







论文名称《You Only Look Once: Unified, Real-Time Object Detection》
摘要
1、之前的目标检测方法采用目标分类思想解决检测问题,本文提出一个基于回归的框架,用于目标的定位及识别。
2、一个网络,一次预测即可获得目标的检测框(bounding boxs)和 类别概率。
3、所提目标检测框架运算速度非常快。基本YOLO 模型45帧/S。简化版本Fast YOLO模型可达到155F/s.
4、相比其他检测器,yolo定位误差较大,但是flase positive 较少。
5、YOLO泛化能力较高。
1、引言
1、现有目标检测框架典型的有滑窗检测(如 DPM算法)和Region proposal方式(如 RCNN)。
2、YOLO将目标检测是为回归问题。通过像素值直接预测bboxes和类别概率。
3、YOLO通过全图训练网络,并优化检测器性能,该方式有如下优势:
1)YOLO fast.因为基于回归的框架简单,不需要额外复杂流程
2)YOLO 检测目标时,利用全图信息。与滑窗和基于候选框的检测技术不同,YOLO在训练及检测的时候不仅利用目标特征还学习上下文信息。Faster RCNN产生虚警的愿意是没用利用上下文信息。
3)YOLO学习泛化的目标信息。
在精度上相差很多。
2、统一的检测器
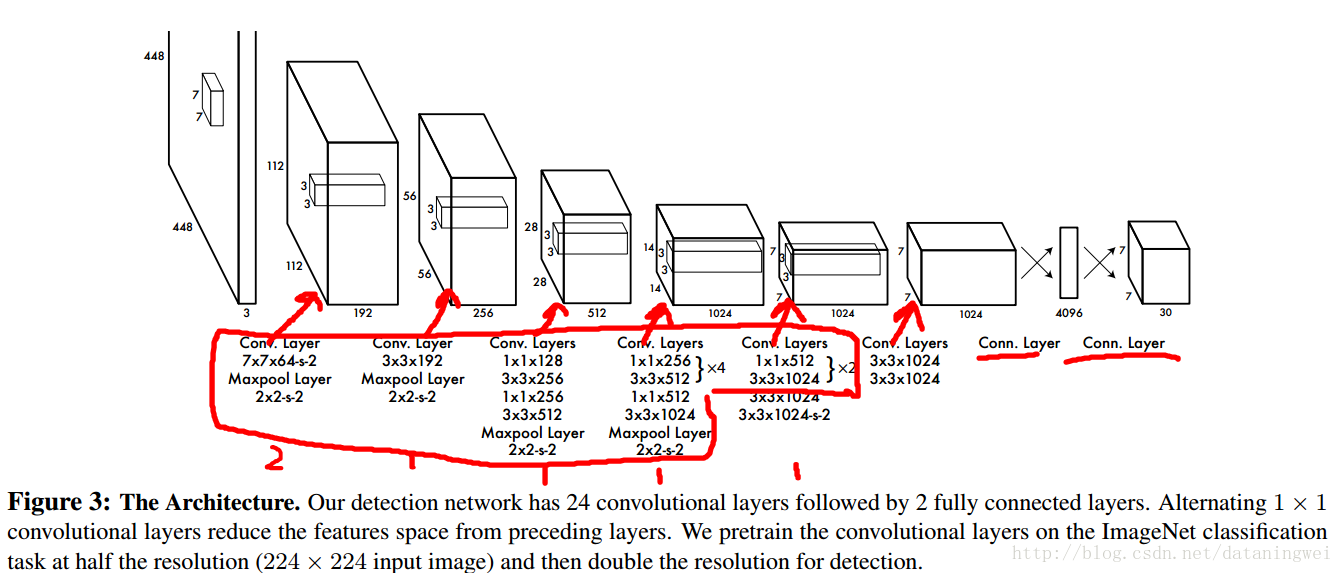
2.1网络设计:特征提取层+额外分类检测层
- 受GoogleLetnet 网络设计启发。(脑补一下:googleLenet共22层,考虑pooling 层,共27层。后接平均池化层,并送入分类器)GoogleLetNet链接
- YOLO网络设计共24层卷积层,后接2层全链接层。
- 预训练对前20层进行分类训练(参考GoogleNet ,修改 *1、*3组合)。后面4个卷积层和2个全链接层用于检测。预训练图像尺寸用224*224(imageNet 图像集)
- 检测图像输入尺寸变尺寸至448*448。
2.2 关键点设计
