







系列文章
DPDK 系列第二篇:CPU Cache详解及DPDK在Cache方面的性能应用-CSDN博客
DPDK 系列第三篇:CPU 亲和性及实际应用-CSDN博客
本文提纲
为了提高网卡收发性能,便于DMA访问控制,DPDK所管理的内存空间都是基于大页(hugepage)来构建的,采用大页内存的好处一方面可以将内存空间固定住(使其不被swapout),另一方面也能有效提升TLB缓存的命中效率。具体大页的讲解在之前的博文里都提到,需要的可以通过链接回看(DPDK 系列第四篇:TLB和大页)。
本文主要总结分享下DPDK 基于大页的内存管理,涉及到大页,memseg、memzone等内容。因为内存管理整体涉及到的东西比较多, 理解起来也会有响应的难度,所以本文会以先总后分的形式进行讲解,先从让大家对DPDK 的内存系统整体上有一个认知,然后再展开介绍里边的小点。
内存整体架构
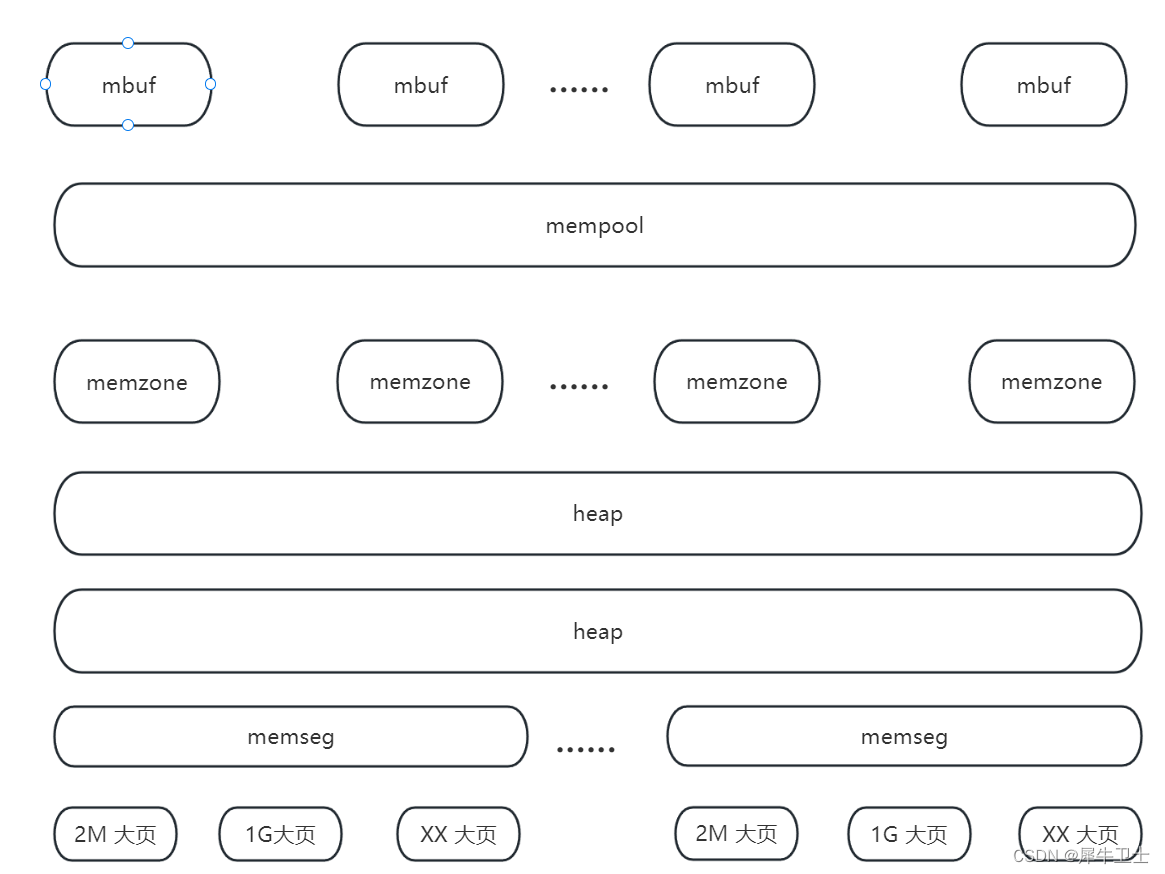
下图为PDK内存管理整体架构图,我们平常直接基于DPDK套件进行转发开发,对rte_mbuf,mempool可能相对熟悉,但是对于底层的memzone,memseg等可能就较为陌生了。本篇博客就是要梳理清楚各个模块之间的关系。
整体来说,DPDK内存可以使用之前,会有以下一些流程
1)根据文件系统中的配置,初始化大页信息
2)结合大页信息进行大页映射,将虚拟地址与物理地址做关联,同时将大页关联到memseg
3)基于memseg,进行heap 申请,形成多个内存大小的 链表
memzone 是在heap 上进行申请的内存池,而mempool 就是具体的memzone 使用实例
接下来的章节也会对应以上三块进行展开,基于DPDK 19.11 进行代码分析
大页信息初始化
如下为大页信息结构
struct hugepage_info {
uint64_t hugepage_sz; /**< size of a huge page */
char hugedir[PATH_MAX]; /**< dir where hugetlbfs is mounted */
uint32_t num_pages[RTE_MAX_NUMA_NODES];
/**< number of hugepages of that size on each socket */
