







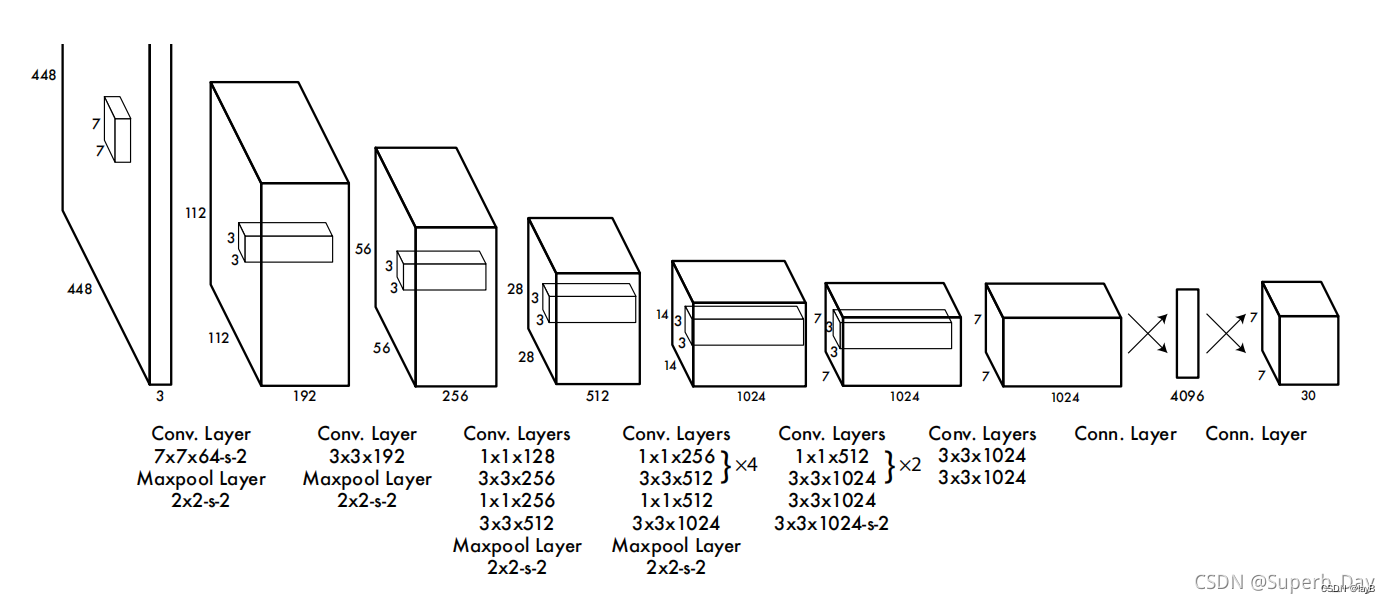
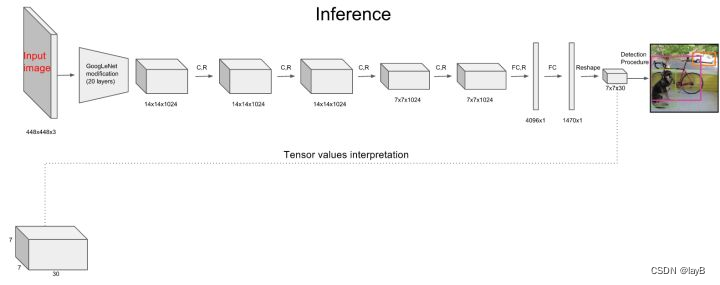
网络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )
参考链接
1.第一层卷积层: 7 7 7 × × × 7 7 7 × × × 1 每个通道64个卷积核 -s- 2
过滤器可以看做是卷积核的集合。
一个过滤器就对应一个特征图。
卷积后深度与卷积核的个数一致

64是卷积核filter的深度
第一层通道3(RGB)通过深度64的过滤器扩展为192(3×64)的张量。
-s- 是stride参数 步长
Maxpool.Layer的意思是池化层 2$×$2 stride是2 的池化层
原图式:n x n
卷积核: f x f
padding(边框补充): p
stride :s 此处s=2
输出图像像素表达式:[(n+2p-f)/s +1] x [(n+2p-f)/s +1] 如果计算出不是整数,则向下取整
则上述是 (448/2) x (448/2) = 224 x 224,
再经过最大池化 (224/2 x (224/2) = 112 x 112
所以得到一个 112 x 112 x 192 的张量
2.第二层卷积层:
3
3
3
×
×
×
3
3
3
×
×
× 192 步长默认为1
经过 2
×
×
× 2 步长为2的池化层
112/2
×
×
× 112/2 = 56
×
×
× 56
有256个卷积核所以生成深度256的张量
经过一系列操作之后,得到了一个771024的数据。
进行两层全连接:拉平放入一个有4096个神经元的全连接层中,输出4096维的向量,然后又导入有1470个神经元的全连接层中,输出1470维的向量,然后改变一下形式,变成最后的7