- 将输入图像分为 S∗S 个grid cell,目标中心所在的 cell,负责对此目标的检测及识别。
- 每个cell预测B个 bboxes和相应的置信度 confidence=Pr(object)∗IOUtruthpred 。如果没目标 Pr(object)=0 ,confidence为0,有目标 Pr(object)=1 ,则confidence为IOU值。(预测阶段咋整?)
- 每个bboxes 包含5个参数: x,y,w,h 和置信度 confidence 。其中 (x,y) 坐标代表所检测目标的中心点,该值是相对于grid cell的边缘,因此取值范围【0,1】。 w,h 相对于整个图像尺寸,取值范围【0,1】。
- 目标。
2.3 训练
从网络图可以看出,448图像输入,经过6次pooling,图像大小变为 448/2^6=448/64=7
网格设置S=7是否与最终输出的featureMap大小有关?
输出大小 为7*7*(2*5+20)=7*7*30=1470,每一个点都是前一层向量回归而来(全链接,内积计算预测)。
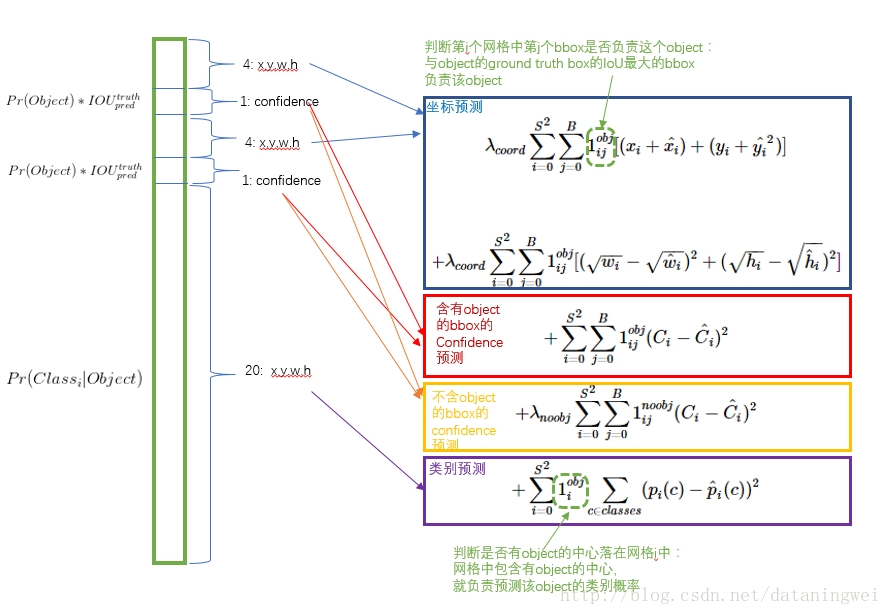
训练误差采用均方差。考虑存在目标的(坐标预测误差、置信度误差、类别误差)+不是目标的置信度。
训练中的误差函数如下,加重有目标的位置比重 λcoord=5 ,不是目标的置信度 λnoobj=0.5 。

2.4 测试
Test的时候,每个网格预测的class信息
(Pr(Classi|Object))
和bounding box预测的confidence信息(
Pr(Object)∗IOUtruthpred
) 相乘。
说白了,就是预测置信度与类别概率的乘积。
参考博客:https://zhuanlan.zhihu.com/p/24916786?refer=xiaoleimlnote 写的很明了。















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









