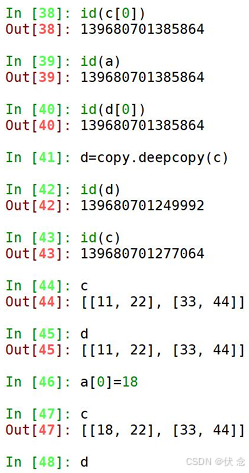
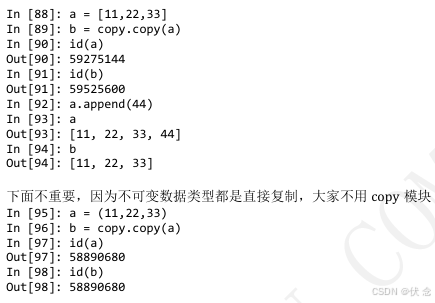
拷贝的其他方式
• 字典的copy方法可以拷贝一个字典

浅拷贝对不可变类型和可变类型的copy不同
1.copy.copy 对于可变类型,会进行浅拷贝
2.copy.copy 对于不可变类型,不会拷贝,仅仅是指向
17.2私有化
xx:公有变量
• _x:单前置下划线,私有化属性或方法,在类外面不能联想对应的属性,或者方法
• _xx:双前置下划线,避免与子类中的属性命名冲突,无法在外部直接访问(名字重整所以访问不到),子类不能访问父类的私有属性和方法,两个下划线的
• xx:双前后下划线,用户名字空间的魔法对象或属性。例如:init,不要自己发明这样的名字
• xx:单后置下划线,用于避免与Python关键词的冲突
通过namemangling(名字重整(目的就是以防子类意外重写基类的方法或者属性)如:_Class__object)机制就可以访问private 了。
父类中属性名为__名字的,子类不继承,子类不能访问
如果在子类中向__名字赋值,那么会在子类中定义的一个与父类相同名字的属性
17.3import 导入模块
17.3.1 import 搜索路径
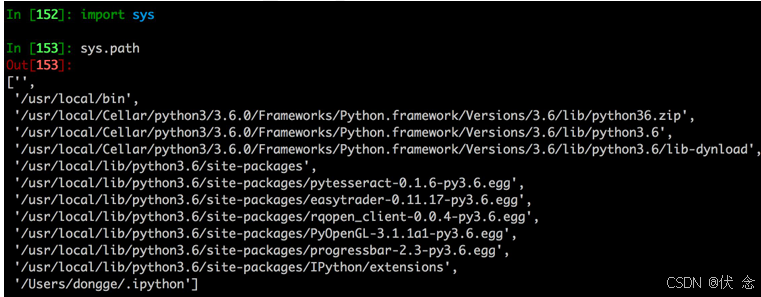
路径搜索
从上面列出的目录里依次查找要导入的模块文件
''表示当前路径
列表中的路径的先后顺序代表了python解释器在搜索模块时的先后顺序
程序执行时添加新的模块路径
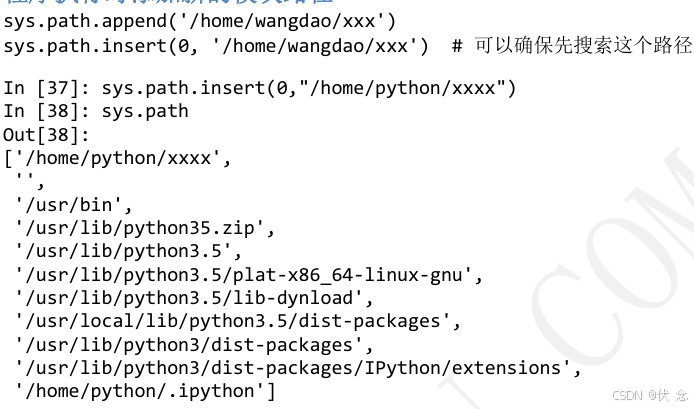
17.3.2 重新导入模块
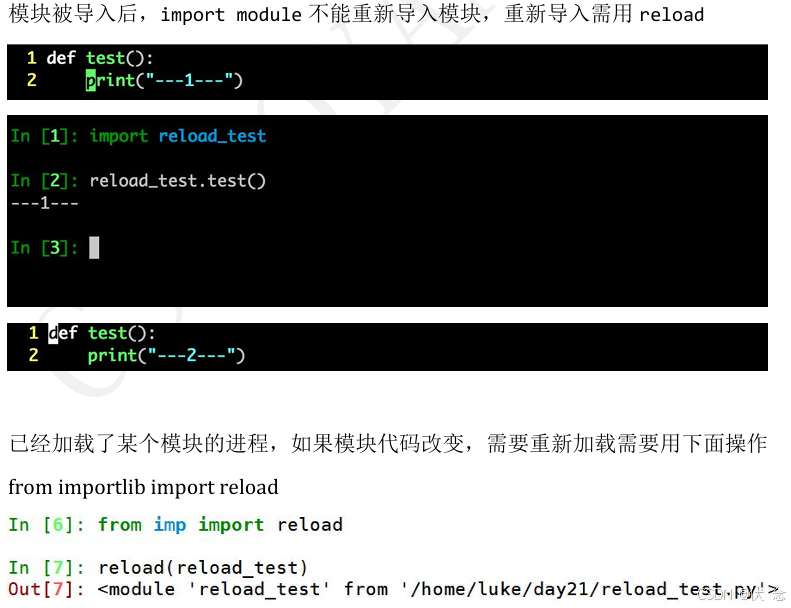
17.4 多模块开发时的注意点
对于其他文件的不可变类型, from common import HANDLE_FLAG导入时,相当于新建全局变量
此时若想修改应 import common
18 property 属性
18.1 什么是property属性
一种用起来像是使用的实例属性一样的特殊属性,可以对应于某个方法
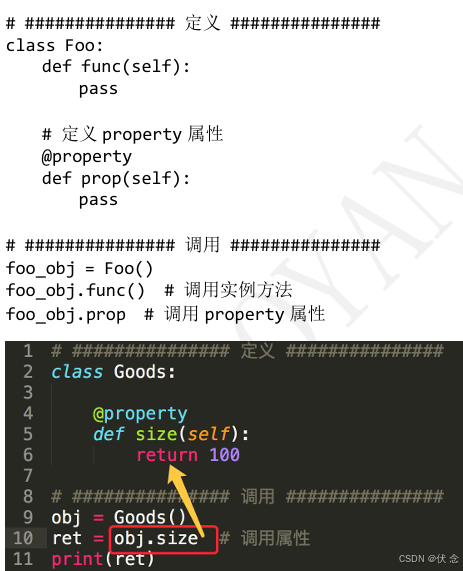
property 属性的定义和调用要注意一下几点:
• 定义时,在实例方法的基础上添加 @property 装饰器;并且仅有一个self参数
• 调用时,无需括号
方法:foo_obj.func()
property 属性:foo_obj.prop
Python的property属性的功能是:property属性内部进行一系列的逻辑计算,最终将计算结果返回。
18.2 property 属性的有两种方式
装饰器 即:在方法上应用装饰器
类属性 即:在类中定义值为property对象的类属性
18.2.1装饰器方式
在类的实例方法上应用@property装饰器
经典类,具有一种@property装饰器

