






1.命名实体识别介绍
命名实体识别(Named Entity Recoginition, NER) 旨在将一串文本中的实体识别出来,并标注出它所指代的类型,比如人名、地名等等。具体地,根据MUC会议规定,命名实体识别任务包括三个子任务:
- 实体名:人名、地名、机构名等
- 时间表达式:日期、时间、持续时间等
- 数字表达式:百分比、度量衡、钱、基数等
我们来看这句话,百度于2021年3月23日正式回香港上市,这句话中"百度"是个机构名,"香港"是个地名,"2021年3月23日"是个日期,命名实体识别任务能够通过建模的方式来帮助我们自动地发现这些实体。
命名实体识别是一项比较关键的NLP任务,具有广泛的应用场景,例如在对话意图理解(NLU)中,通过提取出相应的实体词,能够帮助系统更加准确地理解用户的需求,比如根据用户的问题提取出"天气",“北京”,"今天"这样的词汇,大概率就能知道用户在问些什么;在微博场景中,应用命名实体识别提取出微博短文中重要的实体词,也有利于微博信息的汇总,或者事件热度的统计。
NER任务一般会被建模成序列标注任务,也就是说,模型的输入是待识别的一串文本序列,模型的输出就是该文本序列对应的标签序列,不同于文本分类任务,这是一种序列到序列的任务。我们来举个例子:
| 姚 | 明 | 担 | 任 | 中 | 国 | 篮 | 协 | 主 | 席 |
|---|---|---|---|---|---|---|---|---|---|
| B-Person | I-Person | O | O | B-Organization | I-Organization | I-Organization | I-Organization | O | O |
这句话中的每个字分别对应着一个标签, 模型的输入就是上边的文本,模型的输出就是下面的标签序列,我们通过这样的标签序列就能识别出原始文本中的实体。
具体地,上边这串文本中,“姚明"对应着Person实体,其中"姚"字是"Person"实体的起始字,所以设置标签为"B-person”,其中标签前边的B代表Begin这个单词;“明"字是"Person"实体的中间字,所以设置标签为"I-Person”,其中标签前边的I代表Intermediate这个单词。 “中国篮协"对应这Organization实体,相应标签"B-Organization"和"I-Organization"的解读和Person实体是一致的。最后的标签"O"代表"other”,表示其他实体类型的标签。
看到这里,相信你已经知道,本节的NER任务要建模完成一件什么事情了,即建模一个序列到序列的模型来找出文本中蕴含的实体。
2.BiLSTM+CRF实现命名实体识别
BiLSTM + CRF是一种经典的命名实体识别(NER)模型方案,这在后续很多的模型improvment上都有启发性。如果你有了解NER任务的兴趣或者任务,或者完全出于对CRF的好奇,建议大家静心读一读这篇文章。
本篇文章会将重点放到条件随机场(CRF)上边,因为这是实现NER任务很重要的一个组件,也是本篇文章最想向你推荐的特色。但是如果你 对长短时记忆网络(LSTM)也不是很熟悉,那你也不用担心,笔者会去解释LSTM的用法,它的输入和输出等等内容,以保证你可以顺畅的读下去,领悟到这个模型的精髓。
2.1使用BiLSTM+CRF实现NER
为方便直观地看到BiLSTM+CRF是什么,我们先来贴一下BiLSTM+CRF的模型结构图,如图1所示。
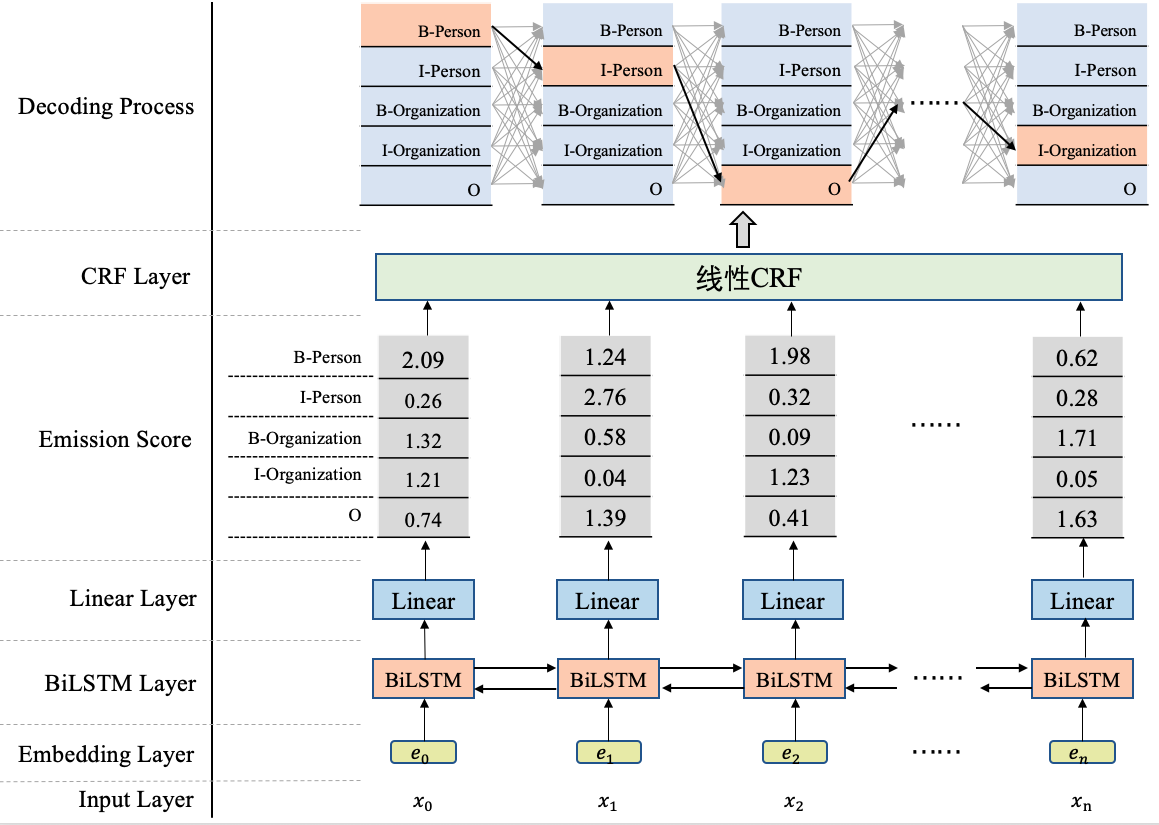
图1 使用BiLSTM+CRF实现NER
从图1可以看到,在BiLSTM上方我们添加了一个CRF层。具体地,在基于BiLSTM获得各个位置的标签向量之后,这些标签向量将被作为发射分数传入CRF中,发射这个概念是从CRF里面带出来的,后边在介绍CRF部分会更多地提及,这里先不用纠结这一点。
这些发射分数(标签向量)传入CRF之后,CRF会据此解码出一串标签序列。那么问题来了,从图1最上边的解码过程可以看出,这里可能对应着很多条不同的路径,例如:
- B-Person, I-Person, O, …, I-Organization
- B-Organization, I-Person, O, …, I-Person
- B-Organization, I-Organization, O, …, O
CRF的作用就是在所有可能的路径中,找出得出概率最大,效果最优的一条路径,那这个标签序列就是模型的输出。
我们来总结一下,使用BiLSTM+CRF模型架构实现NER任务,大致分为两个阶段:使用BiLSTM生成发射分数(标签向量),基于发射分数使用CRF解码最优的标签路径。
2. 回归CRF建模原理本身
本节将开始聚焦在CRF原理本身进行讲解,力图为读者展现一个清楚明白,基础本质的CRF。那现在开始这趟学习之旅吧,相信你一定会有所收获。
2.1 线性CRF的定义
通常我们会使用线性链CRF来建模NER任务,所以本实验将聚焦在线性链CRF来探讨。那什么是线性链CRF呢,我们来看下李航老师在《统计学习方法》书中的定义:
设KaTeX parse error: Undefined control sequence: \[ at position 3: X=\̲[̲x\_1, x\_2, ...… 均为线性链表示的随机变量序列,若在给定随机变量序列的 X X X的条件下,随机变量序列 Y Y Y的条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)构成条件随机场,即满足马尔可夫性:
KaTeX parse error: Expected 'EOF', got '&' at position 70: …i+1},...,y\_n) &̲= P(y\_i|X,y\_{…
则称 P ( Y ∣ X ) P(Y|X) P(Y∣X)为线性链条件随机场。
同学们看到这个定义,或许会有些疑惑,但是不用着急,我们来探讨下这个定义。图2展示了一种经典的线性链CRF的结构图,从这张结构图来理解这个定义,主要包含两个点:
- 确保输入序列 X X X和输出序列 Y Y Y是线性序列
- 每个标签 y _ i y\_i y_i的产生,只与这些因素有关系:当前位置的输入 x _ i x\_i x_i, y _ i y\_i y_i直接相连的两个邻居 y _ i − 1 y\_{i-1} y_i−1和 y _ i + 1 y\_{i+1} y_i+1,与其他的标签和输入没有关系。
这样的定义,其实帮助我们减小了建模CRF的代价。
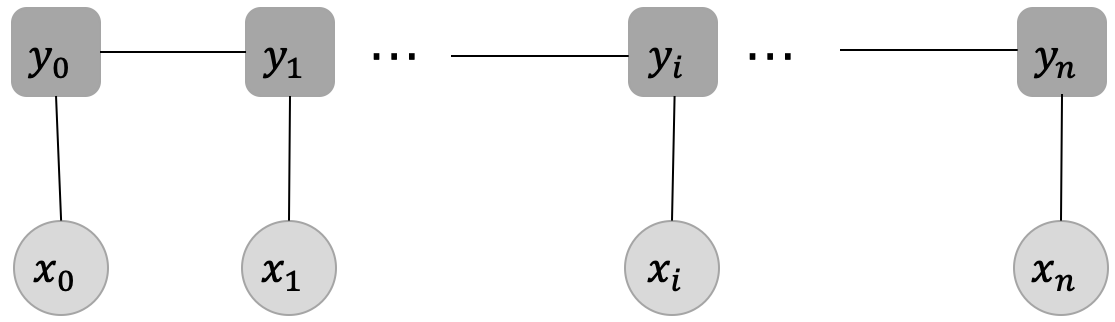
图 2 一种经典的线性链CRF结构图
2.2 发射分数和转移分数
上边我们探讨了线性链CRF的定义以及它的一种经典图结构,接下来我们继续回到我们建模的命名实体任务上来。
在图2中,KaTeX parse error: Undefined control sequence: \[ at position 3: x=\̲[̲x\_0, x\_1, ...…代表输入变量,对应到我们当前任务就是输入文本序列,KaTeX parse error: Undefined control sequence: \[ at position 3: y=\̲[̲y\_0, y\_1, ...…代表相应的标签序列,
