






一、数据加载
问题:Dataset和Dataloader做了什么
回答:
①首先我们要对数据进行获取,这里分为图片数据和对应的JSON数据。遍历所有图片数据的地址,按照一定顺序进行排序。再读取JSON地址,保存其中的标签项(label)的值。
② Dataset中主要是有init,getitem,len这三个方法。
init方法主要是保存,需要放到Dataset中的数据,一般是图片路径,标签,图片的变换方法。
getitem方法主要是对在init中拿到的数据进行进一步的处理。包括通过路径读取图片信息,根据图片的变换方法变化图片,对标签进行处理。
这里值得注意的是对标签进行处理,之前的文章已经说了,我们将这次的图像识别理解为一个定长字符的分类问题,所以对于不同长度的字符我们要进行扩容。主要进行原本字符+(定长-原本长)*10。就把不定长的字符,变成定长字符,补充位值为10。最后将制作好的图片数据和标签return就行了。
③Dataloader是一个匹配dataset的组装器,它可以组装数据,方法,batchsize,是否打乱,几个线程读取数据等信息。
最核心和就是支撑dataset,并且切分数据成规定的batchsize。
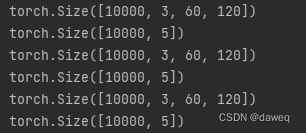
这里可以看到组装好的数据,假设我们一共有30000个数据,Dataloader将数据每次切分10000个进行输出,每一张图片的数据是601203的大小(由我们图片变换方法决定)。标签也是对应的5个大小。每次我们在执行训练或者测试代码的时候,都会通过一个特殊的for循环,从dataloader中put出一个数据,最后依次跑完所有程序。
这里可以值得说的是,我们整个深度学习其实本质就是对不同大小,维度,通道的数据进行特殊的被验证过有效的矩阵变换,这里面根据我们用的方法的不同,矩阵会增大,缩小,叠加,映射,转置等等,想要学透,最好就是明白每一步矩阵是在做什么变换,这对于后面学习网络的构建是很关键的。
二、训练网络是什么
提问:我们用的什么网络,它在Python中是怎么调用的。
回答:我们这里以resnet18网络举例,我们在Python采用得是预训练模型resnet18。当然我们也可以自己写出来resnet18,但是我们自己的数据量太小了,网络的参数又太多了所以我们要使用预训练模型,再根据我们的实际情况,对模型进行训练才能取得更好的效果。当然这里我也不是很清楚预训练模型具体好在哪,这里只是泛泛的谈一下,具体我们还是看怎么应用模型的。
这里有很多问题,我们一一来看。
①首先第一个问题就是,根据resnet18的网络结构,它对于输入数据的大小是有要求的(224*224)。但是我们输入不同大小的数据,依然能进行后续的网络操作,这是为什么呢?
这里首先要直到的是resnet18网络它实际上经过以连续的卷积层,再通过池化层,在通过线形层。这里的连续卷积层其实最后达成的效果是32倍下采样,它将224x224x3的数据最后采样为7x7x512的数据,最后经过平均池化层,变成1x1x512的数据,在经过线形层。
我们可以想象如果我们是用32323的数据,最后下采样后,是1x1x512的数据,最后经过平均池化层还是1x1x512,所以它依然可以使用这样的网络结构。所以不论我们输入什么样的输入大小,最后都会变成axbx512大小的图片,最后经过自适应平均池化层,就会变成1x1x*512。
这里又引申出一个问题,如果我输入图片的大小不能是32的整数倍,那么会对网络的性能影响多少呢?
这里我还没有搞明白具体的影响,但是我相信这个应该能解决这个问题了。
model_conv = models.resnet18(weights=torchvision.models.ResNet18_Weights.IMAGENET1K_V1)
model_conv.avgpool = nn.AdaptiveAvgPool2d(1)
②使用children函数是什么目的