int lock_descriptor; /**< file descriptor for hugepage dir */
};
eal_hugepage_info_init 函数执行了对大页信息初始化操作,主要流程如下
1、读取 /sys/kernel/mm/hugepages 中的“hugepages-XXX”目录,最多读取 MAX_HUGEPAGE_SIZES个(ARM体系下为4,其它为3)。比如读取到 hugepages-2048kB ,将其中的 2048kB 转换为2048*1024,存入internal_config.hugepage_info[num_sizes].hugepage_sz, num_sizes< MAX_HUGEPAGE_SIZES
2、打开 /proc/meminfo 文件,读取 Hugepagesize 项的值,做为大页默认大小。(调用get_default_hp_size()函数)
3、打开 /proc/mounts 文件,找到类似 hugetlbfs /dev/hugepages hugetlbfs rw,relatime,pagesize=2M 0 0 或 nodev /dpdk_huge hugetlbfs rw,relatime,pagesize=2M 0 0 的行,进行切割,做文件挂载点检查、 文件系统类型确认及页大小确认,确认无误后存储挂载路径到internal_config.hugepage_info[num_sizes].hugedir (调用get_hugepage_dir() 函数)
4、锁定hugedir(flock)
5、打开 sys/kernel/mm/hugepages/hugepages-XXX 目录下面的 resv_hugepages 和 free_hugepages 文件,计算可用大页数量, 存入internal_config.hugepange_info->num_pages[0],这个0是socket id,在支持NUMA的系统中先在socket 0上进行操作 (调用calc_num_pages() 函数)
6、设置internal_config.num_hugepage_sizes数设置为num_sizes数
7、将上述过程发现的所有num_sizes个大页信息按从大到小排序,并检查至少有一个可用大页尺寸。
大页与Memseg关联
