 理解NUMA架构与Socket关系:CPU亲和性与性能优化
理解NUMA架构与Socket关系:CPU亲和性与性能优化







 本文深入探讨了NUMA架构在多处理器系统中的作用,特别是AMDEPYC处理器的非均匀内存访问设计。作者指出操作系统如何通过CPU亲和性优化内存访问,并揭示了操作系统中关闭NUMA配置的实质。
本文深入探讨了NUMA架构在多处理器系统中的作用,特别是AMDEPYC处理器的非均匀内存访问设计。作者指出操作系统如何通过CPU亲和性优化内存访问,并揭示了操作系统中关闭NUMA配置的实质。
往期相关文章链接
DPDK 系列第三篇:CPU 亲和性及实际应用-CSDN博客
概念介绍
NUMA(Non-Uniform Memory Access):NUMA是一种内存访问模型,用于多处理器系统中。在NUMA架构中,系统的内存和处理器被组织成多个节点(或称为NUMA节点)。每个节点都有自己的本地内存和与之关联的处理器。这种架构旨在减少处理器与内存之间的延迟,并提高系统性能。
节点(Node):节点是NUMA架构中的基本单元。每个节点由一组处理器和与之关联的本地内存组成。节点之间通过互连(如快速总线或互连网络)进行通信。每个节点都有一个唯一的标识符,通常称为节点号。
插槽(Socket):插槽是物理处理器的概念,也称为CPU插槽。在多处理器系统中,每个插槽可以容纳一个或多个物理处理器。每个插槽通常对应一个物理套接字(socket),其中包含一个或多个物理处理器核心。
CPU(Central Processing Unit):CPU是计算机中用于执行指令和处理数据的核心部件。在多处理器系统中,每个物理处理器可以包含一个或多个CPU核心。每个CPU核心都可以独立执行指令,并具有自己的缓存和寄存器。
深入人心的问题
大部分linux 开发人员可能知道 numa 和socket 的存在,知道 numa系统中访问自身近内存性能会高,也知道 通过linux grub 命令行配置可以关闭numa (假关闭),但是假如系统有 A、B、C、D 四个numa,进程运行在A numa 所属core 上, 那你是否知道A numa core 上的进程访问B、C、D哪个numa 的内存性能会更高?或者浅一层的问题,你认为 NUMA 和 SOCKET是一对一的关系吗?