具有三种@property装饰器
class Goods:
@property
def price(self):
print('@property')
@price.setter
def price(self, value):
print('@price.setter')
@price.deleter
def price(self):
print('@price.deleter')
obj = Goods()
obj.price
# 自动执行 @property 修饰的 price 方法,并获取方法的返回值
obj.price = 123 # 自动执行 @price.setter 修饰的 price 方法,并将 123 赋值给方法的参数
del obj.price # 自动执行 @price.deleter 修饰的 price 方法
属性有三种访问方式,并分别对应了三个被@property、@方法名.setter、@方法名.deleter 修饰的方法
由于新式类中具有三种访问方式,我们可以根据它们几个属性的访问特点,分别将三个方法定义为对同一个属性:获取、修改、删除
18.2.2 类属性方式,创建值为property对象的类属性
当使用类属性的方式创建property属性时,经典类和新式类无区别

property 方法中有个四个参数
• 第一个参数是方法名,调用 对象.属性 时自动触发执行方法
• 第二个参数是方法名,调用 对象.属性 = XXX 时自动触发执行方法
• 第三个参数是方法名,调用 del 对象.属性 时自动触发执行方法
• 第四个参数是字符串,调用 类名.属性.doc ,此参数是该属性的描述信息

18.3 property 属性-应用
- 私有属性添加getter和setter方法
- 使用property 升级getter和setter 方法
- 使用property 取代getter和setter 方法
19.魔法属性
无论人或事物往往都有不按套路出牌的情况,Python的类属性也是如此,存在着一些具有特殊含义的属性,详情如下:





20 with 与“上下文管理器”
20.1with引入
如果你有阅读源码的习惯,可能会看到一些优秀的代码经常出现带有 “with” 关键字的语句,它通常用在什么场景呢?对于系统资源如文件、数据库连接、socket而言,应用程序打开这些资源并执行完业务逻辑之后,必须做的一件事就是要关闭(断开)该资源。
比如 Python 程序打开一个文件,往文件中写内容,写完之后,就要关闭该文件,否则会出现什么情况呢?极端情况下会出现 “Toomanyopenfiles” 的错误,因为系统允许你打开的最大文件数量是有限的。
同样,对于数据库,如果连接数过多而没有及时关闭的话,就可能会出现 “Can not connect to MySQL server Too manyconnections”,因为数据库连接是一种非常昂贵的资源,不可能无限制的被创建。
来看看如何正确关闭一个文件。
普通版
def m1():
f = open("output.txt", "w")
f.write("python 之禅")
f.close()
这样写有一个潜在的问题,如果在调用 write 的过程中,出现了异常进而导致后续代码无法继续执行,close 方法无法被正常调用,因此资源就会一直被该程序占用者释放。那么该如何改进代码呢?
进阶版
def m2():
f = open("output.txt", "w")
try:
f.write("python 之禅")
except IOError:
print("oops error")
finally:
f.close()
改良版本的程序是对可能发生异常的代码处进行 try 捕获,使用 try/finally 语句,该语句表示如果在 try 代码块中程序出现了异常,后续代码就不再执行,而直接跳转到 except 代码块。而无论如何,finally 块的代码最终都会被执行。因此,只要把 close 放在 finally 代码中,文件就一定会关闭。
高级版
def m3():
with open("output.txt", "r") as f:
f.write("Python 之禅")
一种更加简洁、优雅的方式就是用 with 关键字。open 方法的返回值赋值给变量f,当离开 with 代码块的时候,系统会自动调用 f.close() 方法, with 的作用和使用 try/finally 语句是一样的。那么它的实现原理是什么?
在讲 with 的原理前要涉及到另外一个概念,就是上下文管理(ContextManager)。
20.2上下文管理器
上下文在不同的地方表示不同的含义,要感性理解。context其实说白了,和文章的上下文是一个意思,在通俗一点,我觉得叫环境更好。
app 点击一个按钮进入一个新的界面,也要保存你是在哪个屏幕跳过来的等等信息,以便你点击返回的时候能正确跳回,如果不存肯定就无法正确跳回了。
看这些都是上下文的典型例子,理解成环境就可以,(而且上下文虽然叫上下文,但是程序里面一般都只有上文而已,只是叫的好听叫上下文。进程中断在操作系统中是有上有下的,不过不这个高深的问题就不要深究了。。。)