×
×
× 7
×
×
× 30(2*5+20)。
训练
然后这个7
×
×
× 7
×
×
× 30的张量用损失函数进行训练。
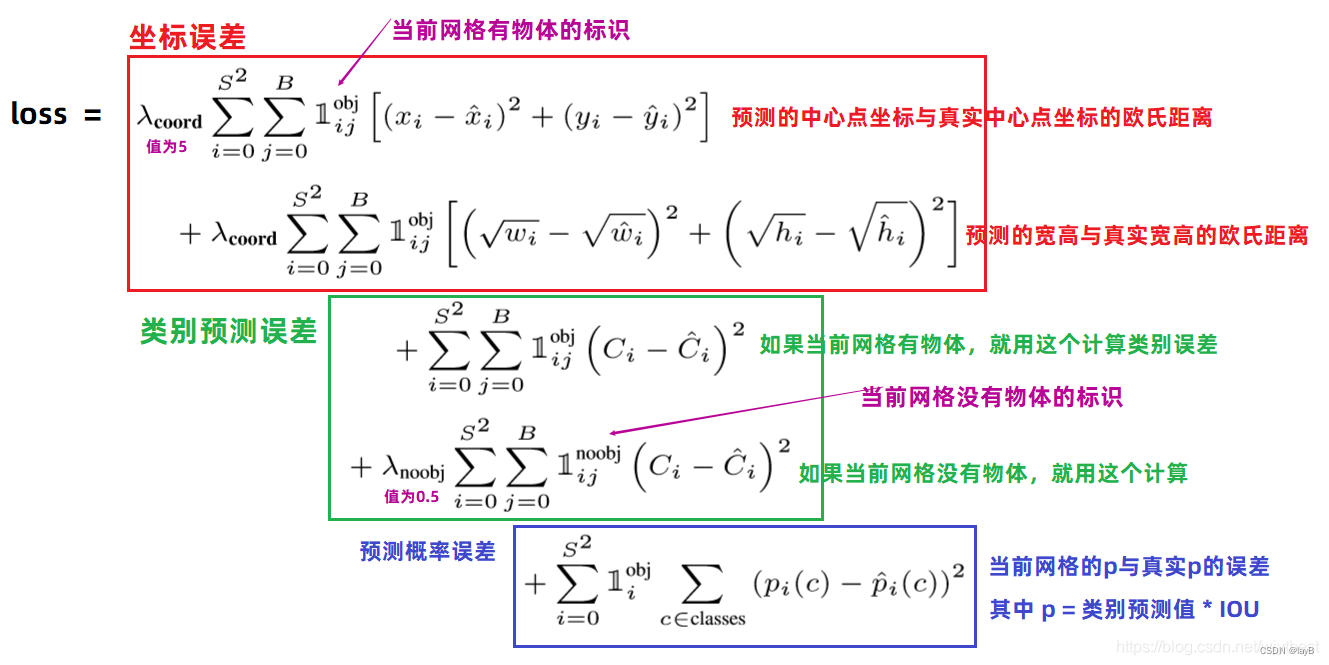
参数设置:
对坐标预测,给这些损失前面赋予更大的loss weight, 记为 λcoord ,在pascal VOC训练中取5。(上图蓝色框)
对没有object的bbox的confidence loss,赋予小的loss weight,记为 λnoobj ,在pascal VOC训练中取0.5。(上图橙色框)
有object的bbox的confidence loss (上图红色框) 和类别的loss(上图紫色框)的loss weight正常取1。
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏相同的尺寸对IOU的影响更大。而sum-square error loss中对同样的偏移loss是一样。为了缓和这个问题,作者用了一个巧妙的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。
在 YOLO中,每个栅格预测多个bounding box,但在网络模型的训练中,希望每一个物体最后由一个bounding box predictor来负责预测。因此,当前哪一个predictor预测的bounding box与ground truth box的IOU最大,这个predictor就负责predict object。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









