





对警报线程池的警报线程
确保您的警报有意义且不仅仅是噪音的最终警报策略是什么?
生产监视对于应用程序的成功至关重要。 从手动查看日志,通过使用第三方工具或本地解决方案–到我们每个人都有。 但是,无论它们是什么,都有一些元素和准则可以帮助我们充分利用我们的监视技术。
为了帮助您开发更好的工作流程,我们确定了警报应具有的重要意义。 糖,香料和所有监控物。 让我们检查一下。
目录
1.及时性–知道一旦发生不良情况
我们的应用程序和服务器始终处于运行状态,并且在任何时刻都在发生很多事情。 这就是为什么在新错误首次引入系统时,紧跟新错误的重要性。
即使您喜欢浏览日志文件,它们也只会使您回顾应用程序,服务器或用户的情况。 有人会说时间就是一切,实时获取警报对于您的业务至关重要。 我们希望在问题严重影响用户或我们的应用程序之前予以解决。
这是第三方工具和集成的宝贵之处,可在发生任何事情时立即通知我们。 当警报在03:00 AM或夜间外出时,此概念听起来可能不太好,但我们不能否认其重要性。

“一切都很好”
TL; DR –在生产环境中,每一秒都很重要,您想知道何时引入错误。
2.背景是理解问题的关键
知道何时发生错误很重要,下一步是了解错误发生的位置。 xMatters的高级Java开发人员Aleksey Vorona告诉我们,对于他的公司而言,上下文是警报的最重要组成部分。 “一旦在应用程序中引入错误,您就希望拥有尽可能多的信息,以便您能够理解它。 此上下文可以是运行应用程序的计算机,用户ID和拥有该错误的开发人员。 您拥有的信息越多,越容易理解该问题。”
上下文就是一切。 当涉及到警报时,它与不同的值和元素有关,可以帮助您准确了解发生了什么。 例如,如果您知道新部署是否引入了新错误,或者在记录的错误或未捕获的异常数超过特定阈值时获得警报,将使您受益。 您还需要知道某个错误是新的还是重复发生的,是什么使它出现或再次出现。
进一步细分,我们希望在每个错误中看到5个关键值:
- 系统中出现了什么错误
- 当它发生在代码中
- 多少次发生的每个错误,什么是它的紧迫性
- 什么时候第一次看到此错误
- 当是最后一次发生这种错误
这些是我们在OverOps上必须面对的一些问题,试图帮助开发人员,经理和DevOps团队自动化其手动错误处理流程。 由于每个团队都有自己独特的处理问题的方式,我们创建了可自定义的仪表板,您可以在其中快速查看每个错误的前5个值。 OverOps使您可以快速识别关键错误,了解它们在代码中发生的位置,并知道它们是否为关键错误。
TL; DR –您需要知道什么,在哪里,发生多少错误以及何时发生错误和异常,以了解其重要性和紧迫性。
3.根本原因检测–为什么首先发生?
现在,我们正在以适当的上下文获取实时警报,是时候该理解为什么它们首先发生了。 对于大多数工程团队而言,这将是时候查看日志文件并开始在我们的日志干草堆中搜索该针了。 也就是说,如果错误是首先记录的。 但是,我们看到表现最好的团队的做事方式有所不同。 完整的研究将在10月25日我们即将举行的网络研讨会上分享。 检查一下 。
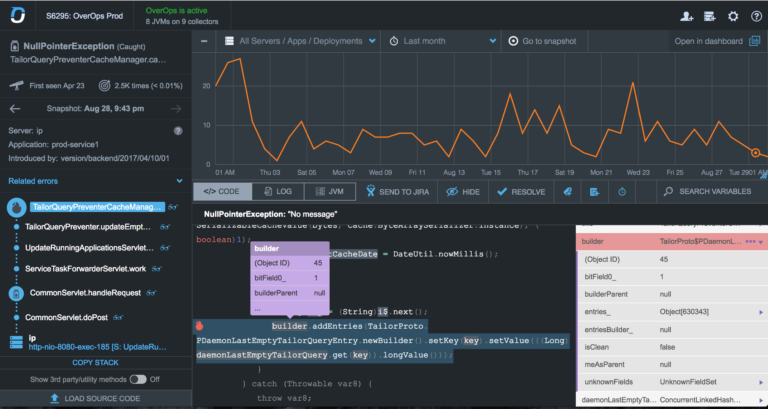
OverOps自动根本原因(ARC)–整个调用堆栈中的完整源代码和变量状态
通常,应用程序每天会引发成千上万甚至数百万个错误,而要以一种可扩展的方式扎根其真实根源而又又不会浪费大量的时间去寻找它,这是一个真正的挑战。 对于像Intuit这样的大公司,搜索日志没有帮助; Intuit的质量首席工程师Sumit Nagal指出:“即使我们确实在原木中发现了问题,但其中一些还是不可复制的。 在这些领域中寻找,复制和解决问题是一个真正的挑战。”
Intuit选择使用OverOps ,而不是浏览试图查找关键问题的日志并用标有“无法复制”的标签来关闭票证。 借助OverOps,开发团队能够立即确定每个异常的原因以及引起异常的变量。 该公司只需单击一下,便可以找到根本原因,从而大大提高了开发团队的工作效率。
TL; DR –找出根本原因以及完整的源代码和变量,将帮助您理解为什么首先发生错误。
4.沟通–使团队保持同步
没有开发团队中的所有人,您就无法处理警报。 因此,在警报方面,沟通是关键所在。 首先,将警报分配给合适的人很重要。 团队都应该在同一个页面上,知道他们每个人负责什么以及谁在处理应用程序的哪个元素。
一些团队可能认为此过程不如应有的重要,他们分配不同的团队成员仅在“离开”后才处理警报。 但是,这是一种不好的做法,并且可能不如某些人希望的那样有效。
想象以下情况:这是一个星期六晚上,应用程序崩溃了。 警报已发送给公司中的各个人员,一些团队成员正试图提供帮助。 但是,他们没有处理应用程序或代码的那部分。 现在,您有7个团队成员试图互相交谈,试图了解解决该问题需要做什么。
这是由于项目早期部分缺乏沟通,导致团队成员在发出警报时不知道负责人,部署了什么或如何处理事件。

