






前言
LLM(Large Language Model)通常拥有大量的先验知识,使得其在许多自然语言处理任务上都有着不错的性能。
但,想要直接利用 LLM 完成一些任务会存在一些答案解析上的困难,如规范化输出格式,严格服从输入信息等。
因此,在这个项目下我们参考 ChatGLM-Tuning 的代码,尝试对大模型 ChatGLM-6B 进行 Finetune,使其能够更好的对齐我们所需要的输出格式。
1. 环境安装
由于 ChatGLM 需要的环境和该项目中其他实验中的环境有所不同,因此我们强烈建议您创建一个新的虚拟环境来执行该目录下的全部代码。
下面,我们将以 Anaconda 为例,展示如何快速搭建一个环境:
- 创建一个虚拟环境,您可以把
llm_env修改为任意你想要新建的环境名称:
conda create -n llm_env python=3.8
- 激活新建虚拟环境并安装响应的依赖包:
conda activate llm_env
pip install -r requirements.txt
- 安装对应版本的
peft:
cd peft-chatglm
python setup.py install
2. 数据集准备
在该实验中,我们将尝试使用 信息抽取 + 文本分类 任务的混合数据集喂给模型做 finetune,数据集在 data/mixed_train_dataset.jsonl。
每一条数据都分为 context 和 target 两部分:
-
context部分是接受用户的输入。 -
target部分用于指定模型的输出。
在 context 中又包括 2 个部分:
-
Instruction:用于告知模型的具体指令,当需要一个模型同时解决多个任务时可以设定不同的 Instruction 来帮助模型判别当前应当做什么任务。
-
Input:当前用户的输入。
- 信息抽取数据示例
Instruction 部分告诉模型现在需要做「阅读理解」任务,Input 部分告知模型要抽取的句子以及输出的格式。
{
"context": "Instruction: 你现在是一个很厉害的阅读理解器,严格按照人类指令进行回答。\nInput: 找到句子中的三元组信息并输出成json给我:\n\n九玄珠是在纵横中文网连载的一部小说,作者是龙马。\nAnswer: ",
"target": "```json\n[{\"predicate\": \"连载网站\", \"object_type\": \"网站\", \"subject_type\": \"网络小说\", \"object\": \"纵横中文网\", \"subject\": \"九玄珠\"}, {\"predicate\": \"作者\", \"object_type\": \"人物\", \"subject_type\": \"图书作品\", \"object\": \"龙马\", \"subject\": \"九玄珠\"}]\n```"
}
- 文本分类数据示例
Instruction 部分告诉模型现在需要做「阅读理解」任务,Input 部分告知模型要抽取的句子以及输出的格式。
{
"context": "Instruction: 你现在是一个很厉害的阅读理解器,严格按照人类指令进行回答。\nInput: 下面句子可能是一条关于什么的评论,用列表形式回答:\n\n很不错,很新鲜,快递小哥服务很好,水果也挺甜挺脆的\nAnswer: ",
"target": "[\"水果\"]"
}
3. 模型训练
3.1 单卡训练
实验中支持使用 LoRA Finetune 和 P-Tuning 两种微调方式。
运行 train.sh 文件,根据自己 GPU 的显存调节 batch_size, max_source_seq_len, max_target_seq_len 参数:
# LoRA Finetune
python train.py \
--train_path data/mixed_train_dataset.jsonl \
--dev_path data/mixed_dev_dataset.jsonl \
--use_lora True \
--lora_rank 8 \
--batch_size 1 \
--num_train_epochs 2 \
--save_freq 1000 \
--learning_rate 3e-5 \
--logging_steps 100 \
--max_source_seq_len 400 \
--max_target_seq_len 300 \
--save_dir checkpoints/finetune \
--img_log_dir "log/fintune_log" \
--img_log_name "ChatGLM Fine-Tune" \
--device cuda:0
# P-Tuning
python train.py \
--train_path data/mixed_train_dataset.jsonl \
--dev_path data/mixed_dev_dataset.jsonl \
--use_ptuning True \
--pre_seq_len 128 \
--batch_size 1 \
--num_train_epochs 2 \
--save_freq 200 \
--learning_rate 2e-4 \
--logging_steps 100 \
--max_source_seq_len 400 \
--max_target_seq_len 300 \
--save_dir checkpoints/ptuning \
--img_log_dir "log/fintune_log" \
--img_log_name "ChatGLM P-Tuning" \
--device cuda:0
成功运行程序后,会看到如下界面:
...
global step 900 ( 49.89% ) , epoch: 1, loss: 0.78065, speed: 1.25 step/s, ETA: 00:12:05
global step 1000 ( 55.43% ) , epoch: 2, loss: 0.71768, speed: 1.25 step/s, ETA: 00:10:44
Model has saved at checkpoints/model_1000.