总结
Python 提供了 with 语法用于简化资源操作的后续清除操作,是 try/finally 的替代方法,实现原理建立在上下文管理器之上。此外,Python 还提供了一个contextmanager 装饰器,更进一步简化上下管理器的实现方式。
21 闭包装饰器
21.1为什么要使用闭包
问题:初中里学过函数,例如y=kx+b,y=ax2+bx+c
#以y=kx+b 为例,请计算一条线上的过个点即给x值计算出y值
#第1种
k=1
b=2
y=k*x+b
#缺点:如果需要多次计算,那么就的写多次y=k*x+b这样的式子
#第2种
def line_2(k, b, x):
print(k*x+b)
line_2(1, 2, 0)
line_2(1, 2, 1)
#缺点:如果想要计算多次这条线上的y值,那么每次都需要传递k,b的值,麻烦
#第3种:全局变量
k =1
b =2
def line_3(x):
print(k*x+b)
line_3(0)
line_3(1)
k =11
b =22
line_3(0)
line_3(1)
#缺点:如果要计算多条线上的y值,那么需要每次对全局变量进行修改,代码会增多,麻烦
#第4种:缺省参数
def line_4(x, k=1, b=2):
print(k*x+b)
line_4(0)
line_4(1)
line_4(2)
line_4(0, k=11, b=22)
line_4(1, k=11, b=22)
line_4(2, k=11, b=22)
#优点:比全局变量的方式好在:k,b是函数line_4的一部分而不是全局变量,因为全局变量可以任意的被其他函数所修改
#缺点:如果要计算多条线上的y值,那么需要在调用的时候进行传递参数,麻烦
#第5种:实例对象
class Line5(object):
def __init__(self, k, b):
self.k = k
self.b = b
def __call__(self, x):
print(self.k * x + self.b)
line_5_1 = Line5(1, 2)
line_5_1(0)
line_5_1(1)
line_5_2 = Line5(11, 22)
line_5_2(0)
line_5_2(1)
#缺点:为了计算多条线上的y值,所以需要保存多个k,b的值,因此用了很多个实例对象,浪费资源
#第6种:闭包
def line_6(k, b):
def create_y(x):
print(k*x+b)
return create_y
line_6_1 = line_6(1, 2)
line_6_1(0)
line_6_1(1)
line_6_2 = line_6(11, 22)
line_6_2(0)
line_6_2(1)
思考:函数、匿名函数、闭包、对象当做实参时有什么区别?
1.匿名函数能够完成基本的简单功能,传递是这个函数的引用只有功能(lambda)
2.普通函数能够完成较为复杂的功能,传递是这个函数的引用只有功能
3.闭包能够将较为复杂的功能,传递是这个闭包中的函数以及数据,因此传递是功能+数据(相对于对象,占用空间少)
4.对象能够完成最为复杂的功能,传递是很多数据+很多功能,因此传递是功能+数据
21.2函数引用
def test1():
print("--- in test1 func----")
# 调用函数
test1()
# 引用函数
ret = test1
print(id(ret))
print(id(test1))
#通过引用调用函数
ret()
运行结果:
--- in test1 func----
140212571149040
140212571149040
--- in test1 func----
函数与变量一样,也有一个id值
21.3 什么是闭包
在函数内部再定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称之为闭包
闭包也具有提高代码可复用性的作用。
由于闭包引用了外部函数的局部变量,则外部函数的局部变量没有及时释放,消耗内存(不同的闭包地址是不同的)
21.4 修改外部函数中的变量
如果需要修改外部函数的变量
def test1():
x = 200
def test2():
print("----1----x=%d" % x)
x = 100
print("----2----x=%d" % x)
return test2
t1 = test1()
t1()
执行会发现报错
UnboundLocalError: local variable ‘x’ referenced before assignment
因为我们打印x时,没有提前定义,需要在打印之前增加nonlocal x,使用外部函数的变量。
def counter(start=0):
def incr():
nonlocal start
start += 1
return start
return incr
c1 = counter(5)
print(c1())
print(c1())
21.5 装饰器
装饰器是程序开发中经常会用到的一个功能,用好了装饰器,开发效率如虎添翼,所以这也是Python面试中必问的问题,但对于好多初次接触这个知识的人来讲,这个功能有点绕,自学时直接绕过去了,然后面试问到了就挂了,因为装饰器是程序开发的基础知识,这个都不会,别跟人家说你会Python,看了下面的文章,保证你学会装饰器。
#### 第一波 ####
def foo():
print('foo')
foo # 表示是函数
foo() # 表示执行foo函数
#### 第二波 ####
def foo():
print('foo')
foo = lambda x: x + 1
foo(1) # 执行lambda表达式,而不再是原来的foo函数,因为foo这个名字被重新指向了另外一个匿名函数
函数名仅仅是个变量,只不过指向了定义的函数而已,所以才能通过函数名()调用,如果函数名=xxx被修改了,那么当在执行函数名()时,调用的就不知之前的
那个函数了
目前公司有条不紊的进行着,但是,以前基础平台的开发人员在写代码时候没有关注验证相关的问题,即:基础平台的提供的功能可以被任何人使用。现在需要对基
础平台的所有功能进行重构,为平台提供的所有功能添加验证机制,即:执行功能前,先进行验证。
只对基础平台的代码进行重构,其他业务部门无需做任何修改
############### 基础平台提供的功能如下 ###############
def check_login():
# 验证1
# 验证2
# 验证3
pass
def f1():
check_login()
print('f1')
def f2():
check_login()
print('f2')
def f3():
check_login()
print('f3')
写代码要遵循开放封闭原则,虽然在这个原则是用的面向对象开发,但是也适用于函数式编程,简单来说,它规定已经实现的功能代码不允许被修改,但可以被扩展,即:
• 封闭:已实现的功能代码块
• 开放:对扩展开放
如果将开放封闭原则应用在上述需求中,那么就不允许在函数f1、f2、f3的内部进行修改代码,老板就给了LowBBB一个实现方案:
def w1(func):
def inner():
# 验证1
# 验证2
# 验证3
func()
return inner
@w1
def f1():
print('f1')
@w1
def f2():
print('f2')
@w1
def f3():
print('f3')
对于上述代码,也是仅仅对基础平台的代码进行修改,就可以实现在其他人调用函数f1f2f3之前都进行【验证】操作,并且其他业务部门无需做任何操作。
这段代码的内部执行原理是什么呢?
单独以f1为例:
def w1(func):
def inner():
# 验证1
# 验证2
# 验证3
func()
return inner
@w1
def f1():
print('f1')
python 解释器就会从上到下解释代码,步骤如下:
1.def w1(func): ==>将 w1 函数加载到内存
2.@w1
没错,从表面上看解释器仅仅会解释这两句代码,因为函数在没有被调用之前其内部代码不会被执行。
从表面上看解释器着实会执行这两句,但是@w1这一句代码里却有大文章,@函数名是python 的一种语法糖。
上例@w1内部会执行一下操作:
1.执行w1函数,并将@w1下面的函数作为w1函数的参数,即:@w1等价于w1(f1)所以,内部就会去执行:
def inner():
#验证 1
#验证 2
#验证 3
f1() # func 是参数,此时 func 等于 f1
return inner # 返回的 inner,inner代表的是函数,非执行函数 ,其实就是将原来的f1 函数塞进另外一个函数中
2.w1 的返回值
将执行完的w1函数返回值赋值给@w1下面的函数的函数名f1,即将w1的返回值再重新赋值给f1,即:
新f1 = def inner():
#验证 1
#验证 2
#验证 3
原来f1()
return inner
所以,以后业务部门想要执行f1函数时,就会执行新f1函数,在新f1函数内部先执行验证,再执行原来的f1函数,然后将原来f1函数的返回值返回给了业务调用者。
如此一来,即执行了验证的功能,又执行了原来f1函数的内容,并将原f1函数返回值返回给业务调用者
21.6 装饰器实际的原理

