






Pandas 2.0正式版在4月3日已经发布了,以后我们pip install默认安装的就是2.0版了,Polars 是最近比较火的一个DataFrame 库,最近在kaggle上经常使用,所以这里我们将对比下 Pandas 1.5,Polars,Pandas 2.0 。看看在速度上 Pandas 2.0有没有优势。

Polars
Polars 是一个 Rust 和 Python 中的快速多线程 DataFrame 库/内存查询引擎。它使用 Apache Arrow作为内存模型在 Rust 中实现。它在2021年3月发布。
Polars的一些主要特点如下:
- 快速:Polars在处理大型数据集时非常高效。它使用Rust编写,利用Rust的内存安全和零成本抽象,可以在不牺牲性能的情况下处理大规模数据集。
- 可扩展:Polars支持并行化和分布式计算,因此可以处理非常大的数据集。它还具有可插拔的数据源接口,可以从不同的数据源读取和写入数据。
- 易于使用:Polars具有类似于Pandas的API,因此熟悉Pandas的用户可以很容易地开始使用Polars。它还具有完整的文档和示例,可帮助用户快速入门。
- 支持多种数据类型:Polars支持许多常见的数据类型,包括数字,布尔值,字符串和日期时间。它还支持类似于DataFrame的表格结构,可以进行列操作和过滤等操作。
Polars的一个最大好处是,它不仅有Python的包,Nodejs,Rust等也可以方便的进行继承使用,并且经过各方的验证,它的确要比Pandas1.x快很多。
Pandas 2.0
在之前的文章我们已经介绍了 Pandas 2.0,“它要快得多”(还不是稳定版本)。并且它也有了Apache Arrow的后端。
现在,他的正式版发布了,对于Pandas 2.0 的更新请看官网说明:
https://pandas.pydata.org/docs/dev/whatsnew/v2.0.0.html
下面我们就要开始进行简单的测试了,我们要测试这3个库的性能,所以需要使用一些比较大型的数据集。这里我们使用纽约出租车数据集。
简单ETL
从Data Talks Club下载csv数据集,NYC.gov下载parquet数据集。
!wget https://github.com/DataTalksClub/nyc-tlc-data/releases/download/yellow/yellow_tripdata_2021-01.csv.gz
!wget https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2021-01.parquet
还需要纽约市区域。
!wget https://s3.amazonaws.com/nyc-tlc/misc/taxi+_zone_lookup.csv
1、E 提取
把csv文件和parquet文件转换为DF,测试提取的性能。
下面是pandas的
def pd_read_csv(path, engine_pd,):
"""
Converting csv file into Pandas dataframe
"""
df= pd.read_csv(path, engine=engine_pd)
return df
def pd_read_parquet(path, ):
"""
Converting parquet file into Pandas dataframe
"""
df= pd.read_parquet(path,)
return df
这里是Polars的
def pl_read_csv(path, ):
"""
Converting csv file into Pandas dataframe
"""
df= pl.read_csv(path,)
return df
def pl_read_parquet(path, ):
"""
Converting parquet file into Pandas dataframe
"""
df= pl.read_parquet(path,)
return df
读取代码如下:
path1="yellow_tripdata_2021-01.csv.gz"
df_trips= pd_read_csv(path1, engine_pd)
path2="taxi+_zone_lookup.csv"
df_zone= pd_read_csv(path2, engine_pd)
path1="yellow_tripdata_2021-01.parquet"
df_trips= pd_read_parquet(path1,)
path2 = "taxi+_zone_lookup.csv"
df_zone = pd_read_csv(path2, engine_pd)
2、T 转换
为了测试,我们通过Pickup Id获取trip_distance的均值;
过滤查询性能所以获取以“East”结尾的区域。
Pandas代码:
def mean_test_speed_pd(df_pd):
"""
Getting Mean per PULocationID
"""
df_pd = df_pd[['PULocationID', 'trip_distance']]
df_pd["PULocationID_column"] = df_pd[['PULocationID']].astype(int)
df_pd=df_pd.groupby('PULocationID').mean()
return df_pd
def endwith_test_speed_pd(df_pd):
"""
Only getting Zones that end with East
"""
df_pd = df_pd[df_pd.Zone.str.endswith('East')]
return df_pd
Polars
def mean_test_speed_pl(df_pl):
"""
Getting Mean per PULocationID
"""
df_pl = df_pl[['PULocationID', 'trip_distance']].groupby('PULocationID').mean()
return df_pl
def endwith_test_speed_pd(df_pl):
"""
Only getting Zones that end with East
"""
df_pl = df_pl.filter(pl.col("Zone").str.ends_with('East'))
return df_pl
3、L 加载
将最终结果加载回parquet文件,可以测试写入性能:
pandas
def loading_into_parquet(df_pd, engine):
"""
Save dataframe in parquet
"""
df_pd.to_parquet(f'yellow_tripdata_2021-01_pd_v{pd.__version__}.parquet',engine)
polars
def loading_into_parquet(df_pl):
"""
Save dataframe in parquet
"""
df_pl.write_parquet(f'yellow_tripdata_2021-01_pl.parquet')
4、结果
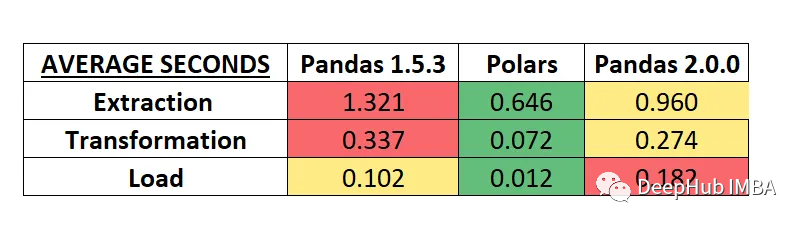
运行ETL流程后,根据每个过程的秒平均值,测试性能的最终结果如下表所示。

