





在过去的20年中,对文档图像处理进行了大量研究,但是在并行处理方面没有进行太多研究。 建议用于并行处理的一些解决方案是为每个图像创建执行线程,或使用GNU Parallel 。
在此博客文章中,您将学习如何使用大数据平台并行处理图像。 该解决方案是为我们的一位医疗保健客户实施的,对医学图像进行了扫描并可以搜索以进行数据浏览。 为了从图像中提取文本,使用了称为Tesseract的光学字符识别(OCR)软件。 从图像文档中提取的文本存储在MapR平台上,以便快速检索。 该用例使用TIFF图像格式,该格式可以扩展并应用于其他类型的图像。
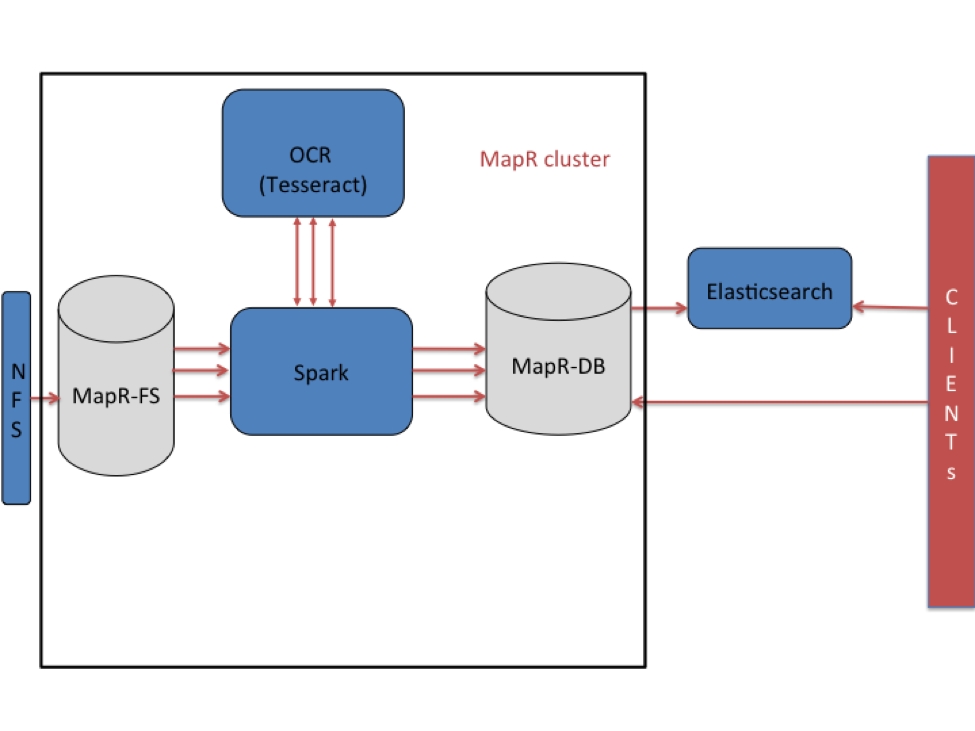
高层架构
在这种用例中,图像存储在MapR文件系统(MapR-FS)中,并使用Apache Spark和OCR软件进行处理。 通过NFS挂载将文件吸收到MapR-FS中。 一旦将文件提取到MapR-FS中,就可以对其进行串行读取和处理。 为了并行处理,使用了Spark框架。 使用Tesseract提取嵌入的文本,然后将提取的文本填充到MapR-DB中。 Tesseract是一种开源OCR引擎,最初是由HP Labs开发的,后来以开源软件的形式发布,并由Google赞助。 根据我的研究,Tesseract是可用于OCR的最准确的开源库。
使用MapR 5.0版时,可以在Elasticsearch中创建MapR-DB中列,列族或整个表的外部搜索索引。 通过Elasticsearch复制启用MapR-DB中的表,以便将数据插入表中并在Elasticsearch中建立索引。 也就是说,提取的文本和存储在MapR-DB表中的元数据将在Elasticsearch中自动复制并建立索引。 由于MapR-DB的宽列数据模型本身支持多种版本的数据,因此MapR-DB中可以存储文档的多种版本。 在Elasticsearch中索引了MapR-DB表中的最新版本。
Tesseract安装
在Linux机器上,以“ root”身份登录并按照以下说明进行操作:
#yum install tesseract
#yum install leptonica
MapR-DB表架构描述
该表的架构很简单。 行键由文档ID组成,该ID是不带后缀的文件名。 有一个列族“ cf”和两个列,即“ info”和“ data”。 第一个用于存储元数据,另一个用于提取文本。 文件路径将存储在“ info”列中。 客户端将能够使用Elasticsearch索引中的文本和元数据进行搜索。 找到记录后,就可以使用原始文档的文件路径来检索整个文档。
MapR-DB表创建
可以使用Java API或HBase Shell以编程方式创建表。 以下是使用Shell的说明:
$ hbase shell
hbase(main):001:0> create '/user/user01/datatable', 'cf'其中“ / user / user01 / datatable”是数据表的路径,“ cf”是具有默认版本号的列系列。
从Elastic.co下载来安装Elasticsearch。
$ /opt/mapr/bin/register-elasticsearch -r localhost -e /opt/mapr/QSS/miner/elasticsearch-2.2.0 -u mapr -y -c maprdemoes
$ /opt/mapr/bin/register-elasticsearch -l
$ maprcli table replica elasticsearch autosetup -path /srctable -target maprdemoes -index sourcedoc -type json开源Tesseract使用Leptonica图像处理库。 要读取图像,处理和存储文档, 下载源代码 ,构建它并运行程序。 Java中的Spark代码如下所示读取二进制文件。
读取图像文件
为了读取图像,在JavaStreamingContext上调用binaryFiles()API。 该API仅读取二进制图像文件; 读取后,将在processFile()方法中处理每个文件。
JavaPairRDD<String, PortableDataStream> readRDD = jsc.binaryFiles(inputPath);
readRDD.map(new Function<Tuple2<String, PortableDataStream>, String>() {
