







 YOLO v1 是一种快速的one-stage目标检测算法,无需RPN网络,能实现端到端训练。通过直接回归Bounding Box并预测类别,YOLO v1提供实时检测速度,尤其适用于视频应用。网络结构包括卷积、池化和全连接层,输入固定尺寸,输出7x7x30张量,每个网格预测2个BoundingBox和概率。训练时,通过IOU动态选择负责预测的对象,并使用特定损失函数优化。
YOLO v1 是一种快速的one-stage目标检测算法,无需RPN网络,能实现端到端训练。通过直接回归Bounding Box并预测类别,YOLO v1提供实时检测速度,尤其适用于视频应用。网络结构包括卷积、池化和全连接层,输入固定尺寸,输出7x7x30张量,每个网格预测2个BoundingBox和概率。训练时,通过IOU动态选择负责预测的对象,并使用特定损失函数优化。
YOLO v1 详解
You Only Look Once: Unified, Real-Time Object Detection
YOLO v1 是典型的 one-stage 的算法。相对于 Faster R-CNN,YOLO v1 不需要分别训练各个部分的网络,可以实现 end-to-end 的训练。YOLO v1 有着更高的检测速度,可以用于视频的检测。

图 1:Bounding Box 回归和最终类别的关系。
人类只用看一眼图片就能大体了解到在各个方位有哪些感兴趣的物体。而对比 Faster R-CNN,我们实际上看了 2 眼图片。那么有没有一种方法能让我们只看 1 眼,并且快速定位物体呢?YOLO v1 就是这样。YOLO v1 的核心思想是直接对 Bounding Box 进行回归然后进行类别的预测。 换句话说 Bounding Box 的回归和最终物体的类别是有很大的关系的。例如图一,我们只用看第一幅图,就能想到猫的耳朵和屁股的大致位置。
对于 Faster R-CNN,第一步我们要生成大量的 anchor,用于 RPN 网络判断 objectness 和边框的微调。那么既然最后会调整 anchor 的边界框,我们就没有必要生成那么多的 anchor,只生成大致的区域就行。类比 YOLO v1,我们在一开始生成少量的预测区域(在 YOLO v1 中没有 anchor)后直接对预测区域进行微调,并给出其对应的物体类别,就可以得到最终的输出结果。这样的方法,要比 Faster R-CNN 速度快很多。
一、网络详解