这块代码涉及比较多,其中又涉及静态模式(legacy_mem)和动态模式、in_memory 匿名映射等,一头扎进去看代码会非常崩溃,所以整理了这块逻辑一个代码结构图,便于理解,代码结构图的每个关键点都有注释说明。
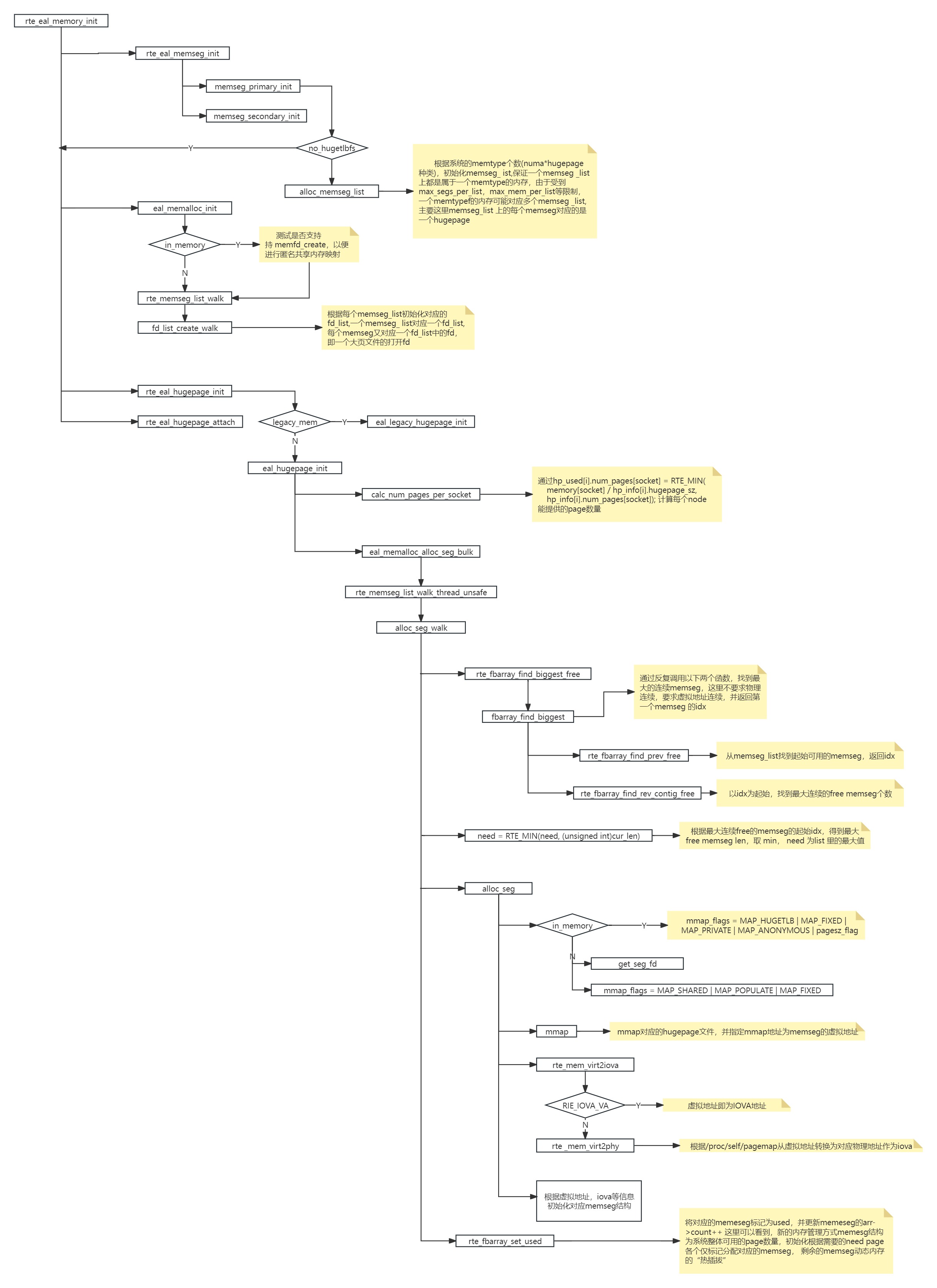
上边流程图中, eal_hugepage_init 为动态内存模式入口, eal_legacy_hugepage_init为静态内存模式入口。动态内存模式当前只在linux和window系统上支持。与动态内存模式相对应的是原有的lagecy模式(静态内存模式)。
DPDK 17.11及早期版本,一般应用程序启动会通过-m或--socket-mem参数指定应用程序使用的内存大小,之后DPDK应用程序就会reserve相应大小的内存,然后整个程序运行期间调用rte_malloc()或rte_memzone_reserve()等内存分配结构都是从这个reserve内存池中进行分配的,超过reserve内存的大小将无法分配。
但在动态内存模式下,应用程序可以不再需要通过-m或--socket-mem来预留内存,应用程序启动是完全可以不占用什么内存,当调用rte_malloc()或rte_memzone_reserve()等接口时动态的从系统中分配内存,并注册到DPDK的内存管理中,同样在调用释放内存接口时也会动态的将内存进行释放(从DPDK内存管理中删除)。这样应用程序可以不需要事先估算需要的内存大小,而采用按需分配,更加灵活(不过对于使用hugepage时,系统还是需要预留足够的hugepage)。
不过在动态内存模式情况下-m或--socket-mem参数仍然可以使用,但是其语义和lagecy模式有所不同,动态模式下-m或--socket-mem参数指定的是应用程序预留的最小内存。这部分内存应用程序不会释放,当需要申请更多的内存时应用程序可以超出这部分预留内存动态添加,为了可以限制应用程序所能使用的最大内存,动态内存提供了--socket-limit参数来指定当前socket所能使用的内存大小上限。
Heap 创建
rte_eal_malloc_heap_init 为heap创建函,主要实现的功能就是为memseg创建相应的内存管理结构。从以下代码可以看到,heap 是针队每一个node 有一份
int
rte_eal_malloc_heap_init(void)
{
......
