







为了获得较高的内存带宽,共享存储器被划分为多个大小相等的存储器模块,称为bank,可以被同时访问。因此任何跨越b个不同的内存bank的对n个地址进行读取和写入的操作可以被同时进行,这样就大大提高了整体带宽 ——可达到单独一个bank带宽的b倍。但是很多情况下,我们无法充分发挥bank的功能,以致于shared memory的带宽非常的小,这可能是因为我们遇到了bank冲突。
bank冲突
当一个warp中的不同线程访问一个bank中的不同的字地址时,就会发生bank冲突。
如果没有bank冲突的话,共享内存的访存速度将会非常的快,大约比全局内存的访问延迟低100多倍,但是速度没有寄存器快。然而,如果在使用共享内存时发生了bank冲突的话,性能将会降低很多很多。在最坏的情况下,即一个warp中的所有线程访问了相同bank的32个不同字地址的话,那么这32个访问操作将会全部被序列化,大大降低了内存带宽。
NOTE:不同warp中的线程之间不存在什么bank冲突。
共享内存的地址映射方式
要解决bank冲突,首先我们要了解一下共享内存的地址映射方式。
在共享内存中,连续的32-bits字被分配到连续的32个bank中,这就像电影院的座位一样:一列的座位就相当于一个bank,所以每行有32个座位,在每个座位上可以“坐”一个32-bits的数据(或者多个小于32-bits的数据,如4个char型的数据,2个short型的数据);而正常情况下,我们是按照先坐完一行再坐下一行的顺序来坐座位的,在shared memory中地址映射的方式也是这样的。下图中内存地址是按照箭头的方向依次映射的:

bank_layout
上图中数字为bank编号。这样的话,如果你将申请一个共享内存数组(假设是int类型)的话,那么你的每个元素所对应的bank编号就是地址偏移量(也就是数组下标)对32取余所得的结果,比如大小为1024的一维数组myShMem:
- myShMem[4]: 对应的bank id为#4 (相应的行偏移量为0)
- myShMem[31]: 对应的bank id为#31 (相应的行偏移量为0)
- myShMem[50]: 对应的bank id为#18 (相应的行偏移量为1)
- myShMem[128]: 对应的bank id为#0 (相应的行偏移量为4)
- myShMem[178]: 对应的bank id为#18 (相应的行偏移量为5)
典型的bank访问方式
下面我介绍几种典型的bank访问的形式。
下面这这种访问方式是典型的线性访问方式(访问步长(stride)为1),由于每个warp中的线程ID与每个bank的ID一一对应,因此不会产生bank冲突。
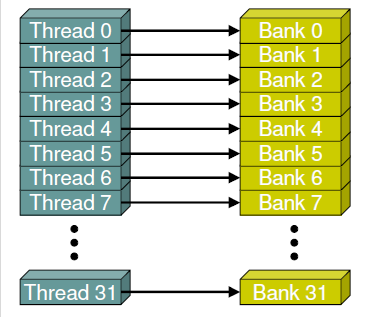
无冲突的线性访问方式
下面这种访问虽然是交叉的访问,每个线程并没有与bank一一对应,但每个线程都会对应一个唯一的bank,所以也不会产生bank冲突。

无冲突的交叉访问方式
下面这种虽然也是线性的访问bank,但这种访问方式与第一种的区别在于访问的步长(stride)变为2,这就造成了线程0与线程28都访问到了bank 0,线程1与线程29都访问到了bank 2...,于是就造成了2路的bank冲突。我在后面会对以不同的步长(stride)访问bank的情况做进一步讨论。
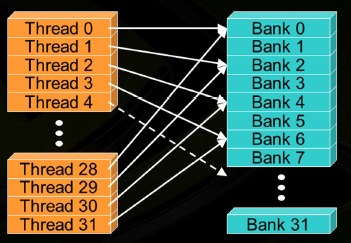
有冲突的线性访问方式
下面这种访问造成了8路的bank冲突,

8路访问冲突
这里我们需要注意,下面这两种情况是两种特殊情况:

特殊情况1
上图中,所有的线程都访问了同一个bank,貌似产生了32路的bank冲突,但是由于广播(broadcast)机制(当一个warp中的所有线程访问一个bank中的同一个字(word)地址时,就会向所有的线程广播这个字(word)),这种情况并不会发生bank冲突。
同样,这种访问方式也不会产生bank冲突:

特殊情况2
这就是所谓的多播机制(multicast)——当一个warp中的几个线程访问同一个bank中的相同字地址时,会将该字广播给这些线程。
NOTE:这里的多播机制(multicast)只适用于计算能力2.0及以上的设备,上篇博客中已经提到。
数据类型与bank冲突
我们都知道,当每个线程访问一个32-bits大小的数据类型的数据(如int,float)时,不会发生bank冲突。
extern __shared__ int shrd[];
foo = shrd[baseIndex + threadIdx.x]
但是如果每个线程访问一个字节(8-bits)的数据时,会不会发生bank冲突呢?很明显这种情况会发生bank冲突的,因为四个线程访问了同一个bank,造成了四路bank冲突。同理,如果是short类型(16-bits)也会发生bank冲突,会产生两路的bank冲突,下面是这种情况的两个例子:
extern __shared__ char shrd[];
foo = shrd[baseIndex + threadIdx.x];

访问1字节的例子1
extern __shared__ short shrd[];
foo = shrd[baseIndex + threadIdx.x];