可以看到POLARS很棒

但是上面代码是不是有问题呢?
对,还记得我们在pandas2.0那篇文章中说过,read_csv获得Numpy数据类型,为read_parquet获得Pyarrow数据类型。而Polars中,当我们执行read_csv和read_parquet时,我们为所有列获得相同的数据类型。所以我们测试的并不准确。另外我们也没有比较比较RAM和CPU的使用情况,所以没有全方位的测试。
下面我们开始修复上面的问题,并添加RAM和CPU的使用情况,这样应该算是一个比较完善的测试了。
CPU和RAM分析
我们可以使用process.memory_info()检查每个函数之前、之后和之间的内存。而psutil.cpu_percent可以获得最近2秒内的CPU。所以就有了下面的装饰器:
import os
import psutil
def process_memory():
process = psutil.Process(os.getpid())
mem_info = process.memory_info()
return mem_info.rss
def process_cpu():
"""
Getting cpu_percent in last 2 seconds
"""
cpu_usage = psutil.cpu_percent(2)
return cpu_usage
# decorator function mem
def profile_mem(func):
def wrapper(*args, **kwargs):
mem_before = process_memory()
result = func(*args, **kwargs)
mem_after = process_memory()
print("Consumed memory: {:,}".format(
mem_before, mem_after, mem_after - mem_before))
return result
return wrapper
# decorator function cpu
def profile_cpu(func):
def wrapper(*args, **kwargs):
result = func(*args, **kwargs)
cpu_after = process_cpu()
print(f"Consumed cpu: {cpu_after}")
return result
return wrapper
装饰器调用方法如下图所示
完整测试结果
我们就直接来看结果了(每个测试都运行了三次):
parquet文件提取的新脚本,最终的时间结果与前面测试类似:
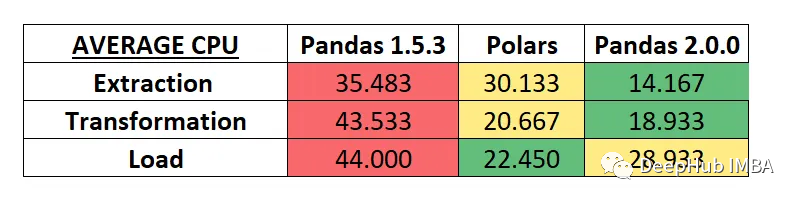
CPU结果
RAM的结果
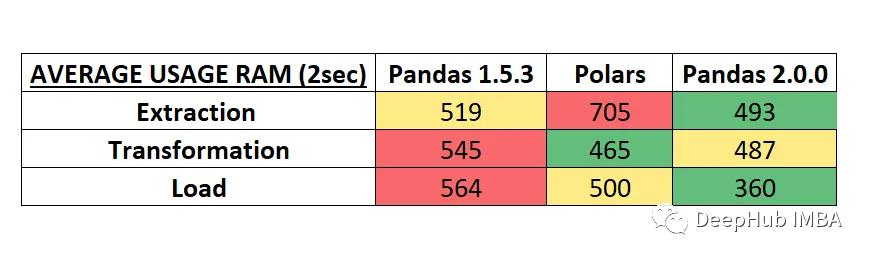
结果难以解释,但是可以说明rust的确内存占用高😂
但是我们看到,POLARS的确还是要快一些,如果在处理时间是一个非常重要的指标的时候可以试试POLARS(但是他的CPU占用高,说明如果比较慢的CPU也不一定能获得提高,还要具体测试),如果你不想学习POLARS的语法,那么Pandas 2.0应该是速度很快的一个折中的选择了。
如果你想自己测试,完整代码在这里:
https://avoid.overfit.cn/post/73c12c85ff124f9bb7947ac4d82316b8
作者:Luís Oliveira

















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









