






 本文介绍了NUMA架构的基本概念,包括其如何通过划分节点提升内存访问速度,以及numactl工具在内存管理和限制上的应用。重点讨论了NUMA陷阱、内存分配策略的选择,以及UMA和SMP的区别。针对不同规模内存需求的程序,提供了优化建议和实例操作指导。
本文介绍了NUMA架构的基本概念,包括其如何通过划分节点提升内存访问速度,以及numactl工具在内存管理和限制上的应用。重点讨论了NUMA陷阱、内存分配策略的选择,以及UMA和SMP的区别。针对不同规模内存需求的程序,提供了优化建议和实例操作指导。
NUMA概念
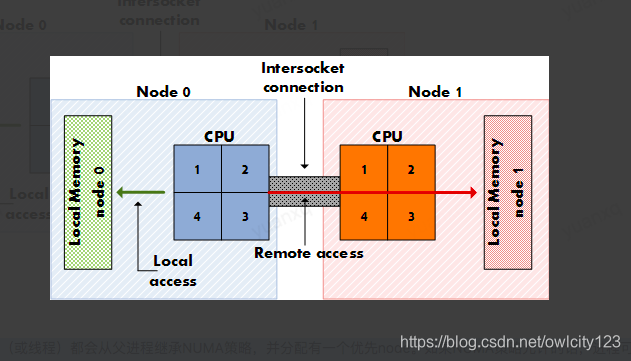
比如一台机器是有2个处理器,有4个内存块。我们将1个处理器和两个内存块合起来,称为一个NUMA node,这样这个机器就会有两个NUMA node。在物理分布上,NUMA node的处理器和内存块的物理距离更小,因此访问也更快。比如这台机器会分左右两个处理器(cpu1, cpu2),在每个处理器两边放两个内存块(memory1.1, memory1.2, memory2.1,memory2.2),这样NUMA node1的cpu1访问memory1.1和memory1.2就比访问memory2.1和memory2.2更快。所以使用NUMA的模式如果能尽量保证本node内的CPU只访问本node内的内存块,那这样的效率就是最高的。
在运行程序的时候使用numactl -m和-physcpubind就能制定将这个程序运行在哪个cpu和哪个memory中。玩转cpu-topology 给了一个表格,当程序只使用一个node资源和使用多个node资源的比较表(差不多是38s与28s的差距)。所以限定程序在numa node中运行是有实际意义的。事实上Linux识别到NUMA架构后,默认的内存分配方案就是:优先尝试在请求线程当前所处的CPU的Local内存上分配空间。如果local内存不足,优先淘汰local内存中无用的Page(Inactive,Unmapped)。
NUMA陷阱
但是呢,话又说回来了,制定numa就一定好吗?SWAP的罪与罚文章就说到了一个numa的陷阱的问题。现象是当你的服务器还有内存的时候,发现它已经在开始使用swap了,甚至已经导致机器出现停滞的现象。这个就有可能是由于numa的限制,如果一个进程限制它只能使用自己的numa节点的内存,那么当自身numa node内存使用光之后,就不会去使用其他numa node的内存了,会开始使用swap,甚至更糟的情况,机器没有设置swap的时候,可能会直接死机!所以你可以使用numactl --interleave=all来取消numa node的限制。
如果你的程序是会占用大规模内存的,你大多应该选择关闭numa node的限制(或从硬件关闭numa)。因为这个时候你的程序很有几率会碰到numa陷阱。另外,如果你的程序并不占用大内存,而是要求更快的程序运行时间。你大多应该选择限制只访问本numa node的方法来进行处理。总结如下:
如果程序会占用大内存的,因为很有可能碰到 SWAP 问题。
1. 考虑从 BIOS 层 关闭 NUMA。
2. 考虑从 OS 层 关闭 NUMA。
3. 设置 NUMA 的 内存 分配策略 为 interleave=all。
4. 设置 内核参数 vm.zone_reclaim_mode=0。
如果程序并不会占用大内存,而是要求更快的程序运行时间。
1. 应该选择限制只访问本 NUMA node。
UMA和SMP是两种CPU相关的硬件架构。在SMP架构里面,所有的CPU争用一个总线来访问所有内存,优点是资源共享,而缺点是总线争用激烈。随着PC服务器上的CPU数量变多(不仅仅是CPU核数),总线争用的弊端慢慢越来越明显,于是Intel在Nehalem CPU上推出了NUMA架构,而AMD也推出了基于相同架构的Opteron CPU。
NUMA最大的特点是引入了node和distance的概念。对于CPU和内存这两种最宝贵的硬件资源,NUMA用近乎严格的方式划分了所属的资源组(node),而每个资源组内的CPU和内存是几乎相等。资源组的数量取决于物理CPU的个数(现有的PC server大多数有两个物理CPU,每个CPU有4个核);distance这个概念是用来定义各个node之间调用资源的开销,为资源调度优化算法提供数据支持。
NUMA 策略
每个进程(或线程)都会从父进程继承NUMA策略,并分配有一个优先node。如果NUMA策略允许的话,进程可以调用其他node上的资源。
NUMA的CPU分配策略有cpunodebind、physcpubind。cpunodebind规定进程运行在指定的NUMA node之上,而physcpubind可以更加精细地规定运行在指定的逻辑核上
NUMA的内存分配策略有localalloc、preferred、membind、interleave。
localalloc规定进程从当前node上请求分配内存;
preferred比较宽松地指定了一个推荐的node来获取内存,如果被推荐的node上没有足够内存,进程可以尝试别的node。
membind可以指定若干个node,进程只能从这些指定的node上请求分配内存。
interleave规定进程从指定的若干个node上以RR(Round Robin 轮询调度)算法交织地请求分配内存。
numactl命令
yum install numactl
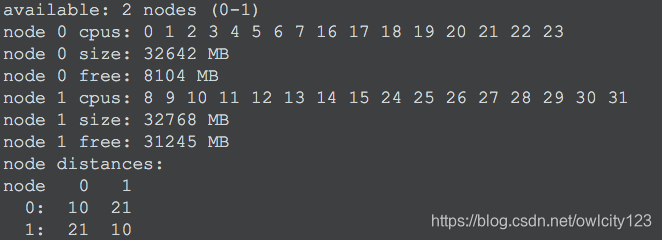
numactl --hardware
numactl --show

numastat
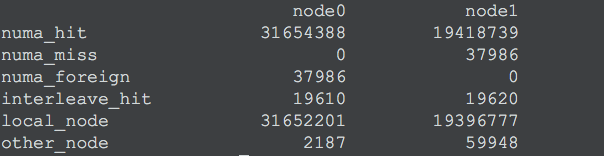
如果发现 numa_miss 数值比较高时,说明需要对分配策略进行调整。
例如将指定进程关联绑定到指定的CPU上,从而提高内存命中率。
NUMA 的 分配策略例子
- 绑定
numactl --physcpubind=1 --localalloc /usr/sbin/named - 查看cpu数量
grep processor /proc/cpuinfo - 查看named进程ID
ps -aux | grep named - 查看named进程在哪个CPU上 #
ps工具提供了PSR列显示当前进程运行的CPUps -axo pid,psr | grep 11904 - 查看named的绑定状态

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