其中,每个输入 x _ i x\_i x_i均对应着一个标签 y _ i y\_i y_i,这一步对应的就是发射分数,它指示了当前的输入 x _ i x\_i x_i应该对应什么样的标签;在每个标签 y _ i y\_i y_i之间也存在连线,它表示当前位置的标签 y _ i y\_i y_i向下一个位置的标签 y _ i + 1 {y\_{i+1}} y_i+1的一种转移。举个例子,假设当前位置的标签是"B-Person",那下一个位置就很有可能是"I-Person"标签,即标签"B-Person"向"I-Person"转移的概率会比较大。
这里我们带出了建模CRF过程中两个重要的概念:发射分数和转移分数,下边我们来看看他们是什么。
2.2.1 发射分数
前边我们在第2节已经提到过发射分数了,即BiLSTM后产生的标签向量。如果大家对这部分内容已经很熟悉,完全可以跳过这部分。图3以矩阵的形式展示了发射分数的生成过程。
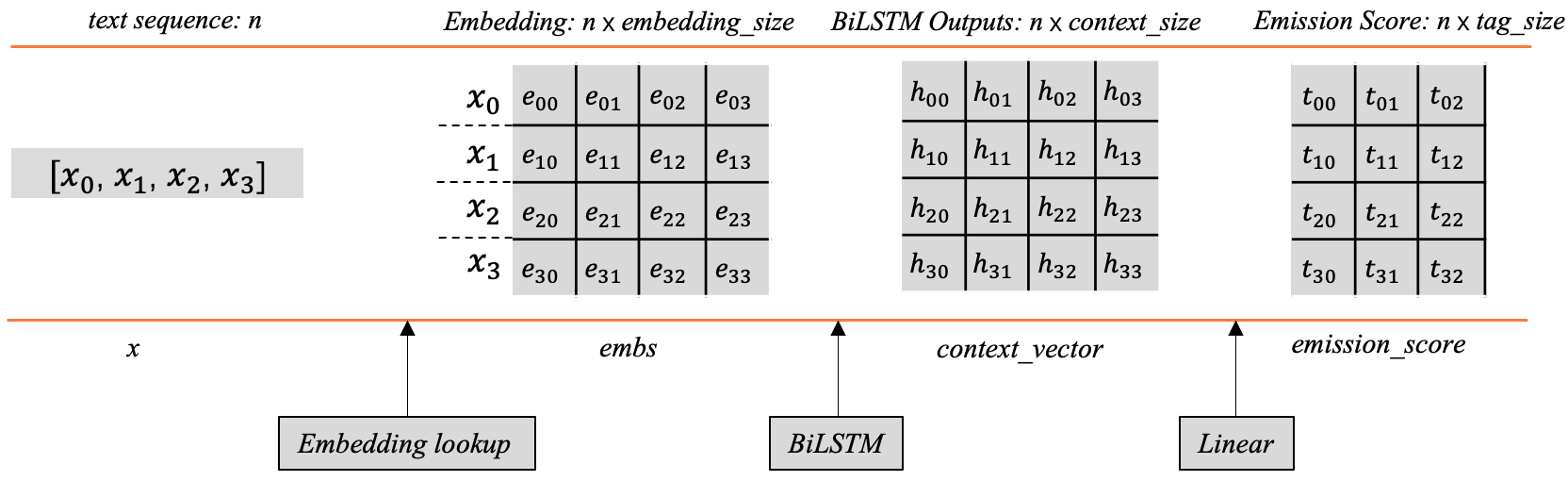
图3 发射分数的矩阵计算解释
当给定的文本序列KaTeX parse error: Undefined control sequence: \[ at position 3: x=\̲[̲x\_1, x\_2, x\_…映射为对应词向量之后,将会得到一个shape为KaTeX parse error: Undefined control sequence: \[ at position 1: \̲[̲n, embedding\_s…的词向量矩阵 e m b s embs embs,其中每对应一个字词(图5样例只使用了4个词),例如 x _ 0 x\_0 x_0对应的词向量是KaTeX parse error: Undefined control sequence: \[ at position 1: \̲[̲e\_{00}, e\_{01…。
然后将 e m b s embs embs传入BiLSTM后,每个词的位置都会产生一个上下文向量,所有的向量组合之后会得到一个向量矩阵 c o n t e x t _ v e c t o r context\_vector context_vector,其中每行代表对应单词经过BiLSTM后的上下文向量。
这里的每个位置的上下文向量可以用来指导当前位置应该输出的标签信息,但这里有个问题,这个输出向量的维度并不是标签的数量,它不能直接用来指示应该输出什么标签。一般的做法是在后边加一层线性层,将这个上下文向量的维度映射为标签的数量,这样的话就会生成前边所讲的标签向量,其中的每个元素分别对应着相应标签的分数,根据这个分数可以用来指导最终标签的输出。
具体地,线性层这里只是做了这样的一个线性变换:
y
=
X
W
+
b
y = XW+b
y=XW+b,显然,这里的
X
X
X就是
c
o
n
t
e
x
t
_
v
e
c
t
o
r
context\_vector
context_vector,
y
y
y是相应的
e
m
i
s
s
i
o
n
_
s
c
o
r
e
emission\_score
emission_score,
W
和
b
W和b
W和b是线性层的可学习参数。
前边提到,
c
o
n
t
e
x
t
_
v
e
c
t
o
r
context\_vector
context_vector的shape为KaTeX parse error: Undefined control sequence: \[ at position 1: \̲[̲n,context\_size…,那么线性层的
W
W
W的shape应该是KaTeX parse error: Undefined control sequence: \[ at position 1: \̲[̲context\_size, …,经过以上公式的线性变换,就可以得到发射分数
e
m
i
s
s
i
o
n
_
s
c
o
r
e
emission\_score
emission_score,其中每个字词对应一行的标签分数(图3中只设置了三列,代表一共有3个标签),例如,
x
_
0
x\_0
x_0对第一个标签的分数预测为
t
_
00
t\_{00}
t_00,对第二个标签的分数预测为
t
_
01
t\_{01}
t_01,对第三个标签的分数预测为
t
_
02
t\_{02}
t_02,依次类推。
2.2.2 转移分数
下面我们来聊聊转移分数,这个转移分数表示一个标签向另一个标签转移的分数,分数越高,转移概率就越大,反之亦然。图4展示了记录转移分数的矩阵。
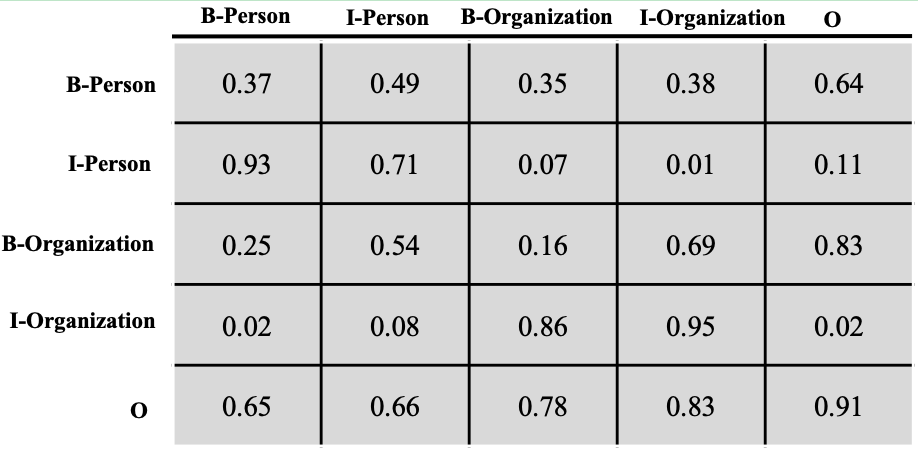
图4 转移分数矩阵图
让我们从列到行地来看下这个转移矩阵 T T T,B-Person向I-Person转移的分数为0.93,B-Person向I-Organization转移的分数为0.02,前者的分数远远大于后者。I-Person向I-Person转移的概率是0.71,I-Organization向I-Organization转移的分数是0.95,因为一个人或者组织的名字往往包含多个字,所以这个概率相对是比较高的,这其实也是很符合我们直观认识的。
假设我们现在有个标签序列:B-Person, I-Person, O, O,B-Organization, I-Organization。那么这个序列的转移分数可按照如下方式计算:
S e q _ t = T _ I − P e r s o n , B − P e r s o n + T _ O , I − P e r s o n + T _ O , O + T _ O , B − O r g a n i z a t i o n + T _ B − O r g a n i z a t i o n , I − O r g a n i z a t i o n Seq\_t = T\_{I-Person,B-Person} + T\_{O,I-Person} + T\_{O,O} + T\_{O,B-Organization} + T\_{B-Organization, I-Organization} Seq_t=T_I−Person,B−Person+T_O,I−Person+T_O,O+T_O,B−Organization+T_B−Organization,I−Organization
这个转移分数矩阵是CRF中的一个可学习的参数矩阵,它的存在能够帮助我们显示地去建模标签之间的转移关系,提高命名实体识别的准确率。
2.3 CRF建模的损失函数
前边我们讲到,CRF能够帮助我们以一种全局的方式建模,在所有可能的路径中选择效果最优,分数最高的那条路径。那么我们应该怎么去建模这个策略呢,下面我们来具体谈谈。
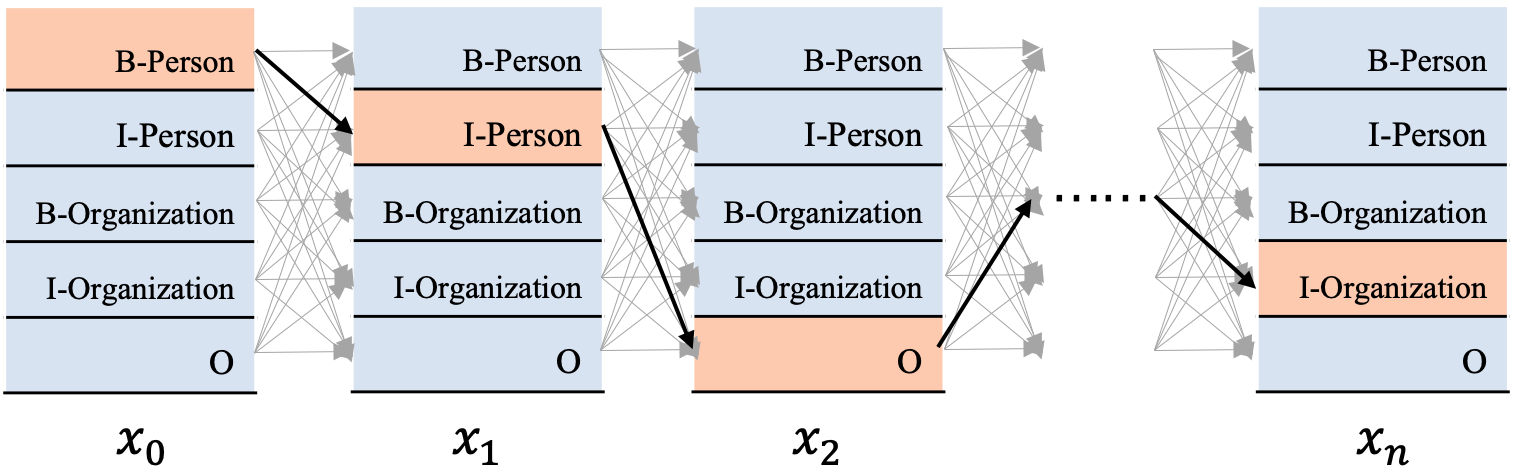
图5 CRF解码过程图
图5展示了CRF的工作图,现在我们有一串输入KaTeX parse error: Undefined control sequence: \[ at position 3: x=\̲[̲x\_0, x\_1, x\_…(这里的 x x x是文本串对应的发射分数,每个字词 x _ i x\_i x_i都对应着一个发射分数向量,也就是前边提到的标签向量,该向量的维度就是标签数量),期待解码出相应的标签序列KaTeX parse error: Undefined control sequence: \[ at position 3: y=\̲[̲y\_0, y\_1,y\_2…,形式化为对应的条件概率公式如下:
( y ∣ x ) = P ( y _ 0 , y _ 1 , . . . , y _ n ∣ x _ 0 , x _ 1 , . . . , x _ n ) (y|x) = P(y\_0,y\_1,...,y\_n|x\_0,x\_1,...,x\_n) (y∣x)=P(y_0,y_1,...,y_n∣x_0,x_1,...,x_n)
在第2节我们提到,CRF的解码策略在所有可能的路径中,找出得出概率最大,效果最优的一条路径,那这个标签序列就是模型的输出,假设标签数量是 k k k,文本长度是 n n n,显然会有 N = k n N=k^n N=kn条路径,若用 S _ i S\_i S_i代表第 i i i条路径的分数,那我们可以这样去算一个标签序列出现的概率:
P ( S _ i ) = f r a c e S _ i s u m _ j e S _ j P(S\_i)=\\frac{e{S\_i}}{\\sum\_j{e^{S\_j}}} P(S_i)=fraceS_isum_jeS_j
现在我们有一条真实的路径 r e a l real real,即我们期待CRF解码出来的序列就是这一条。那它的分数可以表示为 s _ r e a l s\_{real} s_real,它出现的概率就是:
P ( S _ r e a l ) = f r a c e S _ r e a l s u m _ j e S _ j P(S\_{real})=\\frac{e{S\_{real}}}{\\sum\_j{e^{S\_j}}} P(S_real)=fraceS_realsum_jeS_j
所以我们建模学习的目的就是为了不断的提高 P ( S _ r e a l ) P(S\_{real}) P(S_real)的概率值,这就是我们的目标函数,当目标函数越大时,它对应的损失就应该越小,所以我们可以这样去建模它的损失函数:
l o s s = − P ( S _ r e a l ) = − f r a c e S _ r e a l s u m _ j e S _ j loss=-P(S\_{real})=-\\frac{e{S\_{real}}}{\\sum\_j{e^{S\_j}}} loss=−P(S_real)=−fraceS_realsum_jeS_j
为方便求解,我们一般将这样的损失放到log空间去求解,因为log函数本身是单调递增的,所以它并不影响我们去迭代优化损失函数。
KaTeX parse error: Expected 'EOF', got '&' at position 26: …{align} loss &̲= -log \\frac{e…
千呼万唤始出来,这就是我们CRF建模的损失函数了。我们整个BiLSTM+CRF建模的目的就是为了让这个函数越来越小。从这个损失函数可以看出,这个损失函数包含两部分:单条真实路径的分数 S _ r e a l S\_{real} S_real,归一化项 l o g ( e S _ 1 + e + . . . + e S _ N ) log(e{S\_1}+e+...+e^{S\_N}) log(eS_1+e+...+eS_N),即将全部的路径分数进行 l o g _ s u m _ e x p log\_sum\_exp log_sum_exp操作,即先将每条路径分数 S _ i S\_i S_i进行 e x p ( S _ i ) exp(S\_i) exp(S_i),然后再将所有的项加起来,最后取 l o g log log值。
讲到这里,有的同学可能会有疑惑,这里的每条路径分数应该怎么算呢?接下来,我们就来解决这个问题。
2.4 单条路径的分数计算
在开始之前,我们再来做一些约定,前边我们提到了发射分数和转移分数,假设 E E E代表发射分数矩阵, T T T代表转移分数矩阵, n n n代表文本序列长度, t a g _ s i z e tag\_size tag_size代表标签的数量。另外为方便书写,我们为每个标签编个id号(参考图5中涉及到的标签),如图6所示。

图6 Tag和Tag Id 对应表
其中, E E E的shape为KaTeX parse error: Undefined control sequence: \[ at position 1: \̲[̲n, tag\_size\],每行对应着一个文本字词的发射分数,每列代表一个标签,例如, E _ 01 E\_{01} E_01代表 x _ 0 x\_0 x_0取id为1的标签分数, E _ 23 E\_{23} E_23代表 x _ 2 x\_2 x_2取id为3的标签分数。 T T T的shape为KaTeX parse error: Undefined control sequence: \[ at position 1: \̲[̲tag\_size, tag\…,它代表了标签之间相互转移的分数,例如, T _ 03 T\_{03} T_03代表id为3的标签向id为0的标签转移分数。
每条路径的分数就是由对应的发射分数和转移分数组合而成的,对于图5标记出来的黄色路径来说, x _ 0 x\_0 x_0的标签是B-Person,对应的发射分数是 E _ 00 E\_{00} E_00, x _ 1 x\_1 x_1的标签是I-Person,对应的发射分数是 E _ 11 E\_{11} E_11,由B-Person向I-Person转移的分数是 T _ 10 T\_{10} T_10,因此到这一步的分数就是: E _ 00 + T _ 10 + E _ 11 E\_{00}+T\_{10}+E\_{11} E_00+T_10+E_11。
接下来 x _ 2 x\_2 x_2的标签是 O O O,由 x _ 1 x\_1 x_1的标签向I-Person向 x _ 2 x\_2 x_2的标签O转移的概率是 T _ 41 T\_{41} T_41,因此到这一步的分数是: E _ 00 + T _ 10 + E _ 11 + T _ 41 + E _ 24 E\_{00}+T\_{10}+E\_{11}+T\_{41}+E\_{24} E_00+T_10+E_11+T_41+E_24,依次类推,我们可以计算完整条路径的分数。假设第 i i i个位置对应的标签为 y _ i y\_i y_i,则整条路径的分数计算形式化公式为:
S _ r e a l = s u m _ i = 0 n − 1 E _ i , y _ i + s u m _ i = 0 n − 2 T _ y _ i + 1 , y _ i S\_{real}=\\sum\_{i=0}^{n-1}{E\_{i,y\_i}} + \\sum\_{i=0}^{n-2}{T\_{y\_{i+1}, y\_{i}}} S_real=sum_i=0n−1E_i,y_i+sum_i=0n−2T_y_i+1,y_i
2.5 全部路径的分数计算