if (rte_eal_process_type() == RTE_PROC_PRIMARY) {
/* assign min socket ID to external heaps */
mcfg->next_socket_id = EXTERNAL_HEAP_MIN_SOCKET_ID;
/* assign names to default DPDK heaps */
for (i = 0; i < rte_socket_count(); i++) {
struct malloc_heap *heap = &mcfg->malloc_heaps[i];
char heap_name[RTE_HEAP_NAME_MAX_LEN];
int socket_id = rte_socket_id_by_idx(i);
snprintf(heap_name, sizeof(heap_name),
"socket_%i", socket_id);
strlcpy(heap->name, heap_name, RTE_HEAP_NAME_MAX_LEN);
heap->socket_id = socket_id;
}
}
......
}从不同的memseg_list,找连续的memseg 段,传入回调函数进行head 创建
int
rte_memseg_contig_walk_thread_unsafe(rte_memseg_contig_walk_t func, void *arg)
{
struct rte_mem_config *mcfg = rte_eal_get_configuration()->mem_config;
int i, ms_idx, ret = 0;
for (i = 0; i < RTE_MAX_MEMSEG_LISTS; i++) {
struct rte_memseg_list *msl = &mcfg->memsegs[i];
const struct rte_memseg *ms;
struct rte_fbarray *arr;
if (msl->memseg_arr.count == 0)
continue;
arr = &msl->memseg_arr;
ms_idx = rte_fbarray_find_next_used(arr, 0);
while (ms_idx >= 0) {
int n_segs;
size_t len;
ms = rte_fbarray_get(arr, ms_idx);
/* find how many more segments there are, starting with
* this one.
*/
n_segs = rte_fbarray_find_contig_used(arr, ms_idx);
len = n_segs * msl->page_sz;
ret = func(msl, ms, len, arg);
if (ret)
return ret;
ms_idx = rte_fbarray_find_next_used(arr,
ms_idx + n_segs);
}
}
return 0;
}具体的heap 创建函数,可以看到,最后调用到malloc_elem_init 时,会把具体的heap、所属memseg_list 等更新到memseg 结构中
static int
malloc_add_seg(const struct rte_memseg_list *msl,
const struct rte_memseg *ms, size_t len, void *arg __rte_unused)
{
struct rte_mem_config *mcfg = rte_eal_get_configuration()->mem_config;
struct rte_memseg_list *found_msl;
