






在网上搜索了半天,没几个能把这个函数说明白的。在此记录下自己的理解。
软件并不像大脑一样,可以给出一个真正的随机数;软件中产生的随机数也是软件开发者依据一定的算法规则、并基于随机数生成器种子产生的随机数,所以严格意义上来说,这些随机数并不是类似我们脱口而出的、真正意义上的随机数。
但算法产生的随机数有类似于真实随机数的统计学特征,如均匀性、独立性等;是能满足我们的使用需求的,所以称它为伪随机数。
在实际工作中,第一次产生随机数列a后,如果第二次还想产生与a相同的随机数列该怎么办呢?这就是np.random.RandomState(n)函数。
前面说过,随机数是基于种子产生的。举个列子来理解种子:我们把随机数比喻成农作物,种子就是玉米粒、大豆粒、高粱粒。种下玉米粒后,一定长玉米苗,而不是大豆苗;种下大豆粒,一定长大豆苗。。。因此,在随机数中,如果种子相同,那么长出来的随机数也就相同。
np.random.RandomState(n)中的n就是种子,n可以是0、3、233、4444等任意值,只要n相同,长出来的随机数就相同,如下图代码所示:
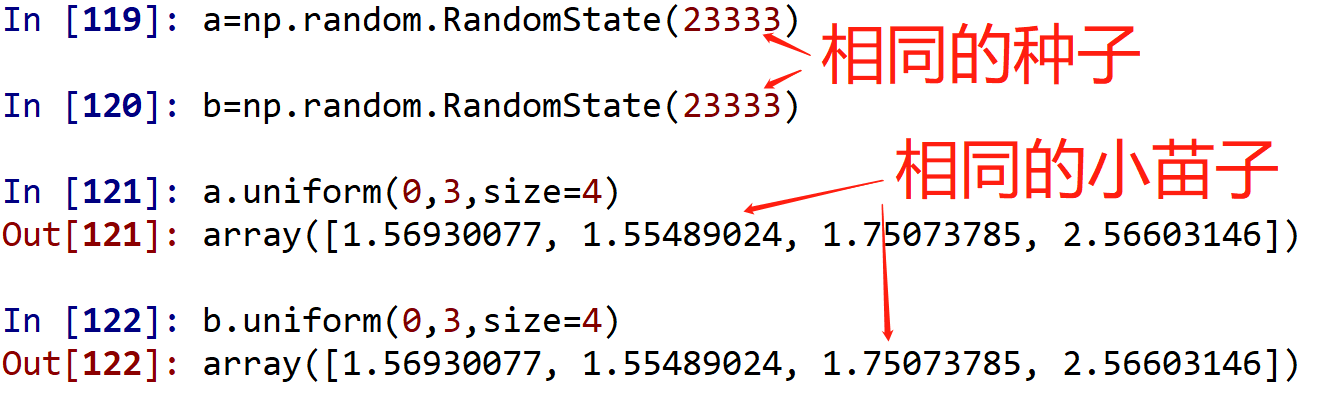
我们都知道,如今的玉米种子都是杂交种、一次性的,下次得买新的种子。随机数也有这个特点,具体看下面的代码:
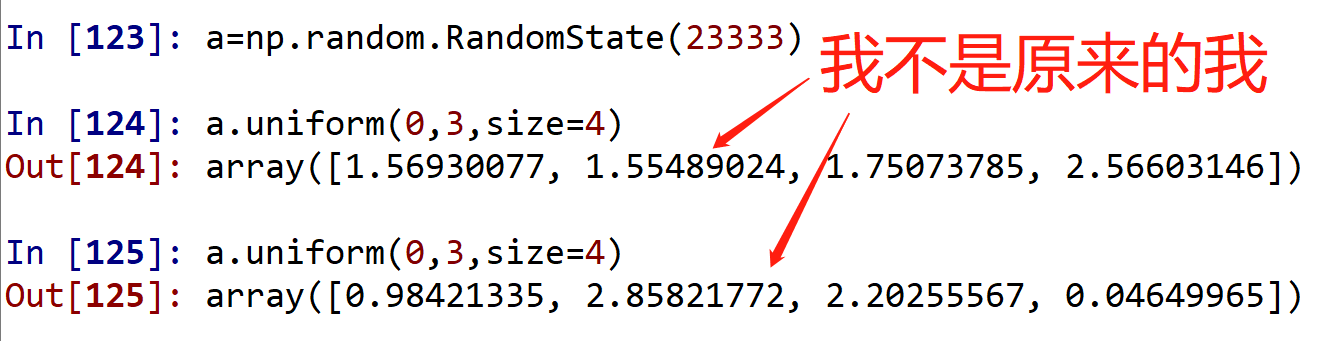
变量a是我们用种子“23333”种出来的苗子,它只能结一个玉米棒子,这个棒子就是第一次调用“a.uniform(0,3,size=4)”产生的玉米棒array([1.56930077, 1.55489024, 1.75073785, 2.56603146])。之后,不管我们再调用多少次变量a,它都长不出跟原来一模一样的棒子,所以是一次性的。
其原理是,我们每产生一个随机数,都是用的新种子;即上图中
数组array([1.56930077, 1.55489024, 1.75073785, 2.56603146])用的是“23333”这个种子,而
数组array([0.98421335, 2.85821772, 2.20255567, 0.04649965])用的是新种子,虽然我们没用键盘输入,但当键盘输入为空时,python会自定义给它一个新种子。















 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