2.3节中的损失函数包括两项,单条真实路径分数的计算和归一化项(如上所述,全部路径分数的 l o g _ s u m _ e x p log\_sum\_exp log_sum_exp,为方便描述,后续直接将个归一化项描述为全部路径之和)的计算。这里你或许会问,现在知道了单条路径分数的计算方式,遍历一下所有的路径算个分数,不就可以轻松算出全部路径之和吗?是的,这在理论上是可行的。
但是,前边我们提到这个路径的数量是个指数级别的量纲,假设我对串包含50个字的文本串进行实体识别,标签的数量是31,那么这个路径的数量将是 3 1 50 31^{50} 3150条,这是真的是难以接受的一件事情,它会远远拖慢模型的训练和预测效率。
因此,我们要换一种高效的思路,这里其实用到了一种被称为前向算法的动态规划,它能帮助我们将图5所有路径的和计算,拆解为每个位置的和计算,最终得出所有的路径之和。如果这是你第一次听到这个算法,那也没关系,我会通过示例的方式,为你展现这个算法的工作原理,但是在看这部分内容之前,我们再来回顾一下我们的计算目标,即损失函数中的第1项:
l o g ( e S _ 1 + e + . . . + e S _ N ) log(e{S\_1}+e+...+e^{S\_N}) log(eS_1+e+...+eS_N)
另外,为方便描述这个原理,我们来简化下这个问题,假设我们现在在计算图7所示的所有路径之和。
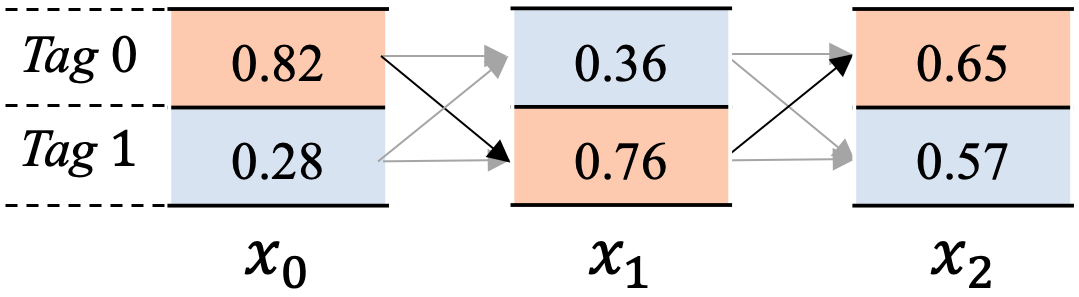
图7 简化版的CRF工作图
图7中,共包含2个标签 T a g Tag Tag 0 和 T a g Tag Tag 1, 文本串有3个单词 x _ 0 , x _ 1 , x _ 2 x\_0, x\_1, x\_2 x_0,x_1,x_2。我们再来做些约定如下:
KaTeX parse error: Undefined control sequence: \[ at position 13: emission\_i=\̲[̲x\_{i0},x\_{i1}…, 代表 x _ i x\_i x_i位置的发射分数。
其中, x _ i 0 x\_{i0} x_i0代表 x _ i x\_i x_i位置输出 T a g Tag Tag 0 标签的分数, x _ i 1 x\_{i1} x_i1代表 x _ i x\_i x_i位置输出 T a g Tag Tag 1 标签的分数。
$ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] $, 代表转移矩阵。
其中, t _ 01 t\_{01} t_01代表从 T a g Tag Tag 1 转移到 T a g Tag Tag 0的分数, t _ 10 t\_{10} t_10代表从 T a g Tag Tag 0 转移到 T a g Tag Tag 1的分数,依次类推。
KaTeX parse error: Undefined control sequence: \[ at position 10: alpha\_i=\̲[̲s\_{i0},s\_{i1}…, 其中各个数值代表到当前位置 x _ i x\_i x_i为止,以 x _ i x\_i x_i位置相应标签结尾的路径分数之和。
以 x _ 2 x\_2 x_2步为例,KaTeX parse error: Undefined control sequence: \[ at position 10: alpha\_2=\̲[̲s\_{20},s\_{21}…,其中 s _ 20 s\_{20} s_20代表截止到 x _ 2 x\_2 x_2步骤为止,以标签 T a g Tag Tag 0 结尾所有的路径分数之和, s _ 21 s\_{21} s_21代表截止到 x _ 2 x\_2 x_2步骤为止,以标签 T a g Tag Tag 1结尾的所有路径分数之和。
这里比较抽象,如图7所示,参与 x _ 2 x\_2 x_2步的 s _ 20 s\_{20} s_20分数计算的路径包括4条,即 s _ 20 s\_{20} s_20是下边4条路径分数之和,依次如下
- x _ 00 , x _ 10 , x _ 20 x\_{00},x\_{10},x\_{20} x_00,x_10,x_20
- x _ 00 , x _ 11 , x _ 20 x\_{00},x\_{11},x\_{20} x_00,x_11,x_20
- x _ 01 , x _ 10 , x _ 20 x\_{01},x\_{10},x\_{20} x_01,x_10,x_20
- x _ 01 , x _ 11 , x _ 20 x\_{01},x\_{11},x\_{20} x_01,x_11,x_20
恭喜,我们完成了一些枯燥的定义,下边我们来看看如何计算所有路径的分数和吧,这里我们分成3步走来解释,首先计算截止到 x _ 0 x\_0 x_0位置,到各个标签的分数(上边的 a l p h a alpha alpha内容)是多少;截止到 x _ 1 x\_1 x_1位置,到各个标签的分数是多少;截止到 x _ 2 x\_2 x_2位置,到各个标签的分数是多少。
第1步,截止到 x _ 0 x\_0 x_0位置
当前位置 x _ 0 x\_0 x_0输入的发射分数为:KaTeX parse error: Undefined control sequence: \[ at position 13: emission\_0=\̲[̲x\_{00},x\_{01}…,因为这是序列的起始,显然截止到 x _ 0 x\_0 x_0位置有:KaTeX parse error: Undefined control sequence: \[ at position 10: alpha\_0=\̲[̲x\_{00},x\_{01}…。
截止到 x _ 0 x\_0 x_0这一步,将 x _ 0 x\_0 x_0位置的所有标签的分数累计作为所有路径的分数为:
t o t a l _ 0 = l o g ( e x _ 00 + e x _ 01 ) total\_0 = log(e{x\_{00}}+e{x\_{01}}) total_0=log(ex_00+ex_01)
第2步,截止到 x _ 1 x\_1 x_1位置
当前步骤涉及到 x _ 0 x\_0 x_0向 x _ 1 x\_1 x_1位置的转移,在这个过程中, x _ 1 x\_1 x_1位置输入的发射分数为:KaTeX parse error: Undefined control sequence: \[ at position 13: emission\_1=\̲[̲x\_{10}, x\_{11…, 转移概率矩阵为: $ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] , 前一个位置 , 前一个位置 ,前一个位置x_0 各标签的路径累计和 各标签的路径累计和 各标签的路径累计和alpha_0=[x_{00},x_{01}]$。
接下来我们expand一下 e m i s s i o n _ 1 emission\_1 emission_1 和 a l p h a _ 0 alpha\_0 alpha_0,力求通过矩阵计算的方式一次完成当前位置 x _ 1 x\_1 x_1各个标签的路径累计 a l p h a _ 1 alpha\_1 alpha_1,具体如下:
KaTeX parse error: Undefined control sequence: \[ at position 21: …ion\_1 = \\left\̲[̲ \\begin{matrix…
KaTeX parse error: Undefined control sequence: \[ at position 18: …pha\_0 = \\left\̲[̲ \\begin{matrix…
然后我们来计算截止到 x _ 1 x\_1 x_1位置,到不同标签的每条路径的分数:
KaTeX parse error: Expected 'EOF', got '&' at position 28: …lign} scores &̲= alpha\_0+tran…
我们来看一条路径分数的计算,例如$ x_{00}+t_{10}+x_{11} , 它代表在 , 它代表在 ,它代表在x_0 的位置标签为 的位置标签为 的位置标签为Tag$ 0,在 x _ 1 x\_1 x_1的位置标签为 T a g Tag Tag 1,然后通过加上 t _ 10 t\_{10} t_10完成了 x _ 0 x\_0 x_0位置 T a g Tag Tag 0标签 向 x _ 1 x\_1 x_1位置标签 T a g Tag Tag 1的转移。
从上边的结果可以看到,第1行代表向当前位置 x _ 1 x\_1 x_1标签 T a g Tag Tag 0的转移路径,第2行代表向当前位置 x _ 1 x\_1 x_1标签 T a g Tag Tag 1的转移路径。以第1行为例,将第1行的路径分数相加,就相当于到当前位置 x _ 1 x\_1 x_1并且以 T a g Tag Tag 0结尾的所有路径之和。
因此,这样我们可以容易地算出当前位置 x _ 1 x\_1 x_1的各个标签的路径累计分数 a l p h a _ 1 alpha\_1 alpha_1:
KaTeX parse error: Undefined control sequence: \[ at position 12: alpha\_1 = \̲[̲log(e{x\_{00}+t…
最后,我们来算下截止到 x _ 1 x\_1 x_1位置,所有的路径和:
KaTeX parse error: Expected 'EOF', got '&' at position 30: …gn} total\_1 &̲= log(e^{alpha\…
再回顾一下我们的计算目标: l o g ( e S _ 1 + e + . . . + e S _ N ) log(e{S\_1}+e+...+e^{S\_N}) log(eS_1+e+...+eS_N),你可以看到如果图7最终只到 x _ 1 x\_1 x_1位置,那么上边的这个结果就是我们相求的全部路径之和,或者说是归一化项。
第3步,截止到 x _ 2 x\_2 x_2位置
我们再来看下 x _ 2 x\_2 x_2位置的一些输入信息, x _ 2 x\_2 x_2位置输入的发射分数为:KaTeX parse error: Undefined control sequence: \[ at position 13: emission\_2=\̲[̲x\_{20}, x\_{21…, 转移概率矩阵为: $ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] , 前一个位置 , 前一个位置 ,前一个位置x_1 各标签的路径累计和 各标签的路径累计和 各标签的路径累计和alpha_1=[log(e{x_{00}+t_{00}+x_{10}}+e+t_{01}+x_{10}}), log(e{x_{00}+t_{10}+x_{11}}+e+t_{11}+x_{11}})]$。
接下来继续expand一下 e m i s s i o n _ 2 emission\_2 emission_2 和 a l p h a _ 1 alpha\_1 alpha_1,力求通过矩阵计算的方式一次完成当前位置 x _ 2 x\_2 x_2各个标签的路径累计 a l p h a _ 2 alpha\_2 alpha_2,具体如下:
KaTeX parse error: Undefined control sequence: \[ at position 21: …ion\_2 = \\left\̲[̲ \\begin{matrix…
KaTeX parse error: Undefined control sequence: \[ at position 18: …pha\_1 = \\left\̲[̲ \\begin{matrix…
然后我们来计算截止到 x _ 2 x\_2 x_2位置,到不同标签的每条路径的分数:
KaTeX parse error: Expected 'EOF', got '&' at position 28: …lign} scores &̲= alpha\_1+tran…
继续按行累加,算出到当前位置 x _ 2 x\_2 x_2的各个标签的路径累计分数 a l p h a _ 2 alpha\_2 alpha_2:
KaTeX parse error: Expected 'EOF', got '&' at position 30: …gn} alpha\_2 &̲= \[log(e^{scor…
最后,我们来算下截止到 x _ 2 x\_2 x_2位置,所有的路径和:
KaTeX parse error: Expected 'EOF', got '&' at position 30: …gn} total\_2 &̲= log(e^{alpha\…
显然,这个式子的结果就是最终我们想要的计算目标,损失函数中的第1项,共计包含8条路径的分数。
2.6 CRF的Viterbi解码
在前边几节,我们讲过了CRF的损失函数、单条路径分数的计算、全部路径分数的计算,根据这些内容完全可以进行BiLSTM+CRF的训练。但是,我们如何使用CRF从全部的路径中解码出得分最高的那条路径呢?
同2.5节所述,计算全部路径分数后,选择得分最大的那条路径肯定是不行的。其实这里是使用了一种被称为Viterbi的算法,它的思想和2.5节介绍的前向算法有些类似,将从全部路径中查找最优路径的过程,拆解为选择每个位置累计的最大路径。如果这是你第一次接触Viterbi算法,也不用担心,本节依然会通过示例的方式展现这个算法原理。
我们依然以图7为例,解码这全部路径中分数最大的这条(图中橙色显示的这条路径)。在正式介绍之前,我们依然做些约定如下:
KaTeX parse error: Undefined control sequence: \[ at position 13: emission\_i=\̲[̲x\_{i0},x\_{i1}…, 代表 x _ i x\_i x_i位置的发射分数。
其中, x _ i 0 x\_{i0} x_i0代表 x _ i x\_i x_i位置输出 T a g Tag Tag 0 标签的分数, x _ i 1 x\_{i1} x_i1代表 x _ i x\_i x_i位置输出 T a g Tag Tag 1 标签的分数。
$ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] $, 代表转移矩阵。
其中, t _ 01 t\_{01} t_01代表从 T a g Tag Tag 1 转移到 T a g Tag Tag 0的分数, t _ 10 t\_{10} t_10代表从 T a g Tag Tag 0 转移到 T a g Tag Tag 1的分数,依次类推。
KaTeX parse error: Undefined control sequence: \[ at position 10: alpha\_i=\̲[̲s\_{i0},s\_{i1}…, 其中各个数值代表到当前位置 x _ i x\_i x_i为止,以当前位置 x _ i x\_i x_i相应标签结尾的路径中,取得最大分数的路径得分。
以 x _ 2 x\_2 x_2位置为例,KaTeX parse error: Undefined control sequence: \[ at position 10: alpha\_2=\̲[̲s\_{20},s\_{21}…,其中 s _ 20 s\_{20} s_20代表截止到 x _ 2 x\_2 x_2步骤为止,以标签 T a g Tag Tag 0 结尾所有的路径中得分最大的路径分数, s _ 21 s\_{21} s_21代表截止到 x _ 2 x\_2 x_2步骤为止,以标签 T a g Tag Tag 1结尾的所有路径中得分最大的路径分数。
这里比较抽象,如图7所示,参与 x _ 2 x\_2 x_2步的 s _ 20 s\_{20} s_20分数计算的路径包括4条, s _ 20 s\_{20} s_20是这4条路径中得分最大这一条对应的分数,即下边这一条路径: x _ 00 , x _ 11 , x _ 20 x\_{00},x\_{11},x\_{20} x_00,x_11,x_20。
KaTeX parse error: Undefined control sequence: \[ at position 11: beta\_i = \̲[̲p\_{i0},p\_{i1}…,其中各个数值代表到当前位置 x _ i x\_i x_i为止,以当前位置 x _ i x\_i x_i相应标签结尾的路径中,分数最大的那一条路径在前一个位置 x _ i − 1 x\_{i-1} x_i−1的标签索引(每个标签对应的id号)。
以 x _ 2 x\_2 x_2位置为例,KaTeX parse error: Undefined control sequence: \[ at position 11: beta\_2 = \̲[̲p\_{20},p\_{21}…,其中 p _ 20 p\_{20} p_20代表代表截止到 x _ 2 x\_2 x_2步骤为止,以标签 T a g Tag Tag 0 结尾所有的路径中得分最大的那条路径在 x _ i − 1 x\_{i-1} x_i−1位置的标签索引,同理 p _ 21 p\_{21} p_21代表截止到 x _ 2 x\_2 x_2步骤为止,以标签 T a g Tag Tag 1结尾的最大路径在 x _ i − 1 x\_{i-1} x_i−1位置的标签索引。
同样,如图7所示,在 x _ 2 x\_2 x_2位置,到标签 T a g Tag Tag 0的所有路径中,分数最大的路径是: x _ 00 , x _ 11 , x _ 20 x\_{00},x\_{11},x\_{20} x_00,x_11,x_20,因为前一个位置 x _ i − 1 x\_{i-1} x_i−1的标签是 T a g Tag Tag 1,因此 p _ 20 = 1 p\_{20}=1 p_20=1。
恭喜,我们又一次完成了这些枯燥的定义,下边我们来看看如何选择所有路径中得分最大的这一条吧,这里我们同样分成3步走来解释,首先计算截止到 x _ 0 x\_0 x_0位置,到各个标签的最大得分(上边的 a l p h a alpha alpha内容)是多少;截止到 x _ 1 x\_1 x_1位置,到各个标签的最大得分是多少;截止到 x _ 2 x\_2 x_2位置,到各个标签的最大得分是多少。
第1步,截止到 x _ 0 x\_0 x_0位置
当前位置 x _ 0 x\_0 x_0输入的发射分数为:KaTeX parse error: Undefined control sequence: \[ at position 13: emission\_0=\̲[̲x\_{00},x\_{01}…,因为这是序列的起始,显然截止到 x _ 0 x\_0 x_0位置有:KaTeX parse error: Undefined control sequence: \[ at position 10: alpha\_0=\̲[̲x\_{00},x\_{01}…
另外因为起始位置前边没有路径,这里我们使用-1来初始化:KaTeX parse error: Undefined control sequence: \[ at position 9: beta\_0=\̲[̲-1,-1\]
第2步,截止到 x _ 1 x\_1 x_1位置
当前步骤涉及到 x _ 0 x\_0 x_0向 x _ 1 x\_1 x_1位置的转移,在这个过程中, x _ 1 x\_1 x_1位置输入的发射分数为:KaTeX parse error: Undefined control sequence: \[ at position 13: emission\_1=\̲[̲x\_{10}, x\_{11…, 转移概率矩阵为: $ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] , 到前一个位置 , 到前一个位置 ,到前一个位置x_0 各标签的最大路径得分为 各标签的最大路径得分为 各标签的最大路径得分为alpha_0=[x_{00},x_{01}]$。
接下来按照2.5节同样的方式,我们expand一下 e m i s s i o n _ 1 emission\_1 emission_1 和 a l p h a _ 0 alpha\_0 alpha_0,力求通过矩阵计算的方式一次完成到当前位置 x _ 1 x\_1 x_1各个标签的所有路径中得分最大的路径分数 a l p h a _ 1 alpha\_1 alpha_1,具体如下:
KaTeX parse error: Undefined control sequence: \[ at position 21: …ion\_1 = \\left\̲[̲ \\begin{matrix…
KaTeX parse error: Undefined control sequence: \[ at position 18: …pha\_0 = \\left\̲[̲ \\begin{matrix…
然后我们来计算截止到 x _ 1 x\_1 x_1位置,到不同标签的每条路径的分数:
KaTeX parse error: Expected 'EOF', got '&' at position 28: …lign} scores &̲= alpha\_0+tran…