@Override
public String call(Tuple2<String, PortableDataStream> pair) {
String fileName = StringUtils.remove(pair._2.getPath(), "maprfs://");
processFile(StringUtils.remove(fileName, "file:"));
return null;
}
}).collect();在“ processFile”方法中,将调用Tesseract API来提取文本。 这里的文档是英文的,因此API设置为“ eng”。
public static String processImageFile(String fileName) {
Tesseract instance = new Tesseract();
File imageFile = new File(fileName);
String resultText = null;
instance.setLanguage("eng");
try {
resultText = instance.doOCR(imageFile);
} catch (Exception e) {
e.printStackTrace();
} finally {
return resultText;
}
}提取文本后,通过调用方法populateDataInMapRDB()将其存储在MapR-DB中。 此处,数据存储在列系列“ cf”和列“ data”中。 文件(文件名)的元数据存储在“信息”列中。 如果有更多数据需要索引,则可以将其填充在其他列限定符下。
populateDataInMapRDB(config, convertedTable, rowKey, cf, "data", resultText);
populateDataInMapRDB(config, convertedTable, rowKey, cf, "info", fileName);运行应用程序
- 从此处下载代码和示例数据:
git clone https://github.com/ranjitreddy2013/imageprocessing
- 使用maven生成应用程序:
mvn全新安装
- 将位于示例目录中的示例图像文件复制到正在读取Spark程序的目录中。 请参阅程序中binaryFiles()api中设置的inputPath。
- 调用Spark程序:
${SPARK_HOME}/bin/spark-submit --class com.mapr.ocr.text.ImageToText --conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=log4j-spark.properties" --master local[4]document-store-0.0.1-SNAPSHOT-jar-with-dependencies.jar程序完成执行后,应在Elasticsearch中复制数据并建立索引。
从Elasticsearch访问索引文本:
运行以下查询以在Elasticsearch中提取文档:
curl -XGET "http://maprdemo:9200/medicaldoc/json/_search" -d'
{
"query": {
"match": {
"cf.info": "quick"
}},
"fields" : ["_id", "cf.filepath", "cf.info"]
}' | python -m json.tool结论
在此博客中,您了解了如何使用OCR软件使用Spark扫描图像文档。 您还了解了提取的文本如何存储在MapR-DB中。 在MapR-DB表上启用Elasticsearch复制后,将数据加载到表中时,数据索引将自动进行。 这使得提取文本的可搜索性非常易于管理。 它简化了处理流程,这对于要处理的图像量不断增长的环境非常重要。
翻译自: https://www.javacodegeeks.com/2017/01/processing-image-documents-mapr-scale.html















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