21.7 多个装饰器装饰同一个函数




21.8 装饰器(decorator)功能
1.引入日志—在执行某个函数前或者函数后记录日志
2.函数执行时间统计

装饰器的使用场景
1.执行函数前预备处理
2.执行函数后清理功能
3.权限校验等场景
4.缓存
21.9 装饰器示例
例1:无参数的函数
from time import ctime, sleep
def timefun(func):
def wrapped_func():
print("%s called at %s" % (func.__name__, ctime()))
func()
return wrapped_func
@timefun
def foo():
print("I am foo")
foo()
sleep(2)
foo()
上面代码理解装饰器执行行为可理解成
foo = timefun(foo)
# foo 先作为参数赋值给func后,foo接收指向timefun返回的wrapped_func
foo()
# 调用foo(),即等价调用wrapped_func()
# 内部函数wrapped_func被引用,所以外部函数的func变量(自由变量)并没有释放
# func 里保存的是原foo函数对象
例2:被装饰的函数有参数
from time import ctime, sleep
def timefun(func):
def wrapped_func(a, b):
print("%s called at %s" % (func.__name__, ctime()))
print(a, b)
func(a, b)
return wrapped_func
@timefun
def foo(a, b):
print(a+b)
foo(3,5)
sleep(2)
foo(2,4)
#foo参数数量应与wrapped_func相同
例3:被装饰的函数有不定长参数
def set_func(func):
print("---开始进行装饰")
def call_func(*args, **kwargs):
print("---这是权限验证1----")
print("---这是权限验证2----")
# func(args, kwargs) # 不行,相当于传递了2个参数 :1个元组,1个字典
func(*args, **kwargs) # 拆包的过程
return call_func
@set_func # 相当于 test1 = set_func(test1)
def test1(num, *args, **kwargs):
print("-----test1----%d" % num)
print("-----test1----" , args)
print("-----test1----" , kwargs)
test1(100)
test1(100, 200)
test1(100, 200, 300, mm=100)
#采用 *args, **kwargs 参数设计,无论是有参数,无参数,或者多个参数,均能实现传递
例4:装饰器中的return
from time import ctime, sleep
def timefun(func):
def wrapped_func():
print("%s called at %s" % (func.__name__, ctime()))
func()
return wrapped_func
@timefun
def foo():
print("I am foo")
@timefun
def getInfo():
return '----hahah---'
foo()
sleep(1)
foo()
ret=getInfo()
print(ret)
执行结果:
foo called at Fri Nov 4 21:55:35 2016
I am foo
foo called at Fri Nov 4 21:55:37 2016
I am foo
getInfo called at Fri Nov 4 21:55:37 2016
None
如果修改装饰器为return func(),则运行结果:
foo called at Fri Nov 4 21:55:57 2016
I am foo
foo called at Fri Nov 4 21:55:59 2016
I am foo
getInfo called at Fri Nov 4 21:55:59 2016----hahah--
总结:
一般情况下为了让装饰器更通用,加上return
例如:return func()
例5:装饰器带参数,在原有装饰器的基础上,设置外部变量
from time import ctime, sleep
def timefun_arg(pre="hello"):
def timefun(func):
def wrapped_func():
print("%s called at %s %s" % (func.__name__, ctime(), pre))
return func()
return wrapped_func
return timefun
@timefun_arg("wangdao")
def foo():
print("I am foo")
@timefun_arg("python")
def too():
print("I am too")
foo()
sleep(2)
foo()
too()
sleep(2)
too()
# 下面的装饰过程
# 1. 调用timefun_arg("wangdao")
# 2. 将步骤1得到的返回值,即time_fun返回, 然后time_fun(foo)
# 3. 将time_fun(foo)的结果返回,即wrapped_func
# 4. 让foo = wrapped_fun,即foo现在指向wrapped_func
可以理解为foo()==timefun_arg("wangdao")(foo)()
不是很理解?我们来看一个场景,假如test1和test2函数需要不同的权限验证
def set_func(func):
def call_func(*args, **kwargs):
level = args[0]
if level == 1:
print("----权限级别1,验证----")
elif level == 2:
print("----权限级别2,验证----")
return func()
return call_func
@set_func
def test1():
print("-----test1---")
return "ok"
@set_func
def test2():
print("-----test2---")
return "ok"
# 这种方式不好:
# 1. 如果test1之前被调用了N次,那么就需要修改N个
# 2. 调用函数时,验证的级别应该是函数定义的开发者设定,而不是调用者设定
test1(1)
test2(2)
上面的手法是不合适的,那如何做才是合理的呢?
def set_level(level_num):
def set_func(func):
def call_func(*args, **kwargs):
if level_num == 1:
print("----权限级别1,验证----")
elif level_num == 2:
print("----权限级别2,验证----")
return func()
return call_func
return set_func
@set_level(1)
def test1():
print("-----test1---")
return "ok"
@set_level(2)
def test2():
print("-----test2---")
return "ok"
test1()
test2()
# 带有参数的装饰器装饰过程分为2步:
# 1. 调用set_level函数,把1当做实参
# 2. set_level 返回一个装饰器的引用,即set_func
# 3. 用返回的set_func对test1函数进行装饰(装饰过程与之前一样)
例6:类装饰器(了解,非重点)