Evaluation Loss: 0.17297
Min eval loss has been updated: 0.26805 --> 0.17297
Best model has saved at checkpoints/model_best.
global step 1100 ( 60.98% ) , epoch: 2, loss: 0.66633, speed: 1.24 step/s, ETA: 00:09:26
global step 1200 ( 66.52% ) , epoch: 2, loss: 0.62207, speed: 1.24 step/s, ETA: 00:08:06
...
在 log/finetune_log 下会看到训练 loss 的曲线图:

3.2 多卡训练
运行 train_multi_gpu.sh 文件,通过 CUDA_VISIBLE_DEVICES 指定可用显卡,num_processes 指定使用显卡数:
# LoRA Finetune
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --multi_gpu --mixed_precision=fp16 --num_processes=2 train_multi_gpu.py \
--train_path data/mixed_train_dataset.jsonl \
--dev_path data/mixed_dev_dataset.jsonl \
--use_lora True \
--lora_rank 8 \
--batch_size 1 \
--num_train_epochs 2 \
--save_freq 500 \
--learning_rate 3e-5 \
--logging_steps 100 \
--max_source_seq_len 400 \
--max_target_seq_len 300 \
--save_dir checkpoints_parrallel/finetune \
--img_log_dir "log/fintune_log" \
--img_log_name "ChatGLM Fine-Tune(parallel)"
# P-Tuning
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --multi_gpu --mixed_precision=fp16 --num_processes=2 train_multi_gpu.py \
--train_path data/mixed_train_dataset.jsonl \
--dev_path data/mixed_dev_dataset.jsonl \
--use_ptuning True \
--pre_seq_len 128 \
--batch_size 1 \
--num_train_epochs 2 \
--save_freq 500 \
--learning_rate 2e-4 \
--logging_steps 100 \
--max_source_seq_len 400 \
--max_target_seq_len 300 \
--save_dir checkpoints_parrallel/ptuning \
--img_log_dir "log/fintune_log" \
--img_log_name "ChatGLM P-Tuning(parallel)"
相同数据集下,单卡使用时间:
Used 00:27:18.
多卡(2并行)使用时间:
Used 00:13:05.
4. 模型预测
修改训练模型的存放路径,运行 python inference.py 以测试训练好模型的效果:
device = 'cuda:0'
max_new_tokens = 300
model_path = "checkpoints/model_1000" # 模型存放路径
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
model = AutoModel.from_pretrained(
model_path,
trust_remote_code=True
).half().to(device)
...