同样地,以第1行为例,第1行代表到当前位置 x _ 1 x\_1 x_1标签 T a g Tag Tag 0结尾的所有路径的得分,那么第1行中分数最大这一条路径,就是到当前位置 x _ 1 x\_1 x_1并且以 T a g Tag Tag 0结尾的所有路径中得分最大的路径。
因此,这样我们可以容易地算出到当前位置 x _ 1 x\_1 x_1的各个标签的最大路径分数 a l p h a _ 1 alpha\_1 alpha_1:
KaTeX parse error: Expected 'EOF', got '&' at position 30: …gn} alpha\_1 &̲= \[max(scores\…
显然从上边结果中,我们能够分析出到 x _ 1 x\_1 x_1位置各个标签的最大路径,例如到$Tag $ 0的路径有 x _ 00 + t _ 00 + x _ 10 x\_{00}+t\_{00}+x\_{10} x_00+t_00+x_10 和 $ x_{01}+t_{01}+x_{10} , 其中较大者就是我们想要的到 , 其中较大者就是我们想要的到 ,其中较大者就是我们想要的到x_1$位置 $Tag $ 0的最大路径。
这里不妨我们做个假设:
- x _ 00 + t _ 00 + x _ 10 < x _ 01 + t _ 01 + x _ 10 x\_{00}+t\_{00}+x\_{10} < x\_{01}+t\_{01}+x\_{10} x_00+t_00+x_10<x_01+t_01+x_10
- x _ 00 + t _ 10 + x _ 11 > x _ 01 + t _ 11 + x _ 11 x\_{00}+t\_{10}+x\_{11} > x\_{01}+t\_{11}+x\_{11} x_00+t_10+x_11>x_01+t_11+x_11
因此,我们可以获得 x _ 1 x\_1 x_1位置的索引KaTeX parse error: Undefined control sequence: \[ at position 9: beta\_1=\̲[̲1,0\],这代表在 x _ 1 x\_1 x_1位置,到标签 T a g Tag Tag 0的最大路径的前一个位置 x _ i − 1 x\_{i-1} x_i−1的标签是 T a g Tag Tag 1, 到标签 T a g Tag Tag 1的最大路径的前一个位置 x _ i − 1 x\_{i-1} x_i−1的标签是 T a g Tag Tag 0。
第3步,截止到 x _ 2 x\_2 x_2位置
我们再来看下 x _ 2 x\_2 x_2位置的一些输入信息, x _ 2 x\_2 x_2位置输入的发射分数为:KaTeX parse error: Undefined control sequence: \[ at position 13: emission\_2=\̲[̲x\_{20}, x\_{21…, 转移概率矩阵为: $ trans = \left[ \begin{matrix} t_{00} & t_{01}\ t_{10} & t_{11} \end{matrix} \right] , 前一个位置 , 前一个位置 ,前一个位置x_1 各标签的路径累计和 : 各标签的路径累计和: 各标签的路径累计和:alpha_1=[max(x_{00}+t_{00}+x_{10}, x_{01}+t_{01}+x_{10}), max(x_{00}+t_{10}+x_{11}, x_{01}+t_{11}+x_{11})]$。
接下来继续expand一下 e m i s s i o n _ 2 emission\_2 emission_2 和 a l p h a _ 1 alpha\_1 alpha_1,力求通过矩阵计算的方式一次完成当前位置 x _ 2 x\_2 x_2各个标签的路径累计 a l p h a _ 2 alpha\_2 alpha_2,具体如下:
KaTeX parse error: Undefined control sequence: \[ at position 21: …ion\_2 = \\left\̲[̲ \\begin{matrix…
KaTeX parse error: Undefined control sequence: \[ at position 18: …pha\_1 = \\left\̲[̲ \\begin{matrix…
然后我们来计算截止到 x _ 2 x\_2 x_2位置,到不同标签的每条路径的分数:
KaTeX parse error: Expected 'EOF', got '&' at position 28: …lign} scores &̲= alpha\_1+tran…
因此,这样我们可以容易地算出到当前位置 x _ 2 x\_2 x_2的各个标签的最大路径分数 a l p h a _ 2 alpha\_2 alpha_2:
KaTeX parse error: Expected 'EOF', got '&' at position 30: …gn} alpha\_1 &̲= \[max(scores\…
这里我不妨再假设:
-
m a x ( x _ 00 + t _ 00 + x _ 10 , x _ 01 + t _ 01 + x _ 10 ) + t _ 00 + x _ 20 > m a x ( x _ 00 + t _ 10 + x _ 11 , x _ 01 + t _ 11 + x _ 11 ) + t _ 01 + x _ 20 ) max(x\_{00}+t\_{00}+x\_{10}, x\_{01}+t\_{01}+x\_{10}) +t\_{00}+x\_{20} > max(x\_{00}+t\_{10}+x\_{11}, x\_{01}+t\_{11}+x\_{11})+t\_{01}+x\_{20}) max(x_00+t_00+x_10,x_01+t_01+x_10)+t_00+x_20>max(x_00+t_10+x_11,x_01+t_11+x_11)+t_01+x_20)
-
m a x ( x _ 00 + t _ 00 + x _ 10 , x _ 01 + t _ 01 + x _ 10 ) + t _ 10 + x _ 21 < m a x ( x _ 00 + t _ 10 + x _ 11 , x _ 01 + t _ 11 + x _ 11 ) + t _ 11 + x _ 21 ) max(x\_{00}+t\_{00}+x\_{10}, x\_{01}+t\_{01}+x\_{10})+t\_{10}+x\_{21} < max(x\_{00}+t\_{10}+x\_{11}, x\_{01}+t\_{11}+x\_{11}) +t\_{11}+x\_{21} ) max(x_00+t_00+x_10,x_01+t_01+x_10)+t_10+x_21<max(x_00+t_10+x_11,x_01+t_11+x_11)+t_11+x_21)
上一步我们曾假设:
- x _ 00 + t _ 00 + x _ 10 < x _ 01 + t _ 01 + x _ 10 x\_{00}+t\_{00}+x\_{10} < x\_{01}+t\_{01}+x\_{10} x_00+t_00+x_10<x_01+t_01+x_10