图 2:详细的网络结构
(一)网络结构

图 3:YOLO v1 的网络大体结构
去掉生成 region proposals 这个步骤以后,YOLO v1的结构非常简单,就是单纯的卷积、池化最后加了两层全连接。单看网络结构的话,和普通的 CNN 对象分类网络几乎没有本质的区别,最大的差异是最后输出层用线性函数做激活函数,因为需要预测 bounding box 的位置(数值型),而不仅仅是对象的概率。所以粗略来说,YOLO 的整个结构就是输入图片经过神经网络的变换得到一个输出的张量,如图 3 所示。
因为只是一些常规的神经网络结构,所以,理解 YOLO v1 的设计的时候,重要的是理解输入和输出的映射关系。
(二)输入
对于输入,我们将常见网络输入的 224 x 224 的大小放大 2 倍,采用固定的尺度 448 x 448。
(三)输出
网络的输出为 7 x 7 x 30 的张量,那么这 7 x 7 x 30 的输出代表什么含义呢?我们分别来看一看。
1. 7 x 7 部分
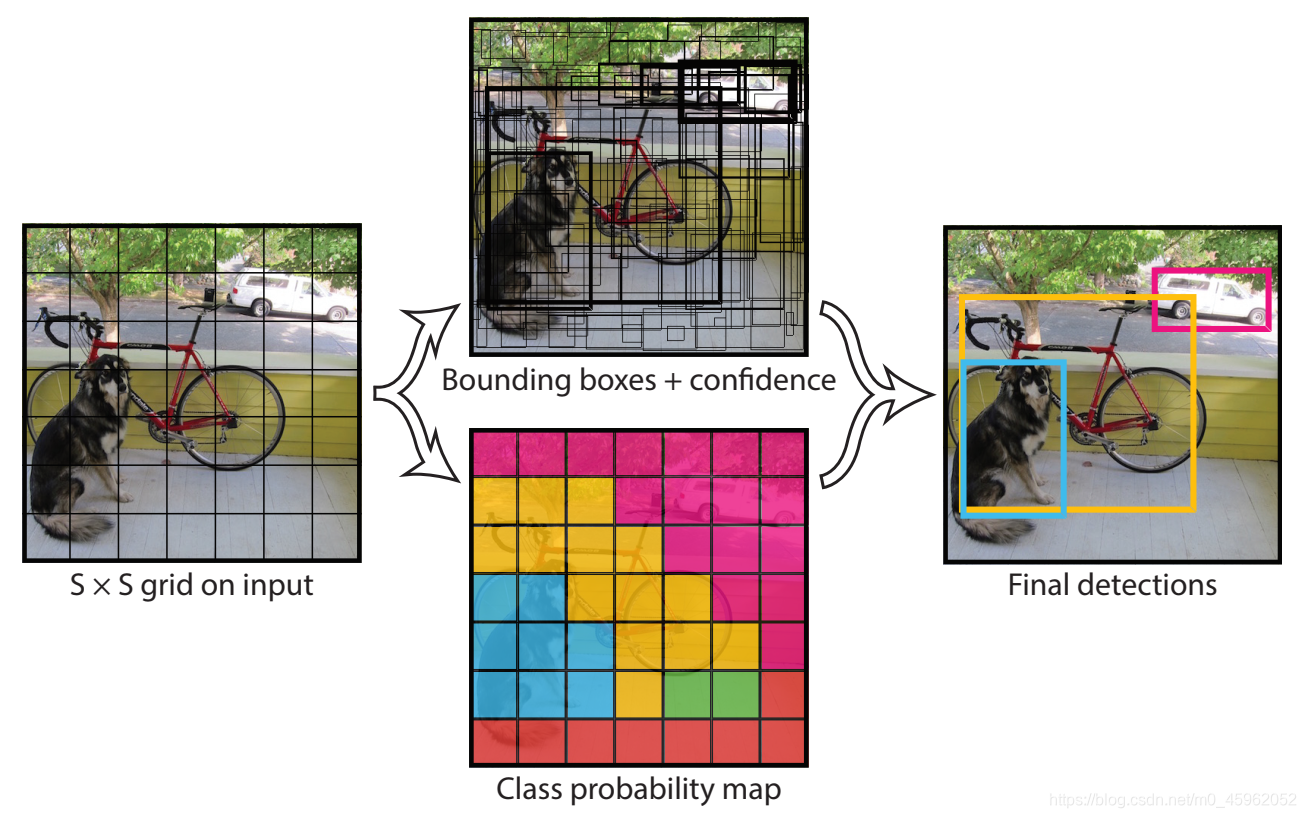
图 4:YOLO v1 的步骤
对于 YOLO v1,当图片输入网络时我们先要将输入图片平均分成 S x S 个大小相同的网格(见上图)。然后对每个网格生成 B 个 Bounding Box,这个生成的 Bounding Box 就是我们最终要输出的 Bounding Box。所以生成的总 Bounding Box 的个数为 S × S × B S \times S \times B S×S×B 。
需要理解的是,这个 Bounding Box 并不是 Faster R-CNN 中的 anchor。Faster RCNN 等一些算法采用每个 grid 中手工设置 n 个 Anchor(先验框,预先设置好位置的 bounding box)的设计,每个 Anchor 有不同的大小和宽高比。YOLO 的 bounding box 看起来很像一个 grid 中 2 个 Anchor,但它们不是。YOLO 并没有预先设置 2 个 bounding box 的大小和形状,也没有对每个 bounding box 分别输出一个对象的预测。它的意思仅仅是对一个对象预测出 2 个 bounding box,在训练只选择预测得相对比较准的那个。
这里的 bounding box,有点像不完全算监督算法,而是像进化算法。如果是监督算法,我们需要事先根据样本就能给出一个正确的 bounding box 作为回归的目标。但 YOLO 的 2 个 bounding box 事先并不知道会在什么位置,只有经过前向计算,网络会输出 2 个 bounding box,这两个 bounding box 与样本中对象实际的 bounding box 计算 IOU。这时才能确定,IOU 值大的那个 bounding box,作为负责预测该对象的 bounding box。
训练开始阶段,网络预测的 bounding box 可能都是乱来的,但总是选择 IOU 相对好一些的那个,随着训练的进行,每个 bounding box 会逐渐擅长对某些情况的预测(可能是对象大小、宽高比、不同类型的对象等)。所以,这是一种进化或者非监督学习的思想。
这里作者使用的 S = 7、B = 2。输出张量中的 7 x 7 个值就对应着输入图像的 7 x 7 网格。或者我们把 7 x 7 x 30 的张量看作 7 x 7 = 49 个 30 维的向量,也就是输入图像中的每个网格对应输出一个 30 维的向量(见下图)

图 5:对于原始图像中的每个网格都对应最终结果的一行输出。
2. 30 通道部分

图 6:30 个通道的含义
30 个通道包含了如下 3 个部分:
(1)20 个对象分类的概率
因为 YOLO 支持识别 20 种不同的对象(人、鸟、猫、汽车、椅子等),所以这里有 20 个值表示该网格位置存在任一种对象的概率。可以记为 P ( C 1 ∣ O b j e c t ) , . . . , P ( C i ∣ O b j e c t ) , . . . , P ( C 20 ∣ O b j e c t ) P(C_1|Object),...,P(C_i|Object),...,P(C_{20}|Object) P(C1∣Object),...,P(Ci∣Object),...,P(C20∣Object) 。之所以写成条件概率,意思是如果该网格存在一个对象 Object,那么它是 C i C_i Ci 类别的概率为 P ( C i ∣ O b j e c t ) P(C_i|Object) P(Ci
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1412
1412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