您也可以使用我们提供的 Playground 来进行模型效果测试:
streamlit run playground_local.py --server.port 8001
在浏览器中打开对应的 机器ip:8001 即可访问。
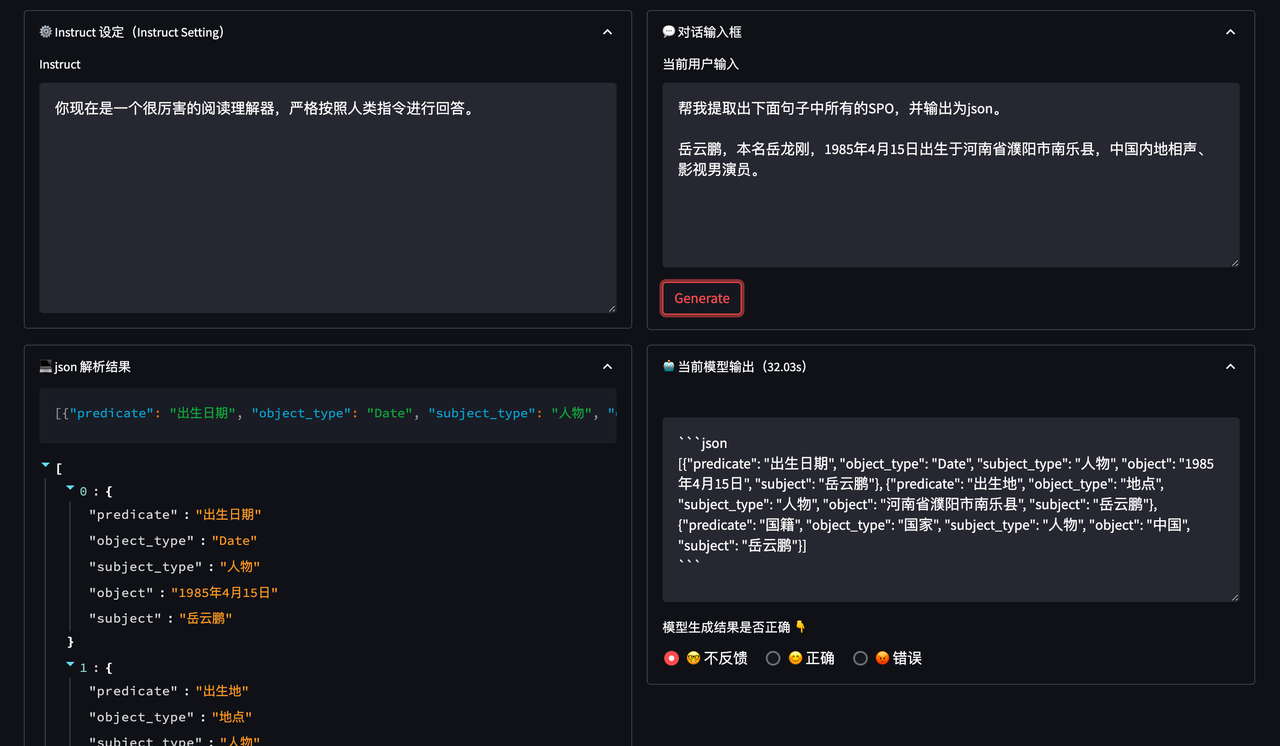
5. 标注平台
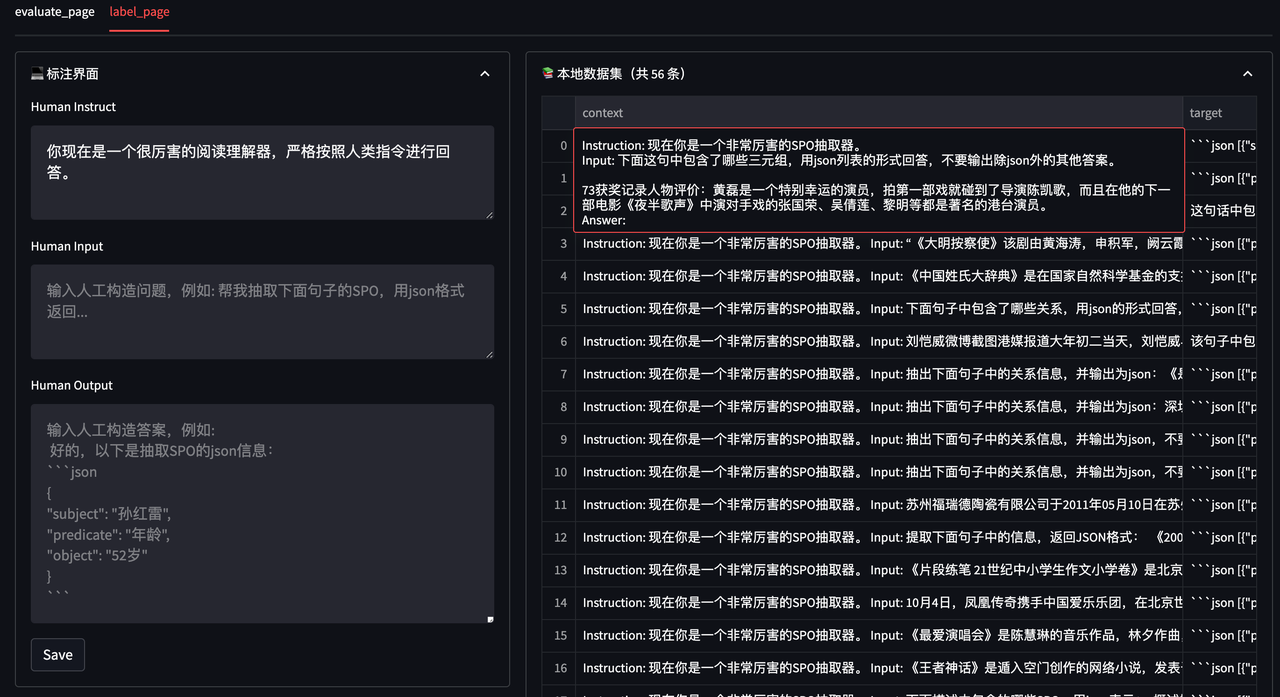
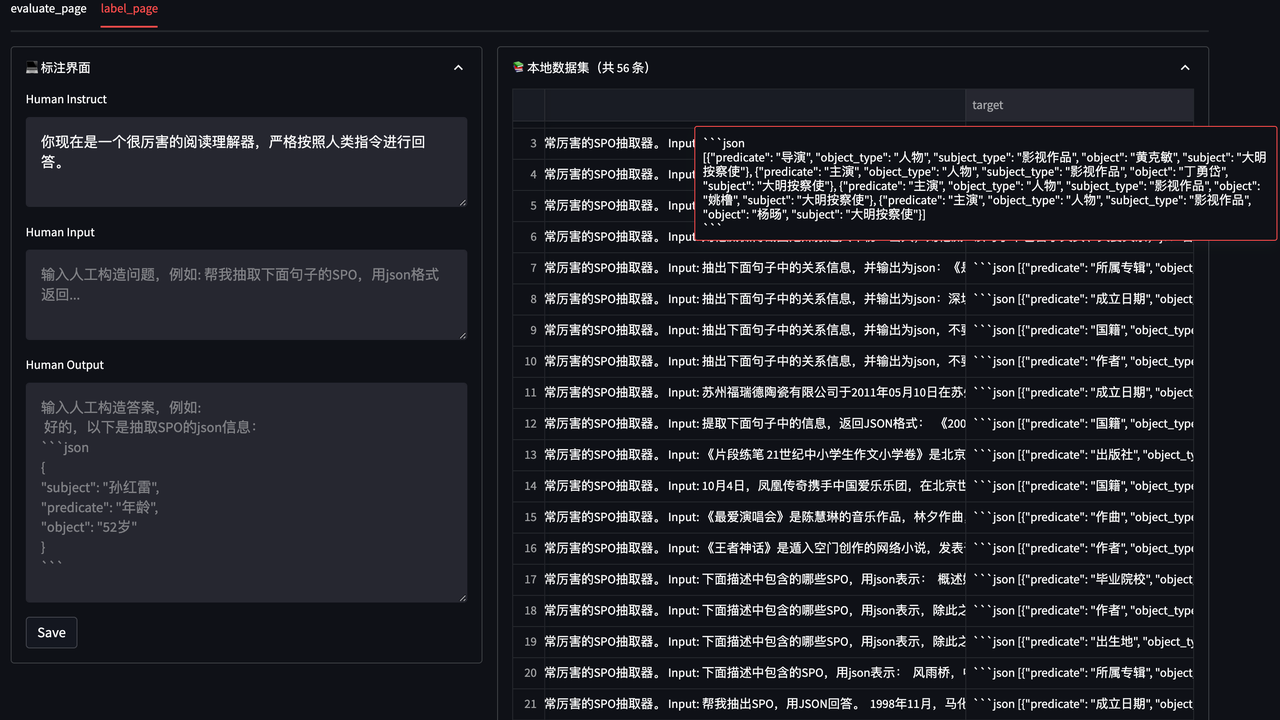
如果您需要标注自己的数据,也可以在 Playground 中完成。
streamlit run playground_local.py --server.port 8001
在浏览器中打开对应的 机器ip:8001 即可访问。
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 1933
1933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