装饰器函数其实是这样一个接口约束,它必须接受一个callable对象作为参数,然后返回一个callable 对象。在Python 中一般callable 对象都是函数,但也有例外。只要某个对象重写了__call__()方法,那么这个对象就是callable的。
类装饰器demo
class Test(object):
def __init__(self, func):
print("---初始化---")
print("func name is %s"%func.__name__)
self.__func = func
def __call__(self):
print("---装饰器中的功能---")
self.__func()
@Test # 相当于test = Test(test)
def test():
print("----test---")
test()#如果把这句话注释,重新运行程序,依然会看到"--初始化--"
运行结果如下:
---初始化--
func name is test
---装饰器中的功能---
----test---
#说明:
#1. 当用Test来装作装饰器对test函数进行装饰的时候,首先会创建Test的实例对象并且会把test这个函数名当做参数传递到__init__方法中,即在__init__方法中的属性__func指向了test指向的函数
#2. test 指向了用Test创建出来的实例对象
#3. 当在使用test()进行调用时,就相当于让这个对象(),因此会调用这个对象的__call__方法
#4. 为了能够在__call__方法中调用原来test指向的函数体,所以在__init__方法中就需要一个实例属性来保存这个函数体的引用。所以才有了self.__func = func这句代码,从而在调用__call__方法中能够调用到test之前的函数体
例7 增加warps的作用
#warps 的作用是让函数显示自己的名字和备注
from functools import wraps
def my_decorator(func):
def wper(*args, **kwargs):
'''decorator'''
print('Calling decorated function...')
return func(*args, **kwargs)
return wper
@my_decorator
def example():
"""Docstring"""
print('Called example function')
print(example.__name__, example.__doc__)#wper decorator
输出:wper decorator
#修改了实际名称
from functools import wraps
def my_decorator(func):
@wraps(func)
def wper(*args, **kwargs):
'''decorator'''
print('Calling decorated function...')
return func(*args, **kwargs)
return wper
@my_decorator
def example():
"""Docstring"""
print('Called example function')
print(example.__name__, example.__doc__) # example Docstring
输出:example Docstring
22 元类与ORM-面向接口编程
22.1元类(了解,如果有时间理解最好)
22.1.1 类也是对象
在大多数编程语言中,类就是一组用来描述如何生成一个对象的代码段。在Python 中这一点仍然成立:
>>> class ObjectCreator(object):
pass
>>> my_object = ObjectCreator()
>>> print(my_object)
<__main__.ObjectCreator object at 0x8974f2c>
但是,Python 中的类还远不止如此。类同样也是一种对象。是的,没错,就是对象。只要你使用关键字class,Python 解释器在执行的时候就会创建一个对象。
将在内存中创建一个对象,名字就是ObjectCreator。这个对象(类对象ObjectCreator)拥有创建对象(实例对象)的能力。但是,它的本质仍然是一个对象,于是乎你可以对它做如下的操作:
- 你可以将它赋值给一个变量
- 你可以拷贝它
- 你可以为它增加属性
- 你可以将它作为函数参数进行传递
>>> print(ObjectCreator) # 你可以打印一个类,因为它其实也是一个对象
<class '__main__.ObjectCreator'>
>>> def echo(o):
print(o)
>>> echo(ObjectCreator) # 你可以将类做为参数传给函数
<class '__main__.ObjectCreator'>
>>> print(hasattr(ObjectCreator, 'new_attribute'))
Fasle
>>> ObjectCreator.new_attribute = 'foo' # 你可以为类增加属性
>>> print(hasattr(ObjectCreator, 'new_attribute'))
True
>>> print(ObjectCreator.new_attribute)
foo
>>> ObjectCreatorMirror = ObjectCreator # 你可以将类赋值给一个变量
>>> print(ObjectCreatorMirror())
<__main__.ObjectCreator object at 0x8997b4c>
22.1.2 动态地创建类
因为类也是对象,你可以在运行时动态的创建它们,就像其他任何对象一样。首先,你可以在函数中创建类,使用class关键字即可。
>>> def choose_class(name):
if name == 'foo':
class Foo(object):
pass
return Foo# 返回的是类,不是类的实例
else:
class Bar(object):
pass
return Bar
>>> MyClass = choose_class('foo')
>>> print(MyClass) # 函数返回的是类,不是类的实例
<class '__main__'.Foo>
>>> print(MyClass()) # 你可以通过这个类创建类实例,也就是对象
<__main__.Foo object at 0x89c6d4c>
但这还不够动态,因为你仍然需要自己编写整个类的代码。由于类也是对象,所以它们必须是通过什么东西来生成的才对。
当你使用class关键字时,Python 解释器自动创建这个对象。但就和Python中的大多数事情一样,Python仍然提供给你手动处理的方法。
还记得内建函数type吗?这个古老但强大的函数能够让你知道一个对象的类型是什么,就像这样:
>>> print(type(1)) # 数值的类型
<type 'int'>
>>> print(type("1")) # 字符串的类型
<type 'str'>
>>> print(type(ObjectCreator())) # 实例对象的类型
<class '__main__.ObjectCreator'>
>>> print(type(ObjectCreator)) # 类的类型
<class 'type'>
仔细观察上面的运行结果,发现使用type对ObjectCreator 查看类型是,答案为type,是不是有些惊讶。。。看下面
22.1.3 使用type 创建类
type 还有一种完全不同的功能,动态的创建类。
type 可以接受一个类的描述作为参数,然后返回一个类。(要知道,根据传入参数的不同,同一个函数拥有两种完全不同的用法是一件很傻的事情,但这在Python 中是为了保持向后兼容性)
