






摘要
多任务学习(MTL)可以通过务之间的信息共享来提高学习效率。但现有的 MTL 模型经常以牺牲其他任务的性能为代价来改进某些任务,当任务相关性很复杂并且有时依赖于样本时,即与相应的单任务模型相比,多个任务无法同时改进,论文中称之为跷跷板现象。为了解决该问题,论文提出了的PLE的多任务学习模型。PLE将shared的部分分开,用于特定任务的训练。采用一种渐进式路由机制,逐步提取和分离更深层次的语义信息,提升联合学习的效果和多任务间的信息路由。
论文地址:Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations
相关工作
MTL模型:
最基本的方法是参数硬共享(shared-button),存在负迁移现象。
MOE模型提出了共享底层的expert,通过门控网络来连接不同的expert提取的特征。MMOE是在MOE的基础上,对每个任务有单独的门控网络来组合不同的expert。MRAN使用多头-自注意力机制去学习不同特征集的不同空间的表达。这三种模型的门控网络机制和注意力机制都是共享的,没有独享。
论文提出了CGC和PLE模型,分开共享和独享参数,避免参数互相影响。
视频推荐中的MTL排序系统:
MTL排序系统中,有多个目标用来建模用户行为,比如点击、分享和评论等。离线训练过程中,从离线log表中训练MTL模型。在线请求之后,排序模型输出每一个任务的预测值,然后基于加权乘法的排序模块通过组合函数将这些预测得分组合为最终得分,推荐top-k的视频给用户。加权乘法公式为:
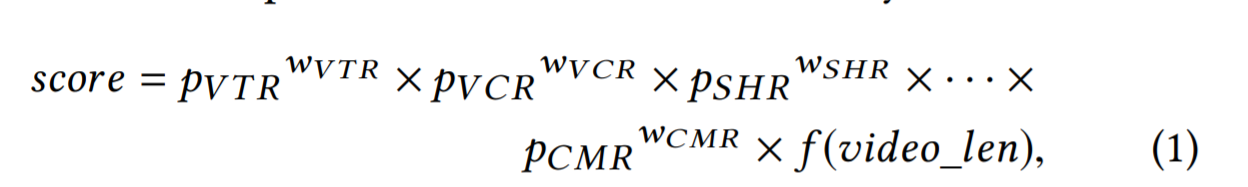
MTL中的跷跷板现象:
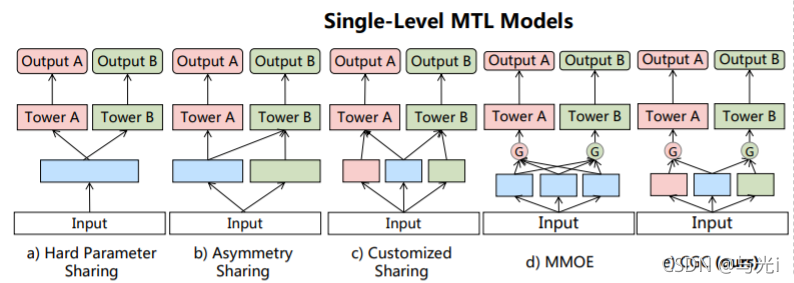
图1
图1(b)Asymmetry Sharing(不对称共享):不同任务的底层模块有各自对应的输出,但其中部分任务的输出会被其他任务所使用,而部分任务则使用自己独有的输出。哪部分任务使用其他任务的输出,则需要人为指定。