访问1字节的例子2
访问步长与bank冲突
我们通常这样来访问数组:每个线程根据线程编号tid与s的乘积来访问数组的32-bits字(word):
extern __shared__ float shared[];
float data = shared[baseIndex + s * tid];
如果按照上面的方式,那么当s*n是bank的数量(即32)的整数倍时或者说n是32/d的整数倍(d是32和s的最大公约数)时,线程tid和线程tid+n会访问相同的bank。我们不难知道如果tid与tid+n位于同一个warp时,就会发生bank冲突,相反则不会。
仔细思考你会发现,只有warp的大小(即32)小于等于32/d时,才不会有bank冲突,而只有当d等于1时才能满足这个条件。要想让32和s的最大公约数d为1,s必须为奇数。于是,这里有一个显而易见的结论:当访问步长s为奇数时,就不会发生bank冲突。
bank冲突的例子
既然我们已经理解了bank冲突,那我们就小试牛刀,来练习下吧!下面我们以并行计算中的经典的归约算法为例来做一个简单的练习。
假设有一个大小为2048的向量,我们想用归约算法对该向量求和。于是我们申请了一个大小为1024的线程块,并声明了一个大小为2048的共享内存数组,并将数据从全局内存拷贝到了该共享内存数组。
我们可以有以下两种方式实现归约算法:
不连续的方式:
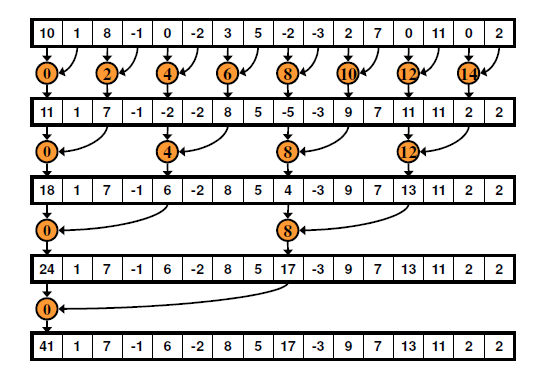
不连续的方式
连续的方式:
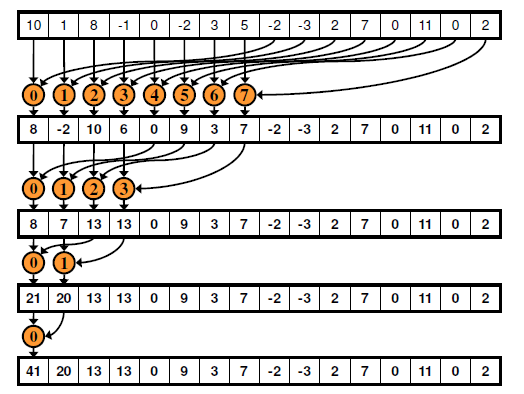
连续的方式
下面我们用具体的代码来实现上述两种方法。
// 非连续的归约求和
__global__ void BC_addKernel(const int *a, int *r)
{
__shared__ int cache[ThreadsPerBlock];
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int cacheIndex = threadIdx.x;
// copy data to shared memory from global memory
cache[cacheIndex] = a[tid];
__syncthreads();
// add these data using reduce
for (int i = 1; i < blockDim.x; i *= 2)
{
int index = 2 * i * cacheIndex;
if (index < blockDim.x)
{
cache[index] += cache[index + i];
}
__syncthreads();
}
// copy the result of reduce to global memory
if (cacheIndex == 0)
r[blockIdx.x] = cache[cacheIndex];
}
上述代码实现的是非连续的归约求和,从int index = 2 * i * cacheIndex和cache[index] += cache[index + i];两条语句,我们可以很容易判断这种实现方式会产生bank冲突。当i=1时,步长s=2xi=2,会产生两路的bank冲突;当i=2时,步长s=2xi=4,会产生四路的bank冲突...当i=n时,步长s=2xn=2n。可以看出每一次步长都是偶数,因此这种方式会产生严重的bank冲突。
NOTE:在《GPU高性能运算之CUDA》这本书中对实现不连续的归约算法有两种代码实现方式,但笔者发现书中的提到(p179)的两种所谓相同计算逻辑的函数reduce0和reduce1,其实具有本质上的不同。前者不会发生bank冲突,而后者(即本文中所使用的)才会产生bank冲突。由于前者线程ID要求的条件比较“苛刻”,只有满足tid % (2 * s) == 0的线程才会执行求和操作(sdata[tid]+=sdata[tid+i]);而后者只要满足index(2 * s * tid,即线程ID的2xs倍)小于线程块的大小(blockDim.x)即可。总之,前者在进行求和操作(sdata[tid]+=sdata[tid+i])时,线程的使用同样是不连续的,即当s=1时,线程编号为0,2,4,...,1022;而后者的线程使用是连续的,即当s=1时,前512个线程(0,1,2,...,511)在进行求和操作(sdata[tid]+=sdata[tid+i]),而后512个线程是闲置的。前者不会出现多个线程访问同一bank的不同字地址,而后者正如书中所说会产生严重的bank冲突。(书中用到的s与本文中多次用到的步长s不是同一个变量,注意不要混淆这两个变量)当然这些只是笔者的想法,如有不同,欢迎来与我讨论,邮箱:chaoyanglius@outlook.com。
// 连续的归约求和
__global__ void NBC_addKernel2(const int *a, int *r)
{
__shared__ int cache[ThreadsPerBlock];
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int cacheIndex = threadIdx.x;
// copy data to shared memory from global memory
cache[cacheIndex] = a[tid];
__syncthreads();
// add these data using reduce
for (int i = blockDim.x / 2; i > 0; i /= 2)
{
if (cacheIndex < i)
{
cache[cacheIndex] += cache[cacheIndex + i];
}
__syncthreads();
}
// copy the result of reduce to global memory
if (cacheIndex == 0)
r[blockIdx.x] = cache[cacheIndex];
}
由于每个线程的ID与操作的数据编号一一对应,因此上述的代码很明显不会产生bank冲突。
作者:退休码农飞伯德
链接:https://www.jianshu.com/p/95c842050568
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