TL; DR –沟通很重要,在错误处理过程中,您应该努力使其变得更好。
5.问责制–确保由正确的人来处理警报
继续上一节中的交流主题,此概念的重要组成部分是知道警报已到达正确的人,并且他/她正在照顾它。 我们可能知道哪个团队成员是代码破译之前最后处理代码的人,但是他现在是负责修改代码的人吗?
在接受我们采访时,Aleksey Vorona指出,对于他而言,重要的是要知道谁是每个出现警报或问题的负责人。 编写代码的人比团队的其他成员更有可能更好地处理它,并且与其他人相比,他最有可能应用更快的修复程序。
最重要的是,只要知道谁在做什么,您做什么都不重要。 否则,您的警报可能会堆积起来,并且需要一段时间才能从已知问题中筛选出关键警报,这将导致用户不满意,性能问题甚至服务器和系统完全崩溃。
TL; DR –团队成员应对整个开发过程中的代码负责,即使代码已交付生产。
6.处理–警报处理周期
您的团队成员之间进行了交流和合作,这很棒。 但是,您仍然需要创建团队渴望实现的游戏计划。 游戏计划的一个很好的例子是拥有明智的异常处理策略,而不是孤立地处理每个事件。
异常是生产环境的核心要素之一,它们通常表示警告信号,需要引起注意。 当异常被滥用时,它们可能会导致性能问题,在您不知情的情况下伤害应用程序及其用户。
您如何防止它发生? 一种方法是在公司中实施“收件箱零”政策的“游戏计划”。 在此过程中,我们会在引入独特异常后立即对其进行处理,确认,妥善处理并最终消除它们。
我们研究了公司如何处理其例外情况,发现有些公司倾向于在“较晚的”日期对待它们,就像电子邮件一样。 我们发现实施零收件箱政策的公司对他们的应用程序如何工作有更好的了解,更清晰的日志文件以及开发人员可以将精力集中在重要的项目和新的项目上。 阅读更多关于它 。
TL; DR –为您找到正确的游戏计划,并将其实施为更好的警报处理流程的一部分。
是的,请
自行处理警报可能会起作用,但是从长远来看,它无法扩展。 对于服务超过2300万X1 XFINITY设备的康卡斯特(Comcast)这样的公司,几乎不可能知道哪些警报至关重要,应尽快处理。 在这里,第三方工具和集成将是您最好的朋友。
将OverOps与他们的自动部署模型集成之后,Comcast能够对他们的应用服务器进行检测。 该公司每周都会部署其应用程序的新版本,而OverOps可以帮助他们确定Comcast并未预见到的未知错误情况。 观看 Comcast Cable产品工程执行总监John McCann的影片,了解OverOps如何帮助公司自动化其部署。
集成在您当前的警报工作流程中也可能会有所帮助。 例如,xMatters的Aleksey Vorona致力于开发用于IT警报的统一平台,并开发了与OverOps的集成 。 通过集成,公司可以访问关键信息,例如导致每个错误的变量状态,并向合适的团队成员发出警报。
TL; DR –使用第三方工具和集成来增强您的警报并使它们有意义。
最后的想法
警报很重要,但是它不仅仅具有将警报添加到您的应用程序中的功能。 您想确保您首先了解它们发生的原因,如何处理它们以及如何充分利用它们的信息(相对于仅知道发生了一些不好的事情)。 我们的基本配方旨在帮助您创建更好的流程,并在等待您添加对您的团队,公司和工作流程至关重要的特殊成分。
您最需要注意的是什么? 我们希望在下面的评论中听到有关它们的信息。
对警报线程池的警报线程















 109
109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