struct malloc_heap *heap;
int msl_idx, heap_idx;
if (msl->external)
return 0;
heap_idx = malloc_socket_to_heap_id(msl->socket_id);
if (heap_idx < 0) {
RTE_LOG(ERR, EAL, "Memseg list has invalid socket id\n");
return -1;
}
heap = &mcfg->malloc_heaps[heap_idx];
/* msl is const, so find it */
msl_idx = msl - mcfg->memsegs;
if (msl_idx < 0 || msl_idx >= RTE_MAX_MEMSEG_LISTS)
return -1;
found_msl = &mcfg->memsegs[msl_idx];
malloc_heap_add_memory(heap, found_msl, ms->addr, len);
heap->total_size += len;
RTE_LOG(DEBUG, EAL, "Added %zuM to heap on socket %i\n", len >> 20,
msl->socket_id);
return 0;
}
static struct malloc_elem *
malloc_heap_add_memory(struct malloc_heap *heap, struct rte_memseg_list *msl,
void *start, size_t len)
{
struct malloc_elem *elem = start;
malloc_elem_init(elem, heap, msl, len, elem, len);
malloc_elem_insert(elem);
elem = malloc_elem_join_adjacent_free(elem);
malloc_elem_free_list_insert(elem);
return elem;
}
void
malloc_elem_init(struct malloc_elem *elem, struct malloc_heap *heap,
struct rte_memseg_list *msl, size_t size,
struct malloc_elem *orig_elem, size_t orig_size)
{
elem->heap = heap;
elem->msl = msl;
elem->prev = NULL;
elem->next = NULL;
memset(&elem->free_list, 0, sizeof(elem->free_list));
elem->state = ELEM_FREE;
elem->size = size;
elem->pad = 0;
elem->orig_elem = orig_elem;
elem->orig_size = orig_size;
set_header(elem);
set_trailer(elem);
}内存结构关联图
对照上边的几项梳理代码后,是不是基本对dpdk 的没存管理有一定印象了,这里整理了一个重要结构体的关联图,如果上边总结各位看官认真对照代码看了,再看这个关联图,基本就能把整体都贯通了
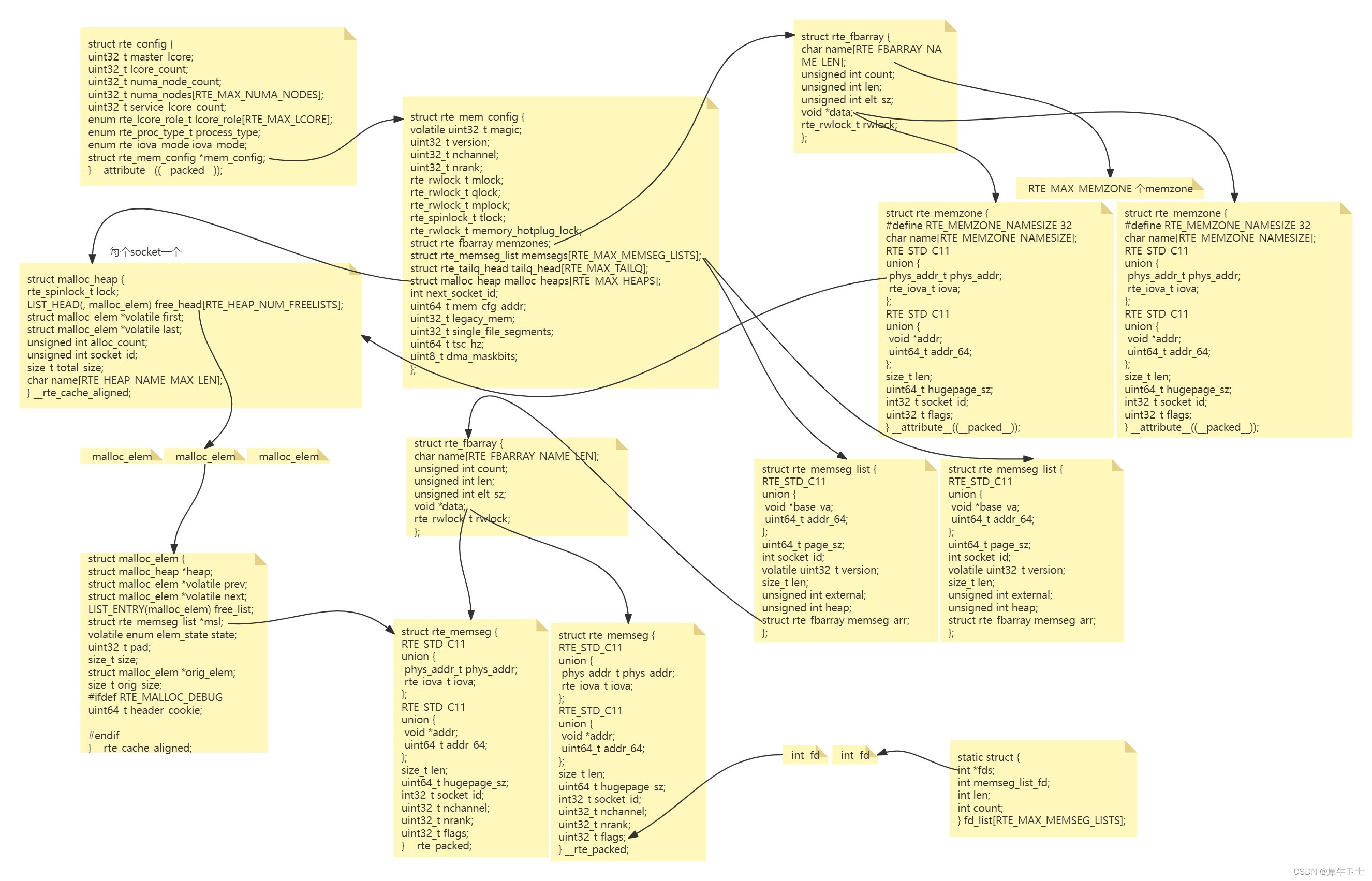
整个整理过程及其耗费心力,如果有纰漏的地方,还希望各位留言指正,让我们共同进步。
















 4030
4030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