model_conv = nn.Sequential(*list(model_conv.children())[:-1])
一个继承nn.module的model它包含一个叫做children()的函数,这个函数可以用来提取出model每一层的网络结构,在此基础上进行修改即可,修改方法如下(去除后一层)。
③具体的流程?
图片经过卷积层,卷积最后输出大小为512x1x1。将输出展平成一行数据也就是512x1的数据。然后再对应5个定长数据,分别通过5个线性层,这样就会输出对应的值。这样再经过常规的损失,梯度归零,反向传播,梯度更新就完成了一次训练。
三、训练函数
问题:训练的过程?
回答:首先要切换到训练模式,这是因为使用归一化和随机失活后,如果使用预测函数,那么就会影响预测,所以通过切换模式的方法避免了影响。从loader里put出数据,将数据放入model,得到结果后做交叉损失熵,梯度归零,反向传播,梯度更新。最后算出平均损失返回就行。
train_loss = train(train_loader, model, criterion, optimizer, epoch)
四、验证函数
问题:测试的过程?
回答:首先要切换到eval模式,从loader里put出数据,将数据放入model,得到结果后做交叉损失熵,这里不更新梯度,因为实在做测试。返回损失即可。再从验证数据的loader的dataset里直接获取图片标签,并且按照行保存。
val_loss = validate(val_loader, model, criterion)
val_label = [''.join(map(str, x)) for x in val_loader.dataset.img_label]
五、预测函数
问题:预测的过程?
回答:这里主要是预测标签,其实可以把预测和验证放在一起的,但是我们把它拆开是因为在测试的时候只需要预测标签就行了,不需要算损失熵。总的来说,前面和验证函数没什么差别,得到返回的概率后,使用concatenate方法把数据聚合在一起返回,再用vstack方法重新聚合和拆分,通过循环读出数据,并且把数据按照之前读取标签的格式拆分保存。
问题:预测过程中,预测的标签数据是怎么样排列的。
回答:这里主要是考虑model最后输出的格式,concatenate方法,vstack方法的数据处理模式。
首先model函数会输出c0-c4五类数据,每一个数据表示一个字符的所有可能性,也就是说比如c0是一个1*11的数据,表示一个字符的11种情况。
其实concatenate方法就是将数据进行列聚合,也就是把所有数据变成一行(axis = 1)。
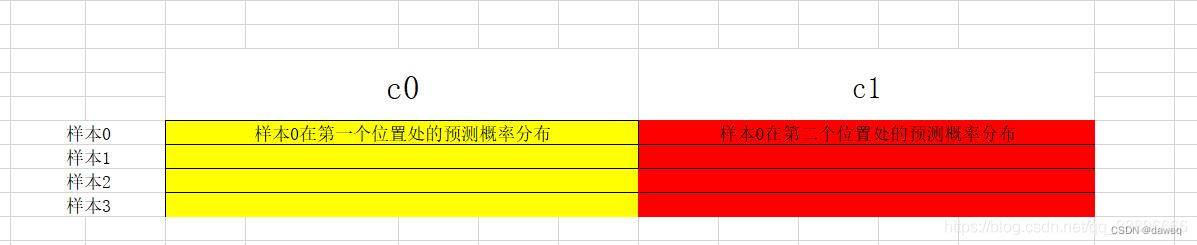
也就是对每一张图列聚合,如果来了第二张图就使用vstack方法进行行聚合,所以这样就拼好了所有的数据。行数表示不同的图片数据,每一列表示每一个位置的概率。在这里进行后返回这个数据。
然后对列进行处理,如果选取每一列前11行,就代表选取了所有数据的第一个位置的大小,对每一行都取最大值构成一组数据,再获取5组数据后,通过vstack方法进行行聚合。最后我们对数据进行转置,这样本身每一列表示一个图片数据,就变成了一行。然后按照每一行进行数据的组合保存就好了。这里会比较绕,需要多想想
图片参考:https://blog.csdn.net/qq_38896666/article/details/106432543

六、计算正确率和保存模型
问题:怎么计算正确率的
回答:比较两个numpy数据是否相同,相同就置位1,不同就置位0,然后最后取均值,这样就能得到概率了
问题:怎么保存模型,为什么要保存模型
回答:当每一次的验证损失小于之前的验证损失的时候才保存一次模型,保存模型是因为这是我们训练之后的模型了,再经过这个模型训练效果会比较好。















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