图1(C)Customized Sharing(自定义共享):不同任务的底层模块不仅有各自独立的输出,还有共享的输出。
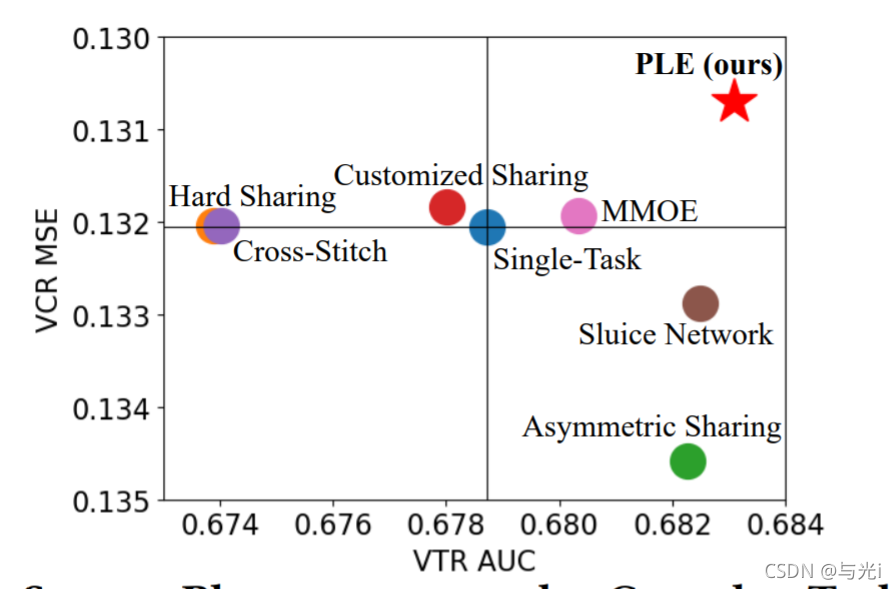
图2
由图2可知,硬参数共享和十字绣网络在VTR中存在显著的负转移,表现最差。通过创新共享机制来捕获非对称关系,非对称共享在VTR中取得显著改善,但在VCR中却表现出与水闸网络类似的显著退化。由于共享层和任务特定层的显式分离,自定义共享改进了VCR而不是单任务模型,但在VTR中仍然存在一些问题。MMOE在两个任务上都比单任务模型有所改进,但VCR的改进仅是有限的。
论文提出了PLE来解决跷跷板现象和负迁移问题。思想如下:1. 显式分离共享和独享的experts,来避免有害参数的干扰。2. 多层experts和门机制用来融合多个抽象表达。最后,使用了一种progressive separation routing去建模不同experts之间的interaction,实现更高效的知识传递。
网络结构
PLE模型使用了CGC模块,结合了多层门控机制。
CGC模块:
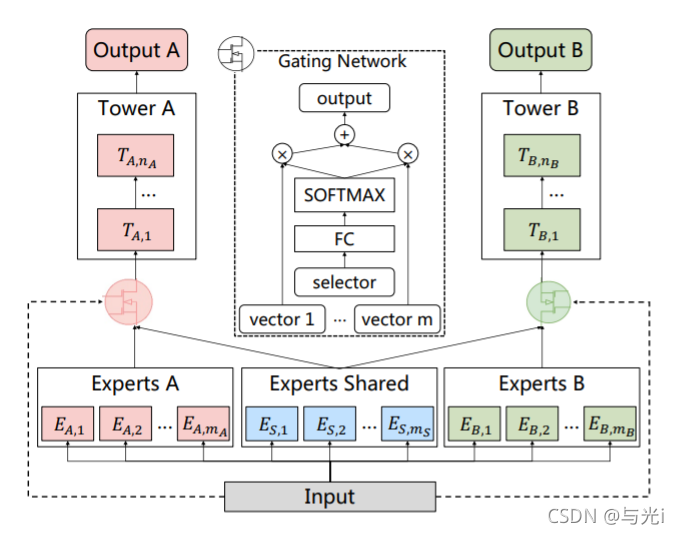
图3
如图3所示,在底层有许多expert模块,顶层有任务独享的tower模型。每一个expert模块都是由许多expert组成。tower的网络也可以是多层MLP,其深度和宽度也是超参数。CGC中共享的expert学习共享的pattern,任务独享的expert学习任务独享的知识。每一个tower网络吸收来自共享和独享的知识,也就是说,共享的expert被所有任务影响,独享的expert被任务独享的tower所影响。在CGC中,独享和共享的expert通过一个门网络来选择性的融合。门控网络是一个单层的FNN,激活函数为softmax,输入是计算向量加权和的选择器。