type 可以像这样工作:
type(类名,由父类名称组成的元组(针对继承的情况,可以为空),包含属性的字典(名称和值))
比如下面的代码:
In [2]: class Test: #定义了一个Test类
pass
In [3]: Test() # 创建了一个Test类的实例对象
Out[3]: <__main__.Test at 0x10d3f8438>
可以手动像这样创建:
Test2 = type("Test2", (), {}) # 定了一个Test2类
In [5]: Test2() # 创建了一个Test2类的实例对象
Out[5]: <__main__.Test2 at 0x10d406b38>
我们使用"Test2"作为类名,并且也可以把它当做一个变量来作为类的引用。类和变量是不同的,这里没有任何理由把事情弄的复杂。即type函数中第1个实参,也可以叫做其他的名字,这个名字表示类的名字
In [23]: MyDogClass = type('MyDog', (), {})
In [24]: print(MyDogClass)
<class '__main__.MyDog'>
使用help 来测试这2个类
In [10]: help(Test2) # 用help查看Test类
Help on class Test in module __main__:
class Test(builtins.object)
| Data descriptors defined here:
|
| __dict__
|
dictionary for instance variables (if defined)
|
| __weakref__
|
list of weak references to the object (if defined)
In [8]: help(Test2) #用help 查看Test2类
Help on class Test2 in module __main__:
class Test2(builtins.object)
| Data descriptors defined here:
|
| __dict__
|
dictionary for instance variables (if defined)
|
| __weakref__
|
list of weak references to the object (if defined)
22.1.4 使用type 创建带有属性的类
type 接受一个字典来为类定义属性,因此
>>> Foo = type('Foo', (), {'bar': True})
可以翻译为:
>>> class Foo(object):
bar = True
请问bar是什么属性?
并且可以将Foo当成一个普通的类一样使用:
>>> print(Foo)
<class '__main__.Foo'>
>>> print(Foo.bar)
True
>>> f = Foo()
>>> print(f)
<__main__.Foo object at 0x8a9b84c>
>>> print(f.bar)
True
当然,你可以继承这个类,代码如下:
>>> class FooChild(Foo):
pass
就可以写成:
>>> FooChild = type('FooChild', (Foo,), {})
>>> print(FooChild)
<class '__main__.FooChild'>
>>> print(FooChild.bar) # bar 属性是由Foo继承而来
True
注意:
• type的第2个参数,元组中是父类的名字,而不是字符串
• 添加的属性是类属性,并不是实例属性
22.1.5 使用type 创建带有方法的类
最终你会希望为你的类增加方法。只需要定义一个有着恰当签名的函数并将其作为属性赋值就可以了。
添加实例方法
In [46]: def echo_bar(self): # 定义了一个普通的函数
print(self.bar)
In [47]: FooChild = type('FooChild', (Foo,), {'echo_bar': echo_bar}) #
让FooChild 类中的echo_bar 属性,指向了上面定义的函数
In [48]: hasattr(Foo, 'echo_bar') # 判断Foo类中 是否有echo_bar这个属性
Out[48]: False
In [49]: hasattr(FooChild, 'echo_bar') # 判断FooChild 类中 是否有echo_bar 这个属性
Out[49]: True
In [50]: my_foo = FooChild()
In [51]: my_foo.echo_bar()
True
添加静态方法
In [36]: @staticmethod
def test_static():
print("static method ....")
In [37]: Foochild = type('Foochild', (Foo,), {"echo_bar": echo_bar, "te
st_static": test_static})
In [38]: fooclid = Foochild()
In [39]: fooclid.test_static
Out[39]: <function __main__.test_static>
In [40]: fooclid.test_static()
static method ....
In [41]: fooclid.echo_bar()
True
添加类方法
In [42]: @classmethod
def test_class(cls):
print(cls.bar)
In [43]: Foochild = type('Foochild', (Foo,), {"echo_bar":echo_bar, "tes
t_static": test_static, "test_class": test_class})
In [44]: fooclid = Foochild()
In [45]: fooclid.test_class()
True
你可以看到,在Python中,类也是对象,你可以动态的创建类。
这就是当你使用关键字class 时Python 在幕后做的事情,而这就是通过元类来实现的。
较为完整的使用type创建类的方式:
class A(object):
num = 100
def print_b(self):
print(self.num)
@staticmethod
def print_static():
print("----haha-----")
@classmethod
def print_class(cls):
print(cls.num)
B = type("B", (A,), {"print_b": print_b, "print_static": print_static,
"print_class": print_class})
b = B()
b.print_b()
b.print_static()
b.print_class()
# 结果
# 100
#----haha----
# 100
22.1.6 到底什么是元类
元类就是用来创建类的“东西”。你创建类就是为了创建类的实例对象,不是吗?但是我们已经学习到了Python中的类也是对象。
元类就是用来创建这些类(对象)的,元类就是类的类,你可以这样理解为:
MyClass = MetaClass() # 使用元类创建出一个对象,这个对象称为“类”
my_object = MyClass() # 使用“类”来创建出实例对象
你已经看到了type可以让你像这样做:
MyClass = type(‘MyClass’, (), {})