核心点-SOCKET和NUMA的关系
为了说明问题,后续部分会以AMD EPYC 系列芯片的NUMA设计展开
设计服务器芯片是一个平衡的过程,需要在系统成本、芯片面积、内存带宽、内存延迟等方面进行权衡。AMD考虑进入服务器市场时,面临着一项艰巨的任务。公司需要设计一款性能与英特尔的至强处理器相竞争的处理器,同时能够提供差异化,并且仍然保持100%的x86软件兼容性。AMD的EPYC处理器似乎正是实现了这一目标。该公司设计和制造了一款服务器处理器,提供了比英特尔至强设计更多的内存和I/O带宽,同时建造成本也更低,这要归功于多芯片模块(MCM)技术和公司的新Infinity Fabric(IF)技术的高效利用。
MCM技术为AMD提供了一个机会,利用更小、更易制造的芯片来构建一个功能强大的服务器处理器。AMD还开发了Infinity Fabric,这是公司HyperTransport技术的延伸,作为一种无缝、可扩展的互连技术,可用于芯片内部、封装内部和多封装之间的通信。由此设计产生的处理器包括其组成处理器芯片之间的分层路径,形成了非均匀内存访问(NUMA)模型。
如下图所示,AMD在构建EPYC处理器时采用了多个Zeppelin芯片,用于构建可扩展的服务器系统。多芯片的方法具有优势,因为它允许AMD构建具有高核心数、内存带宽和I/O的服务器处理器,而无需使用更昂贵且产量较低的芯片制造工艺。使用多个芯片的折衷之处在于,芯片之间的内存访问会增加额外的延迟。
如贴图所示 ,该系统存在两个socket,每个socket 上为一颗EPYC处理器,EPYC处理器由四个面积为213 mm2的Zeppelin芯片组成。虽然再外封装是一颗处理器,但是实际里边有四个芯片处理单元,那那个处理单元都有自己的进内存,这样的情况下,就可以将一个插槽分割为4个NUMA节点,所以到这里各位看官应该明了 SOCKET 和 NUMA 非一一对应关系了吧。
当然这是AMD的设计,其他公司单SOCKET 或NUMA的情况也会有,可能基于多内存通道等等技术。
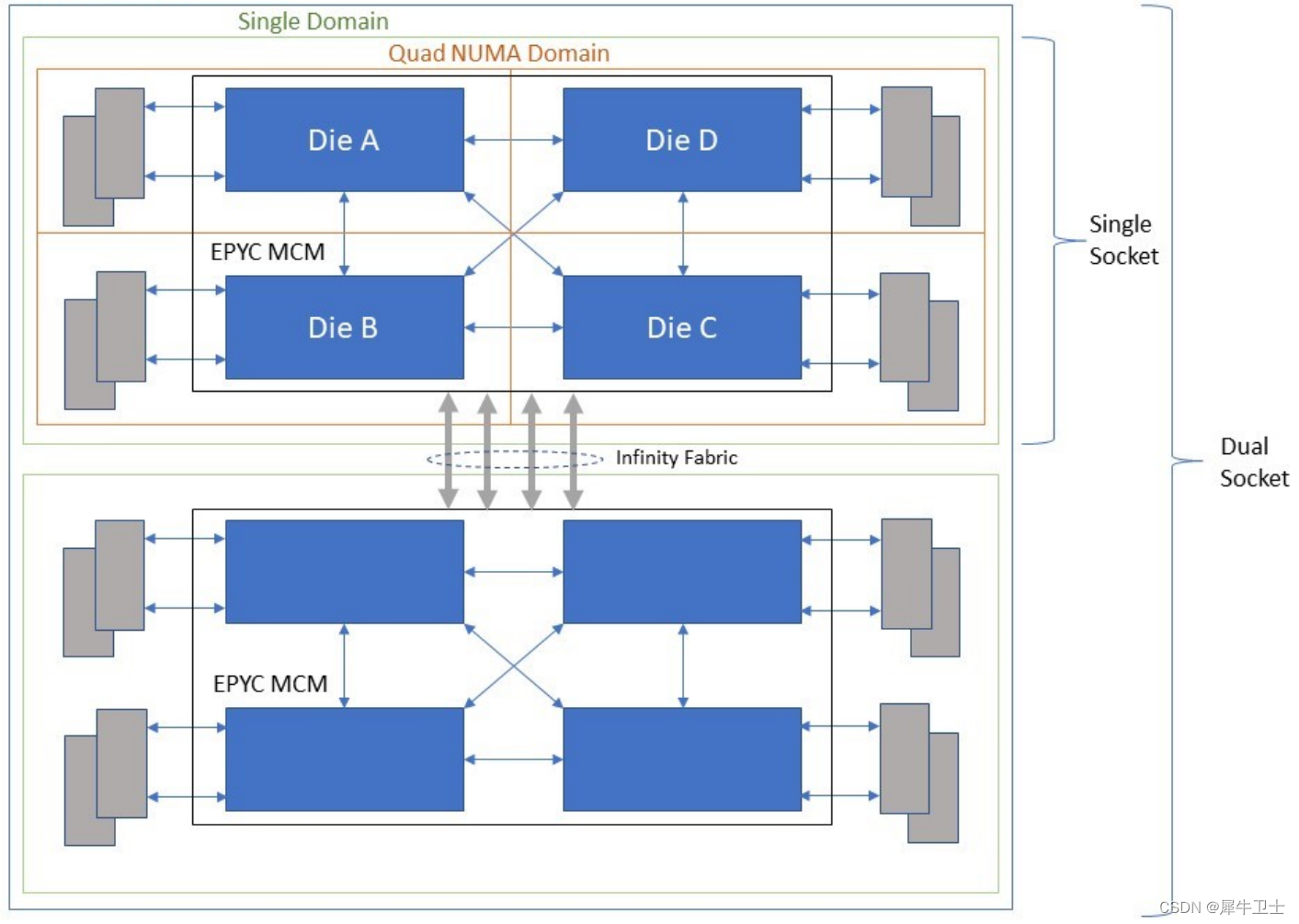
访问本NUMA 外的哪个NUMA能更块?