对比MMOE,CGC移除了任务tower网络与其他任务独享的expert之间的联系,可以使不同的tower网络专注于学习不同的知识。使用门网络去融合不同的expert的输出,CGC可以实现更加灵活的balance。
PLE layer:
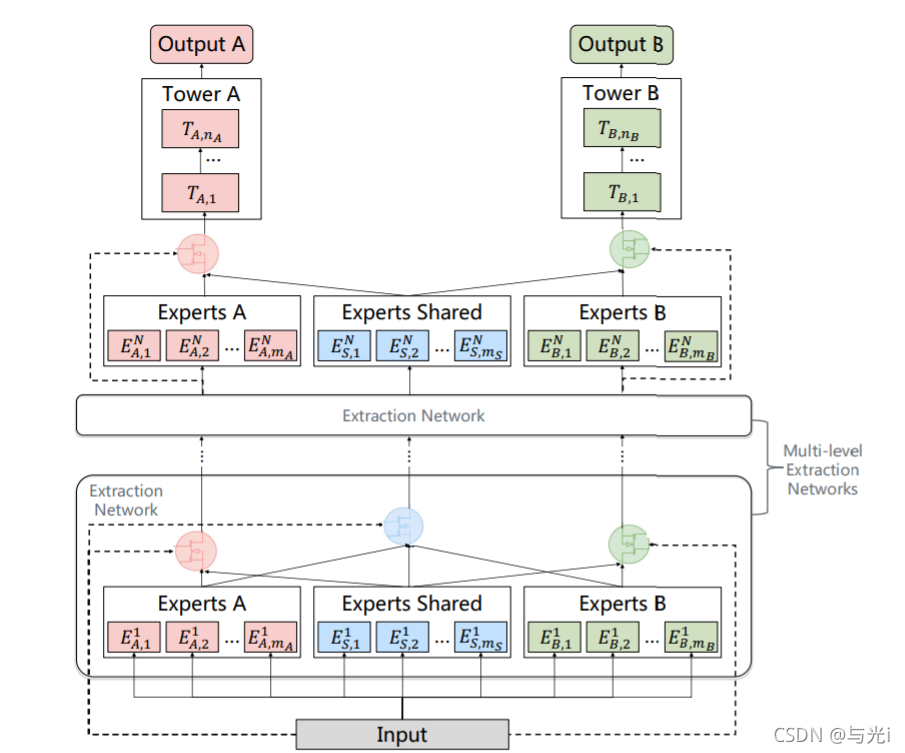
图4
通过使用门机制去结合共享和独享的expert的知识,传到下一层。PLE是在CGC基础上考虑了不同Expert的交互,可以看作是Customized Sharing和ML-MMOE的结合版本。
下层模块中增加了多层Extraction Network。在每一层Extraction Network,共享Experts不断吸收各自独有的Experts之间的信息,而任务独有的Experts则从共享Experts中吸收有用的信息,具体计算和CGC一样。
实验
线上ABtest:
论文在线上进行了4周的ABtest实验,主要优化目标是VCR和VTR,结果如下:
MTL模型比单任务模型效果更好;
CGC和PLE的效果均显著优于其他模型,PLE效果最好。
除了VCR和VTR,作者还引入了SHR(分享率)和CMR(评论率)两个任务到MTL框架中,比较了CGC和PLE的效果:
CGC和PLE在多任务学习中的效果均显著优于单任务模型;
CGC和PLE在超过两个子任务的多任务学习中,可以有效地避免seesaw phenomenon和负迁移;
PLE的效果优于CGC。
expert分析:
为了公平对比,作者采用了single-level的PLE和ML-MMoE,然后可视化了CGC、MMoE、PLE和ML-MMoE的expert的utilization,如图5所示。
图5

















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