这是因为类type实际上是一个元类。**type就是Python在背后用来创建所有类的元类。**现在你想知道那为什么type会全部采用小写形式而不是Type呢?好吧,我猜这是为了和str保持一致性,**str是用来创建字符串对象的类,而int是用来创建整数对象的类。type就是创建类对象的类。**你可以通过检查(__class__)属性来看到这一点。Python 中所有的东西,注意,我是指所有的东西——都是对象。这包括整数、字符串、函数以及类。它们全部都是对象,而且它们都是从一个类创建而来,这个类就是type。
>>> age = 35
>>> age.__class__
<type 'int'>
>>> name = 'bob'
>>> name.__class__
<type 'str'>
>>> def foo(): pass
>>>foo.__class__
<type 'function'>
>>> class Bar(object): pass
>>> b = Bar()
>>> b.__class__
<class '__main__.Bar'>
现在,对于任何一个_\_class__的_\_class__属性又是什么呢?
>>> age.__class__.__class__
<type 'type'>
>>> foo.__class__.__class__
<type 'type'>
>>> b.__class__.__class__
<type 'type'>
因此,元类就是创建类这种对象的东西。type就是Python的内建元类,当然了,你也可以创建自己的元类。
22.1.7 __metaclass__属性
你可以在定义一个类的时候为其添加__metaclass__属性。
class Foo(object):
metaclass = something…
如果你这么做了,Python就会用元类来创建类Foo。小心点,这里面有些技巧。
你首先写下class Foo(object),但是类Foo 还没有在内存中创建。Python 会在类的定义中寻找__metaclass__属性,如果找到了,Python 就会用它来创建类Foo,如果没有找到,就会用内建的type来创建这个类。把下面这段话反复读几次。当你写如下代码时:
class Foo(Bar):
pass
Python 做了如下的操作:
1.Foo 中有__metaclass__这个属性吗?如果是,Python 会通过__metaclass__创建一个名字为Foo的类(对象)
2.如果Python 没有找到__metaclass__,它会继续在Bar(父类)中寻找__metaclass__属性,并尝试做和前面同样的操作。
3.如果Python 在任何父类中都找不到__metaclass__,它就会在模块层次中去寻找__metaclass__,并尝试做同样的操作。
4.如果还是找不到__metaclass__,Python 就会用内置的type 来创建这个类对象。
现在的问题就是,你可以在__metaclass__中放置些什么代码呢?答案就是:可以创建一个类的东西。那为什么可以用来创建一个类呢?type,或者任何使用到type或者子类化type的东东都可以。
22.1.8 自定义元类
元类的主要目的就是为了当创建类时能够自动地改变类。
假想一个很傻的例子,你决定在你的模块里所有的类的属性都应该是大写形式。有好几种方法可以办到,但其中一种就是通过在模块级别设定__metaclass__。采用这种方法,这个模块中的所有类都会通过这个元类来创建,我们只需要告诉元类把所
有的属性都改成大写形式就万事大吉了。
幸运的是,__metaclass__实际上可以被任意调用,它并不需要是一个正式的类。所以,我们这里就先以一个简单的函数作为例子开始。
#-*- coding:utf-8-*
def upper_attr(class_name, class_parents, class_attr):
#遍历属性字典,把不是__开头的属性名字变为大写
new_attr = {}
for name,value in class_attr.items():
if not name.startswith("__"):
new_attr[name.upper()] = value
#调用type来创建一个类
return type(class_name, class_parents, new_attr)
class Foo(object, metaclass=upper_attr):
bar = 'bip'
print(hasattr(Foo, 'bar'))
print(hasattr(Foo, 'BAR'))
f = Foo()
print(f.BAR)
现在让我们再做一次,这一次用一个真正的class来当做元类。
#coding=utf-8
class UpperAttrMetaClass(type):
# __new__ 是在__init__之前被调用的特殊方法
# __new__是用来创建对象并返回之的方法
# 而__init__只是用来将传入的参数初始化给对象
# 你很少用到__new__,除非你希望能够控制对象的创建
# 这里,创建的对象是类,我们希望能够自定义它,所以我们这里改写__new__
# 如果你希望的话,你也可以在__init__中做些事情
# 还有一些高级的用法会涉及到改写__call__特殊方法,但是我们这里不用
def __new__(cls, class_name, class_parents, class_attr):
# 遍历属性字典,把不是__开头的属性名字变为大写
new_attr = {}
for name, value in class_attr.items():
if not name.startswith("__"):
new_attr[name.upper()] = value
# 方法1:通过'type'来做类对象的创建,不要用这种
return type(class_name, class_parents, new_attr)
# 方法2:复用type.__new__方法
# 这就是基本的OOP编程,没什么魔法,用这一种,可以保证父类使用metaclass 正确
# return type.__new__(cls, class_name, class_parents, new_attr)
# python3 的用法
class Foo(object, metaclass=UpperAttrMetaClass):
bar = 'bip'
print(hasattr(Foo, 'bar'))
# 输出: False
print(hasattr(Foo, 'BAR'))
# 输出:True
f = Foo()
print(f.BAR)
# 输出:'bip'
就是这样,除此之外,关于元类真的没有别的可说的了。但就元类本身而言,它们其实是很简单的(metaclass 总结):
1.拦截类的创建
2.修改类
3.返回修改之后的类
究竟为什么要使用元类?
现在回到我们的大主题上来,究竟是为什么你会去使用这样一种容易出错且晦涩的特性?好吧,一般来说,你根本就用不上它:
“元类就是深度的魔法,99%的用户应该根本不必为此操心。如果你想搞清楚究竟是否需要用到元类,那么你就不需要它。那些实际用到元类的人都非常清楚地知道他们需要做什么,而且根本不需要解释为什么要用元类。”——Python界的领袖TimPeters
22.2 元类实现ORM
22.2.1 ORM 是什么
ORM是python 编程语言后端web框架Django 的核心思想,“ObjectRelational Mapping”,即对象-关系映射,简称ORM。(JAVA也是ORM)
一个句话理解就是:创建一个实例对象,用创建它的类名当做数据表名,用创建它的类属性对应数据表的字段,当对这个实例对象操作时,能够对应MySQL语句
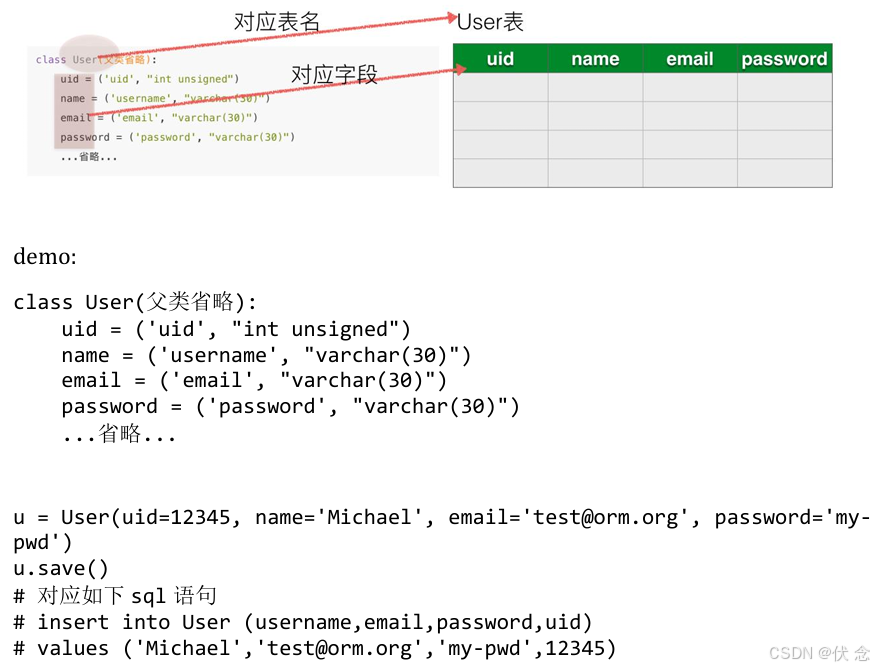
说明
1.所谓的ORM就是让开发者在操作数据库的时候,能够像操作对象时通过xxxx.属性=yyyy一样简单,这是开发ORM的初衷
2.只不过ORM的实现较为复杂,Django中已经实现了很复杂的操作,本节知识主要通过完成一个insert相类似的ORM,理解其中的道理就就可以了
22.2.2 通过元类简单实现ORM中的insert功能