- x _ 00 + t _ 10 + x _ 11 > x _ 01 + t _ 11 + x _ 11 x\_{00}+t\_{10}+x\_{11} > x\_{01}+t\_{11}+x\_{11} x_00+t_10+x_11>x_01+t_11+x_11
因此有:
- x _ 01 + t _ 01 + x _ 10 + t _ 01 + x _ 10 < x _ 00 + t _ 10 + x _ 11 + t _ 01 + x _ 20 x\_{01}+t\_{01}+x\_{10}+t\_{01}+x\_{10} < x\_{00}+t\_{10}+x\_{11}+t\_{01}+x\_{20} x_01+t_01+x_10+t_01+x_10<x_00+t_10+x_11+t_01+x_20
- x _ 01 + t _ 01 + x _ 10 + t _ 10 + x _ 21 > x _ 00 + t _ 10 + x _ 11 + t _ 11 + x _ 21 x\_{01}+t\_{01}+x\_{10}+t\_{10}+x\_{21} > x\_{00}+t\_{10}+x\_{11}+t\_{11}+x\_{21} x_01+t_01+x_10+t_10+x_21>x_00+t_10+x_11+t_11+x_21
所以 x _ 2 x\_2 x_2位置的索引:KaTeX parse error: Undefined control sequence: \[ at position 11: beta\_2 = \̲[̲1,0\]
此时:KaTeX parse error: Undefined control sequence: \[ at position 10: alpha\_1=\̲[̲x\_{00}+t\_{10}…
在图7中橘色路径分数最高,其对应的是 x _ 00 + t _ 10 + x _ 11 + t _ 01 + x _ 20 x\_{00}+t\_{10}+x\_{11}+t\_{01}+x\_{20} x_00+t_10+x_11+t_01+x_20,因此再假设:
x _ 00 + t _ 10 + x _ 11 + t _ 01 + x _ 20 > x _ 01 + t _ 01 + x _ 10 + t _ 10 + x _ 21 x\_{00}+t\_{10}+x\_{11}+t\_{01}+x\_{20} > x\_{01}+t\_{01}+x\_{10}+t\_{10}+x\_{21} x_00+t_10+x_11+t_01+x_20>x_01+t_01+x_10+t_10+x_21
这其实代表在 x _ 2 x\_2 x_2位置的所有标签对应的最大路径中, T a g Tag Tag 0 对应的那条路径是最大的,这条路径也是全局所有路径中分数最大的那一条,是我们要解析出的期望路径。
第4步,开始解码标签序列
到现在位置,我们通过 b e t a _ 0 beta\_0 beta_0记录下了最大路径上的节点,接下来我们可以通过回溯来找出全局所有路径中的最大路径。
首先,在 x _ 2 x\_2 x_2位置所有标签对应的最大路径中, T a g Tag Tag 0 对应的路径分数最大。因此 x _ 2 x\_2 x_2位置对应的标签就是 T a g Tag Tag 0。
然后,KaTeX parse error: Undefined control sequence: \[ at position 11: beta\_2 = \̲[̲1,0\],因此 x _ 2 x\_2 x_2位置解析出的标签 T a g Tag Tag 0,对应的上一位置 x _ 1 x\_1 x_1的标签是 T a g Tag Tag 1。
接下来,KaTeX parse error: Undefined control sequence: \[ at position 9: beta\_1=\̲[̲1,0\],因此 x _ 1 x\_1 x_1位置解析出的标签 T a g Tag Tag 1,对应的上一位置 x _ 0 x\_0 x_0的标签是 T a g Tag Tag 0。
最后,KaTeX parse error: Undefined control sequence: \[ at position 9: beta\_0=\̲[̲-1,-1\],当解析到这一步的时候,反回的标签肯定是-1,因此这个回溯过程也就结束了。
当回溯完成之后,将解析出的结果倒序排序,就是我们期望的最大路径。以图7为例,该路径就是 T a g Tag Tag 0 --> T a g Tag Tag 1 --> T a g Tag Tag 0。
3. PLM Fine-tuning预训练的模型
3.1 目前前沿方法
-
Transformer-CRF模型:基于Transformers的神经网络结构和条件随机场模型的联合训练,通过提取输入的上下文信息、全局概率建模,结合现有的BERT和RoBERTa预训练模型,在多语种的命名实体识别任务中有很好的表现。
-
Pre-trained Language Model Fine-tuning (PLM Fine-tuning):该方法是基于预训练模型和微调技术的思想,利用预训练的模型(如BERT、RoBERTa等)作为初始参数,通过在命名实体识别的数据集上进行微调,来提升NER的性能。它可以在少量标注数据上快速训练,并在各种语言和领域中展现出优良的泛化能力。
-
Neural Architecture Search (NAS):利用神经网络搜索算法和强化学习,生成NN结构,并进行自动化架构搜索。NAS可以使模型具有更好的鲁棒性和泛化性能,并在不使用任何人工特征编码的情况下提高命名实体识别的准确性。
这些算法常用于实际应用中,并取得了良好的效果。当然,还有很多其他的NER算法,如模板匹配、CRF、SVM等,每种算法都有自己的优缺点,需要根据具体场景进行选择和组合。
3.2 小样本下NER
针对小样本问题,可以使用迁移学习或元学习等技术来解决。迁移学习是指将预先训练好的模型应用于新任务中,从而将新任务的训练时间缩短,但前提是预训练模型和待解决的任务有一定的相关性。元学习则是一种针对小样本学习问题的方法,它能够通过学习如何学习来提高模型在少量样本的情况下的泛化能力。
针对小样本NER问题,下面介绍两种常用的小样本模型:
-
Few-shot learning模型:该模型是一种基于元学习的模型,它可以用较少的数据进行训练,同时在新领域中进行良好的泛化,具有很强的适应性。Few-shot learning的主要思想是利用少量标注数据来训练一个编码器,通过训练来学习具有较好泛化性能的模型。在NER任务中,通过将少量文本做为一个任务,来进行训练,该模型可以在稀缺标注数据的情况下,识别新类别的命名实体。
-
Adaptive Span模型:该模型可以自适应地在输入序列中发现实体边界,从而进一步提高命名实体识别的性能。它可以利用现有的NER模型和表示学习方法,在少量数据情况下快速训练,并在大规模未标记的数据上表现优秀。Adaptive Span模型实现了端到端的自适应边界预测,它通过动态地选择每个输入序列中的子区间,来预测给定实体类别的标签。
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