现代操作系统中,基于性能考虑,会使用CPU亲和性(不清楚的,可以参考之前的博文DPDK 系列第三篇:CPU 亲和性及实际应用-CSDN博客)将软件任务调度到特定的核心或核心池上,然后将数据加载到特定核心所属的NUMA内存中(称为“内存亲和性”)。
但是,随着业务的增多或者硬件架构的特异性,难免会出现A NUMA core上的进程需要访问B NUMA 上的数据,或者某个进程需要绑定在多个NUMA 的情况,以进程绑定在多个NUMA这种情况下来说,我们应该怎么选择进程绑定再哪些NUMA上呢?
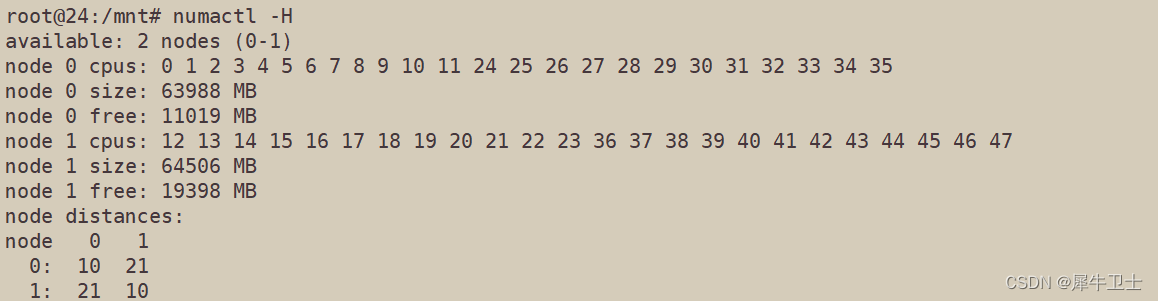
其实上一小节的贴图就很能说明问题,访问本芯片组内的NUMA,一定是能优于访问另外一个SOCKET所属NUMA的,但是在实际使用中,我们不可能去查,也不太容易获取到芯片设计资料,那这种时候,可以如下使用numactl 工具来确认。
node distances 是一个二维矩阵,node[i][j] 表示 node i (numa i ,概念介绍里已经进行了明确,node 是numa 管理的基本单元)访问 node j 的内存的相对距离。比如 node 0 访问 node 0 的内存的距离是 10,而 node 0 访问 node 1 的内存的距离是 21。
操作系统进行grub配置关闭NUMA是真的关了吗?
通过在GRUB 中配置 “numa=off” 可以使在操作系统中只看到一个NUMA,那这样调节后真能起到真正的一个NUMA的效果吗,答案是否定的。
当设置"numa=off"参数时,Linux内核仅仅是忽略NUMA架构,将所有内存视为统一的存储池,所有处理器都可以访问所有内存。但是实实在在的硬件架构是确实存在的的,访问远端内存就是可能会走AMD 的 Infinity Fabric或者英特尔的QPI。
-------------------------------分割线-------------------------------------------
看到这里,各位看官应该对 numa 和socket 有一些客观上的认识了,如果对大家的实际开发有所帮助,请关注加收藏,不枉小编熬夜写作,谢谢。


















 1194
1194





 到【灌水乐园】发言
到【灌水乐园】发言