22.2.3 完善对数据类型的检测



22.2.4 抽取到基类中


元类的使用场景相对较少,但在某些情况下非常有用,特别是在框架和库的开发中。例如,Django中的ORM使用元类,DjangoRESTFramework(DRF)使用了元类技术。元类在DRF中的主要作用是帮助创建序列化器(Serializer)类和视图集(Viewset)类。
22.3 接口类与抽象类
继承有两种用途:
一:继承基类的方法,并且做出自己的改变或者扩展(代码重用)
二:声明某个子类兼容于某基类,定义一个接口类Interface,接口类中定义了一些接口名(就是函数名)且并未实现接口的功能,子类继承接口类,并且实现接口中的功能
三、接口隔离原则:使用多个专门的接口,而不使用单一的总接口。即客户端不应该依赖那些不需要的接口
接口类:基于同一个接口实现的类 刚好满足接口隔离原则 面向对象开发的思想规范
接口类,python 原生不支持 在python中,并没有接口类这种东西,即便不通过专门的模块定义接口,我们也应该有一些基本的概念
22.3.1 接口类单继承
class Alipay:
def pay(self,money):
print('支付宝支付了')
class Apppay:
def pay(self,money):
print('苹果支付了')
class Weicht:
def pay(self,money):
print('微信支付了')
def pay(payment,money): #支付函数,总体负责支付,对应支付的对象和要支付的金额
payment.pay(money)
p=Alipay()
pay(p,200) #支付宝支付了
这段代码,实现了一个有趣的功能,就是通过一个总体的支付函数,实现了不同种类的支付方式,不同是支付方式作为对象,传入函数中
但是开发中容易出现一些问题,那就是类中的函数名不一致,就会导致调用的时候找不到类中对应方法,
类的方法可能由于程序员的疏忽,写的不是一致的pay,导致后面调用的时候找不到pay
这时候怎么办呢?可以手动抛异常:NotImplementedError来解决开发中遇到的问题
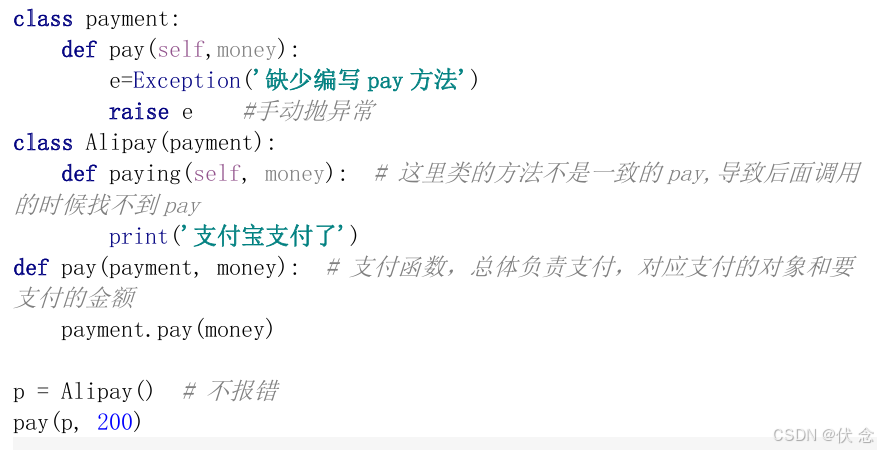
也可以借用abc模块来处理这种错误



22.3.2 接口类多继承

22.3.3 抽象类
抽象类的本质还是类,指的是一组类的相似性,包括数据属性(如all_type)和函数属性(如read、write),而接口只强调函数属性的相似性
1.抽象类是一个介于类和接口之间的一个概念,同时具备类和接口的部分特性,可以用来实现归一化设计
2.在继承抽象类的过程中,我们应该尽量避免多继承;
3.而在继承接口的时候,我们反而鼓励你来多继承接口
一般情况下 单继承 能实现的功能都是一样的,所以在父类中可以有一些简单的基础实现
多继承的情况 由于功能比较复杂,所以不容易抽象出相同的功能的具体实现写在父类中
为什么要有抽象类
从设计角度去看,如果类是从现实对象抽象而来的,那么抽象类就是基于类抽象而来的。
从实现角度来看,抽象类与普通类的不同之处在于:抽象类中有抽象方法,该类不能被实例化,只能被继承,且子类必须实现抽象方法。这一点与接口有点类似,但其实是不同的
#一切皆文件
import abc #利用abc模块实现抽象类
class All_file(metaclass=abc.ABCMeta):
all_type='file'
@abc.abstractmethod#定义抽象方法,无需实现功能
def read(self):
'子类必须定义读功能'
pass
@abc.abstractmethod#定义抽象方法,无需实现功能
def write(self):
'子类必须定义写功能'
pass
# class Txt(All_file):
# pass
# t1=Txt() #报错,子类没有定义抽象方法
class Txt(All_file): #子类继承抽象类,但是必须定义read和write方法
def read(self):
print('文本数据的读取方法')
def write(self):
print('文本数据的读取方法')
class Sata(All_file):#子类继承抽象类,但是必须定义read和write方法
def read(self):
print('硬盘数据的读取方法')
def write(self):
print('硬盘数据的读取方法')
class Process(All_file):#子类继承抽象类,但是必须定义read和write方法
def read(self):
print('进程数据的读取方法')
def write(self):
print('进程数据的读取方法')
wenbenwenjian=Txt()
yingpanwenjian=Sata()
jinchengwenjian=Process()
#这样大家都是被归一化了,也就是一切皆文件的思想
wenbenwenjian.read()
yingpanwenjian.write()
jinchengwenjian.read()
print(wenbenwenjian.all_type)
print(yingpanwenjian.all_type)
print(jinchengwenjian.all_type)
22.3.4 扩展:
不管是抽象类还是接口类:面向对象的开发规范所有的接口类和抽象类都不能
实例化
java:
java里的所有类的继承都是单继承,所以抽象类完美的解决了单继承需求中的规范问题
但对于多继承的需求,由于java本身语法的不支持,所以创建了接口Interface这个概念来解决多继承的规范问题
python:
python中没有接口类:
python中自带多继承所以我们直接用class来实现了接口类
python中支持抽象类:一般情况下单继承不能实例化且可以实现python代码
https://blog.csdn.net/zhangquan2015/article/details/82808399
22.3.5 注意
1.多继承问题
在继承抽象类的过程中,我们应该尽量避免多继承;
而在继承接口的时候,我们反而鼓励你来多继承接口
2.方法的实现
在抽象类中,我们可以对一些抽象方法做一些基础实现;
而在接口类中,任何方法都只是一种规范,具体的功能需要子类实现

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









